 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal and Local Features through Gaussian Mixture Models on Image Semantic Segmentation
Jul 19, 2022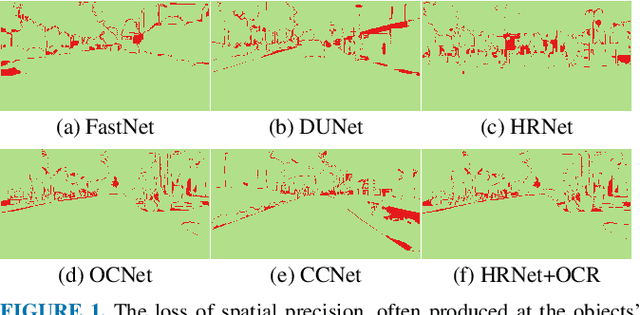

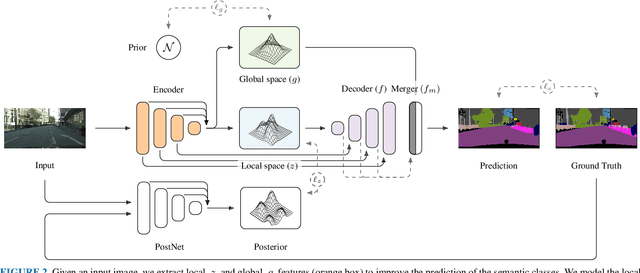
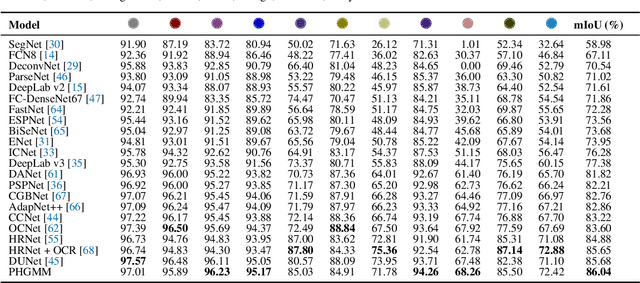
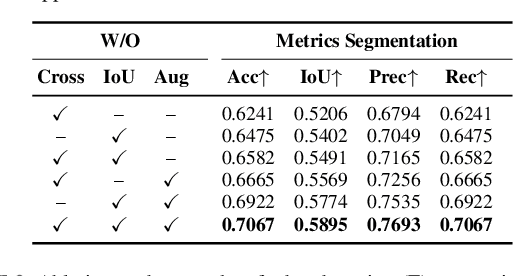
The semantic segmentation task aims at dense classification at the pixel-wise level. Deep models exhibited progress in tackling this task. However, one remaining problem with these approaches is the loss of spatial precision, often produced at the segmented objects' boundaries. Our proposed model addresses this problem by providing an internal structure for the feature representations while extracting a global representation that supports the former. To fit the internal structure, during training, we predict a Gaussian Mixture Model from the data, which, merged with the skip connections and the decoding stage, helps avoid wrong inductive biases. Furthermore, our results show that we can improve semantic segmentation by providing both learning representations (global and local) with a clustering behavior and combining them. Finally, we present results demonstrating our advances in Cityscapes and Synthia datasets.
Empirical Study of Multi-Task Hourglass Model for Semantic Segmentation Task
May 28, 2021

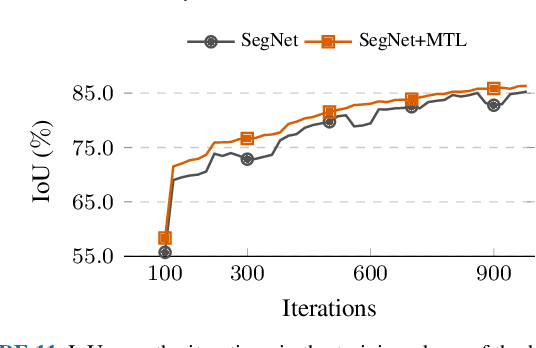
The semantic segmentation (SS) task aims to create a dense classification by labeling at the pixel level each object present on images. Convolutional neural network (CNN) approaches have been widely used, and exhibited the best results in this task. However, the loss of spatial precision on the results is a main drawback that has not been solved. In this work, we propose to use a multi-task approach by complementing the semantic segmentation task with edge detection, semantic contour, and distance transform tasks. We propose that by sharing a common latent space, the complementary tasks can produce more robust representations that can enhance the semantic labels. We explore the influence of contour-based tasks on latent space, as well as their impact on the final results of SS. We demonstrate the effectiveness of learning in a multi-task setting for hourglass models in the Cityscapes, CamVid, and Freiburg Forest datasets by improving the state-of-the-art without any refinement post-processing.