 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcepts' Information Bottleneck Models
Feb 16, 2026Concept Bottleneck Models (CBMs) aim to deliver interpretable predictions by routing decisions through a human-understandable concept layer, yet they often suffer reduced accuracy and concept leakage that undermines faithfulness. We introduce an explicit Information Bottleneck regularizer on the concept layer that penalizes $I(X;C)$ while preserving task-relevant information in $I(C;Y)$, encouraging minimal-sufficient concept representations. We derive two practical variants (a variational objective and an entropy-based surrogate) and integrate them into standard CBM training without architectural changes or additional supervision. Evaluated across six CBM families and three benchmarks, the IB-regularized models consistently outperform their vanilla counterparts. Information-plane analyses further corroborate the intended behavior. These results indicate that enforcing a minimal-sufficient concept bottleneck improves both predictive performance and the reliability of concept-level interventions. The proposed regularizer offers a theoretic-grounded, architecture-agnostic path to more faithful and intervenable CBMs, resolving prior evaluation inconsistencies by aligning training protocols and demonstrating robust gains across model families and datasets.
SPoT: Subpixel Placement of Tokens in Vision Transformers
Jul 02, 2025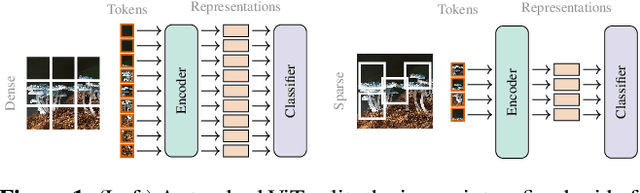
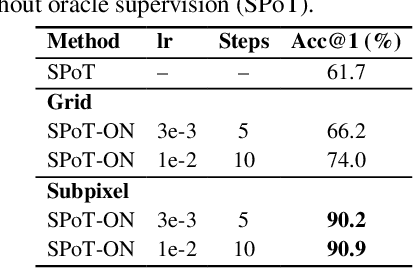
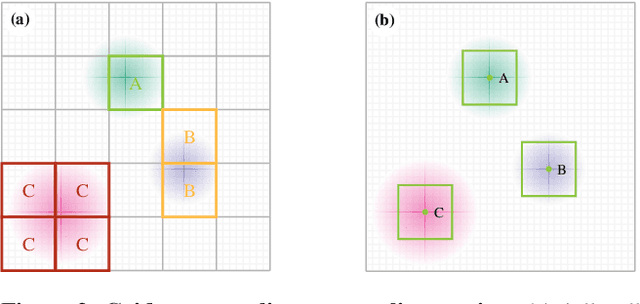
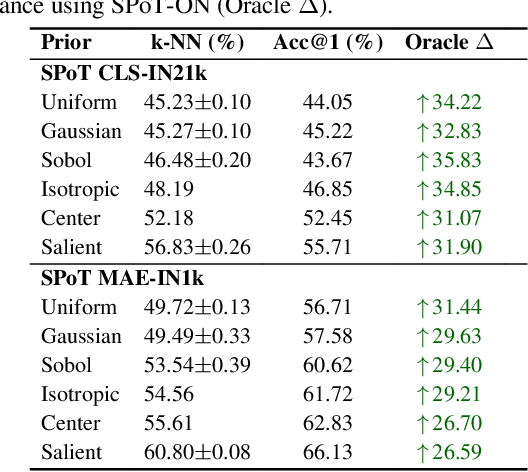
Vision Transformers naturally accommodate sparsity, yet standard tokenization methods confine features to discrete patch grids. This constraint prevents models from fully exploiting sparse regimes, forcing awkward compromises. We propose Subpixel Placement of Tokens (SPoT), a novel tokenization strategy that positions tokens continuously within images, effectively sidestepping grid-based limitations. With our proposed oracle-guided search, we uncover substantial performance gains achievable with ideal subpixel token positioning, drastically reducing the number of tokens necessary for accurate predictions during inference. SPoT provides a new direction for flexible, efficient, and interpretable ViT architectures, redefining sparsity as a strategic advantage rather than an imposed limitation.
Mapping the Mind of an Instruction-based Image Editing using SMILE
Dec 20, 2024Despite recent advancements in Instruct-based Image Editing models for generating high-quality images, they are known as black boxes and a significant barrier to transparency and user trust. To solve this issue, we introduce SMILE (Statistical Model-agnostic Interpretability with Local Explanations), a novel model-agnostic for localized interpretability that provides a visual heatmap to clarify the textual elements' influence on image-generating models. We applied our method to various Instruction-based Image Editing models like Pix2Pix, Image2Image-turbo and Diffusers-Inpaint and showed how our model can improve interpretability and reliability. Also, we use stability, accuracy, fidelity, and consistency metrics to evaluate our method. These findings indicate the exciting potential of model-agnostic interpretability for reliability and trustworthiness in critical applications such as healthcare and autonomous driving while encouraging additional investigation into the significance of interpretability in enhancing dependable image editing models.
Representation Learning via Consistent Assignment of Views over Random Partitions
Oct 27, 2023



We present Consistent Assignment of Views over Random Partitions (CARP), a self-supervised clustering method for representation learning of visual features. CARP learns prototypes in an end-to-end online fashion using gradient descent without additional non-differentiable modules to solve the cluster assignment problem. CARP optimizes a new pretext task based on random partitions of prototypes that regularizes the model and enforces consistency between views' assignments. Additionally, our method improves training stability and prevents collapsed solutions in joint-embedding training. Through an extensive evaluation, we demonstrate that CARP's representations are suitable for learning downstream tasks. We evaluate CARP's representations capabilities in 17 datasets across many standard protocols, including linear evaluation, few-shot classification, k-NN, k-means, image retrieval, and copy detection. We compare CARP performance to 11 existing self-supervised methods. We extensively ablate our method and demonstrate that our proposed random partition pretext task improves the quality of the learned representations by devising multiple random classification tasks. In transfer learning tasks, CARP achieves the best performance on average against many SSL methods trained for a longer time.
Self-supervised Learning of Contextualized Local Visual Embeddings
Oct 04, 2023We present Contextualized Local Visual Embeddings (CLoVE), a self-supervised convolutional-based method that learns representations suited for dense prediction tasks. CLoVE deviates from current methods and optimizes a single loss function that operates at the level of contextualized local embeddings learned from output feature maps of convolution neural network (CNN) encoders. To learn contextualized embeddings, CLoVE proposes a normalized mult-head self-attention layer that combines local features from different parts of an image based on similarity. We extensively benchmark CLoVE's pre-trained representations on multiple datasets. CLoVE reaches state-of-the-art performance for CNN-based architectures in 4 dense prediction downstream tasks, including object detection, instance segmentation, keypoint detection, and dense pose estimation.
* Pre-print. 4th Visual Inductive Priors for Data-Efficient Deep Learning Workshop ICCV 2023. Code at https://github.com/sthalles/CLoVE
SelfGraphVQA: A Self-Supervised Graph Neural Network for Scene-based Question Answering
Oct 03, 2023



The intersection of vision and language is of major interest due to the increased focus on seamless integration between recognition and reasoning. Scene graphs (SGs) have emerged as a useful tool for multimodal image analysis, showing impressive performance in tasks such as Visual Question Answering (VQA). In this work, we demonstrate that despite the effectiveness of scene graphs in VQA tasks, current methods that utilize idealized annotated scene graphs struggle to generalize when using predicted scene graphs extracted from images. To address this issue, we introduce the SelfGraphVQA framework. Our approach extracts a scene graph from an input image using a pre-trained scene graph generator and employs semantically-preserving augmentation with self-supervised techniques. This method improves the utilization of graph representations in VQA tasks by circumventing the need for costly and potentially biased annotated data. By creating alternative views of the extracted graphs through image augmentations, we can learn joint embeddings by optimizing the informational content in their representations using an un-normalized contrastive approach. As we work with SGs, we experiment with three distinct maximization strategies: node-wise, graph-wise, and permutation-equivariant regularization. We empirically showcase the effectiveness of the extracted scene graph for VQA and demonstrate that these approaches enhance overall performance by highlighting the significance of visual information. This offers a more practical solution for VQA tasks that rely on SGs for complex reasoning questions.
Global and Local Features through Gaussian Mixture Models on Image Semantic Segmentation
Jul 19, 2022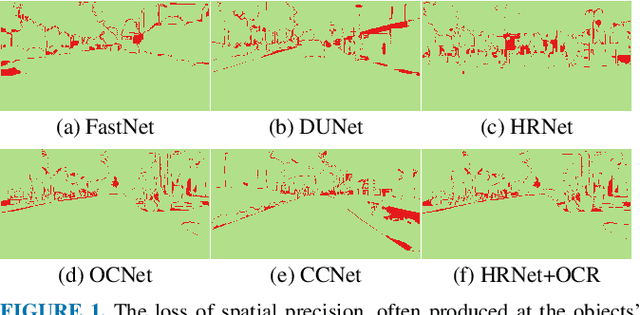

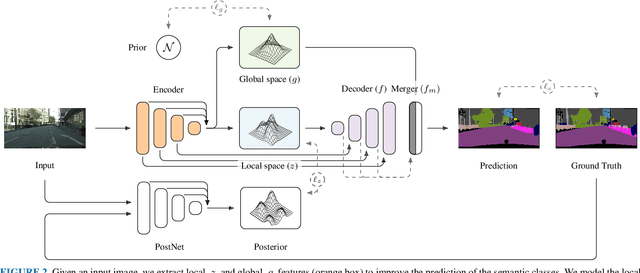
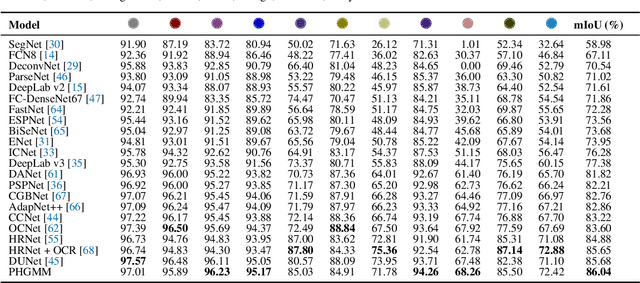
The semantic segmentation task aims at dense classification at the pixel-wise level. Deep models exhibited progress in tackling this task. However, one remaining problem with these approaches is the loss of spatial precision, often produced at the segmented objects' boundaries. Our proposed model addresses this problem by providing an internal structure for the feature representations while extracting a global representation that supports the former. To fit the internal structure, during training, we predict a Gaussian Mixture Model from the data, which, merged with the skip connections and the decoding stage, helps avoid wrong inductive biases. Furthermore, our results show that we can improve semantic segmentation by providing both learning representations (global and local) with a clustering behavior and combining them. Finally, we present results demonstrating our advances in Cityscapes and Synthia datasets.
RepFair-GAN: Mitigating Representation Bias in GANs Using Gradient Clipping
Jul 13, 2022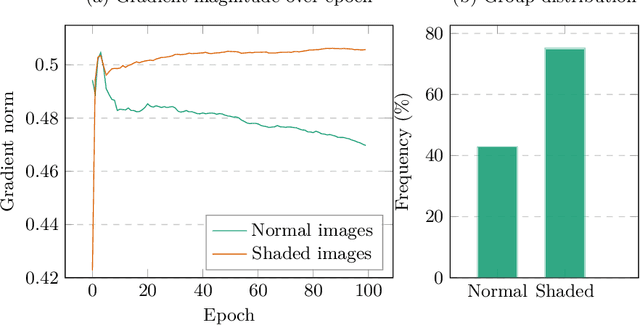

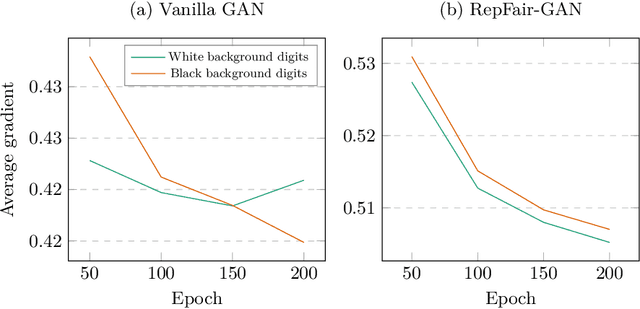
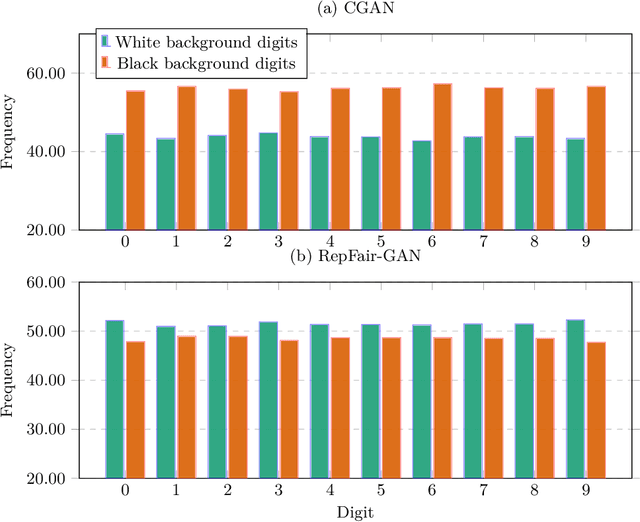
Fairness has become an essential problem in many domains of Machine Learning (ML), such as classification, natural language processing, and Generative Adversarial Networks (GANs). In this research effort, we study the unfairness of GANs. We formally define a new fairness notion for generative models in terms of the distribution of generated samples sharing the same protected attributes (gender, race, etc.). The defined fairness notion (representational fairness) requires the distribution of the sensitive attributes at the test time to be uniform, and, in particular for GAN model, we show that this fairness notion is violated even when the dataset contains equally represented groups, i.e., the generator favors generating one group of samples over the others at the test time. In this work, we shed light on the source of this representation bias in GANs along with a straightforward method to overcome this problem. We first show on two widely used datasets (MNIST, SVHN) that when the norm of the gradient of one group is more important than the other during the discriminator's training, the generator favours sampling data from one group more than the other at test time. We then show that controlling the groups' gradient norm by performing group-wise gradient norm clipping in the discriminator during the training leads to a more fair data generation in terms of representational fairness compared to existing models while preserving the quality of generated samples.
A deep learning approach to halo merger tree construction
May 31, 2022
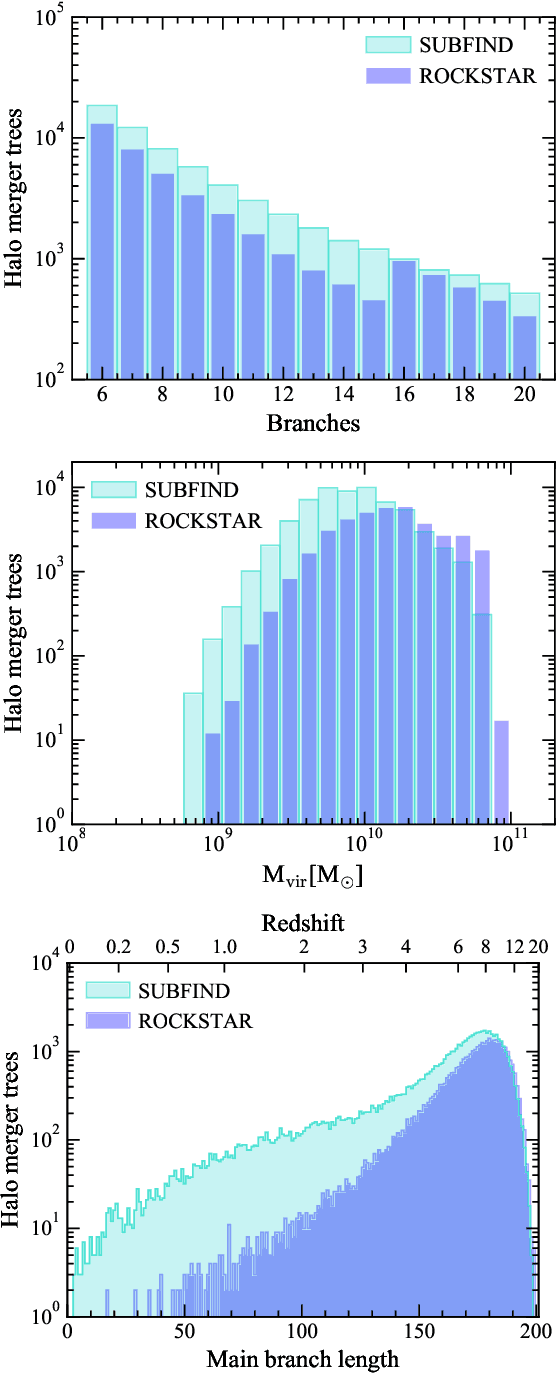


A key ingredient for semi-analytic models (SAMs) of galaxy formation is the mass assembly history of haloes, encoded in a tree structure. The most commonly used method to construct halo merger histories is based on the outcomes of high-resolution, computationally intensive N-body simulations. We show that machine learning (ML) techniques, in particular Generative Adversarial Networks (GANs), are a promising new tool to tackle this problem with a modest computational cost and retaining the best features of merger trees from simulations. We train our GAN model with a limited sample of merger trees from the EAGLE simulation suite, constructed using two halo finders-tree builder algorithms: SUBFIND-D-TREES and ROCKSTAR-ConsistentTrees. Our GAN model successfully learns to generate well-constructed merger tree structures with high temporal resolution, and to reproduce the statistical features of the sample of merger trees used for training, when considering up to three variables in the training process. These inputs, whose representations are also learned by our GAN model, are mass of the halo progenitors and the final descendant, progenitor type (main halo or satellite) and distance of a progenitor to that in the main branch. The inclusion of the latter two inputs greatly improves the final learned representation of the halo mass growth history, especially for SUBFIND-like ML trees. When comparing equally sized samples of ML merger trees with those of the EAGLE simulation, we find better agreement for SUBFIND-like ML trees. Finally, our GAN-based framework can be utilised to construct merger histories of low and intermediate mass haloes, the most abundant in cosmological simulations.
Representation Learning via Consistent Assignment of Views to Clusters
Dec 31, 2021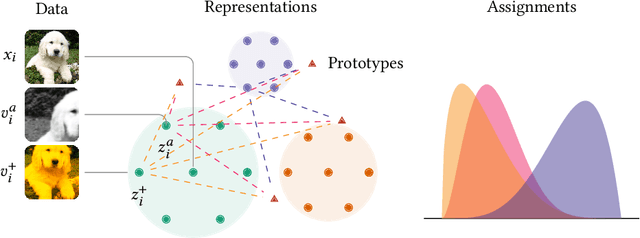
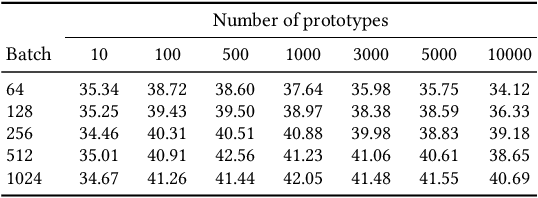
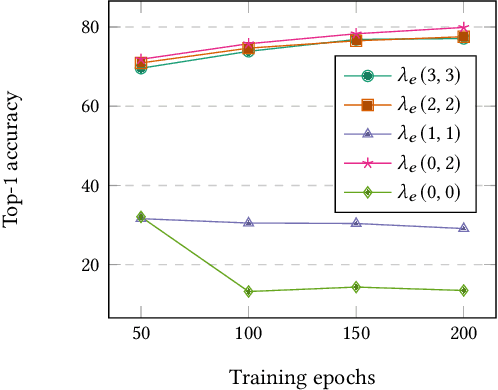
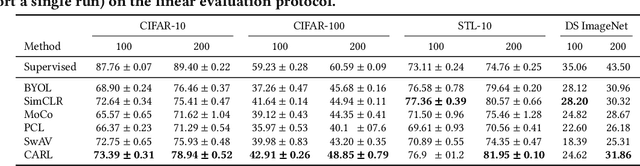
We introduce Consistent Assignment for Representation Learning (CARL), an unsupervised learning method to learn visual representations by combining ideas from self-supervised contrastive learning and deep clustering. By viewing contrastive learning from a clustering perspective, CARL learns unsupervised representations by learning a set of general prototypes that serve as energy anchors to enforce different views of a given image to be assigned to the same prototype. Unlike contemporary work on contrastive learning with deep clustering, CARL proposes to learn the set of general prototypes in an online fashion, using gradient descent without the necessity of using non-differentiable algorithms or K-Means to solve the cluster assignment problem. CARL surpasses its competitors in many representations learning benchmarks, including linear evaluation, semi-supervised learning, and transfer learning.