 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Study of Multi-Task Hourglass Model for Semantic Segmentation Task
Paper and Code

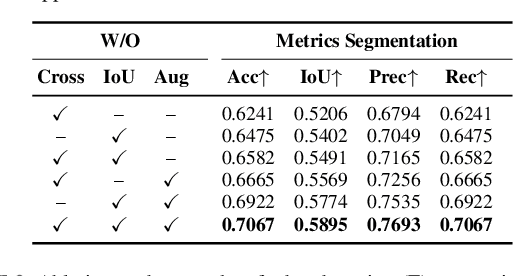

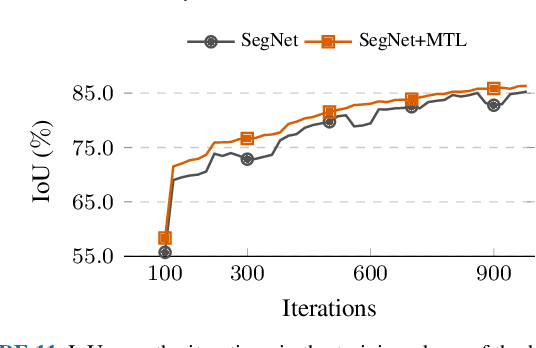
The semantic segmentation (SS) task aims to create a dense classification by labeling at the pixel level each object present on images. Convolutional neural network (CNN) approaches have been widely used, and exhibited the best results in this task. However, the loss of spatial precision on the results is a main drawback that has not been solved. In this work, we propose to use a multi-task approach by complementing the semantic segmentation task with edge detection, semantic contour, and distance transform tasks. We propose that by sharing a common latent space, the complementary tasks can produce more robust representations that can enhance the semantic labels. We explore the influence of contour-based tasks on latent space, as well as their impact on the final results of SS. We demonstrate the effectiveness of learning in a multi-task setting for hourglass models in the Cityscapes, CamVid, and Freiburg Forest datasets by improving the state-of-the-art without any refinement post-processing.