 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcepts' Information Bottleneck Models
Feb 16, 2026Concept Bottleneck Models (CBMs) aim to deliver interpretable predictions by routing decisions through a human-understandable concept layer, yet they often suffer reduced accuracy and concept leakage that undermines faithfulness. We introduce an explicit Information Bottleneck regularizer on the concept layer that penalizes $I(X;C)$ while preserving task-relevant information in $I(C;Y)$, encouraging minimal-sufficient concept representations. We derive two practical variants (a variational objective and an entropy-based surrogate) and integrate them into standard CBM training without architectural changes or additional supervision. Evaluated across six CBM families and three benchmarks, the IB-regularized models consistently outperform their vanilla counterparts. Information-plane analyses further corroborate the intended behavior. These results indicate that enforcing a minimal-sufficient concept bottleneck improves both predictive performance and the reliability of concept-level interventions. The proposed regularizer offers a theoretic-grounded, architecture-agnostic path to more faithful and intervenable CBMs, resolving prior evaluation inconsistencies by aligning training protocols and demonstrating robust gains across model families and datasets.
Explainability of Large Language Models using SMILE: Statistical Model-agnostic Interpretability with Local Explanations
May 27, 2025


Large language models like GPT, LLAMA, and Claude have become incredibly powerful at generating text, but they are still black boxes, so it is hard to understand how they decide what to say. That lack of transparency can be problematic, especially in fields where trust and accountability matter. To help with this, we introduce SMILE, a new method that explains how these models respond to different parts of a prompt. SMILE is model-agnostic and works by slightly changing the input, measuring how the output changes, and then highlighting which words had the most impact. Create simple visual heat maps showing which parts of a prompt matter the most. We tested SMILE on several leading LLMs and used metrics such as accuracy, consistency, stability, and fidelity to show that it gives clear and reliable explanations. By making these models easier to understand, SMILE brings us one step closer to making AI more transparent and trustworthy.
LLM-guided Instance-level Image Manipulation with Diffusion U-Net Cross-Attention Maps
Jan 23, 2025The advancement of text-to-image synthesis has introduced powerful generative models capable of creating realistic images from textual prompts. However, precise control over image attributes remains challenging, especially at the instance level. While existing methods offer some control through fine-tuning or auxiliary information, they often face limitations in flexibility and accuracy. To address these challenges, we propose a pipeline leveraging Large Language Models (LLMs), open-vocabulary detectors, cross-attention maps and intermediate activations of diffusion U-Net for instance-level image manipulation. Our method detects objects mentioned in the prompt and present in the generated image, enabling precise manipulation without extensive training or input masks. By incorporating cross-attention maps, our approach ensures coherence in manipulated images while controlling object positions. Our method enables precise manipulations at the instance level without fine-tuning or auxiliary information such as masks or bounding boxes. Code is available at https://github.com/Palandr123/DiffusionU-NetLLM
Mapping the Mind of an Instruction-based Image Editing using SMILE
Dec 20, 2024



Despite recent advancements in Instruct-based Image Editing models for generating high-quality images, they are known as black boxes and a significant barrier to transparency and user trust. To solve this issue, we introduce SMILE (Statistical Model-agnostic Interpretability with Local Explanations), a novel model-agnostic for localized interpretability that provides a visual heatmap to clarify the textual elements' influence on image-generating models. We applied our method to various Instruction-based Image Editing models like Pix2Pix, Image2Image-turbo and Diffusers-Inpaint and showed how our model can improve interpretability and reliability. Also, we use stability, accuracy, fidelity, and consistency metrics to evaluate our method. These findings indicate the exciting potential of model-agnostic interpretability for reliability and trustworthiness in critical applications such as healthcare and autonomous driving while encouraging additional investigation into the significance of interpretability in enhancing dependable image editing models.
ReFuSeg: Regularized Multi-Modal Fusion for Precise Brain Tumour Segmentation
Aug 26, 2023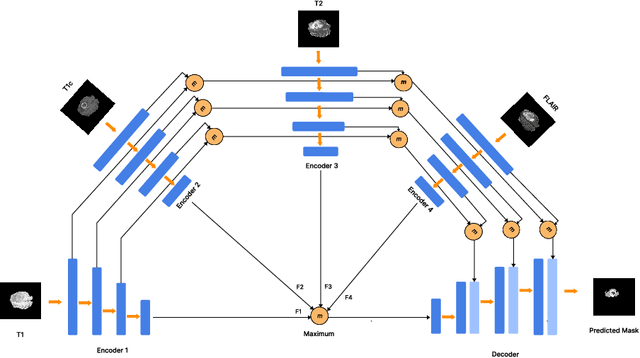
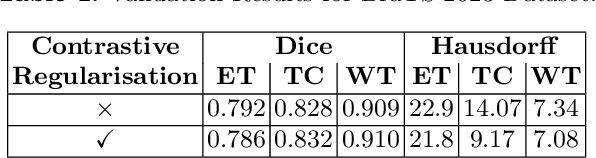
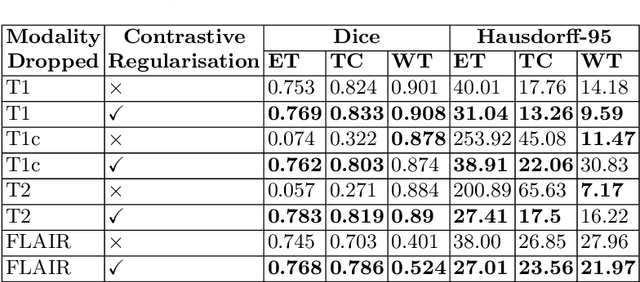
Semantic segmentation of brain tumours is a fundamental task in medical image analysis that can help clinicians in diagnosing the patient and tracking the progression of any malignant entities. Accurate segmentation of brain lesions is essential for medical diagnosis and treatment planning. However, failure to acquire specific MRI imaging modalities can prevent applications from operating in critical situations, raising concerns about their reliability and overall trustworthiness. This paper presents a novel multi-modal approach for brain lesion segmentation that leverages information from four distinct imaging modalities while being robust to real-world scenarios of missing modalities, such as T1, T1c, T2, and FLAIR MRI of brains. Our proposed method can help address the challenges posed by artifacts in medical imagery due to data acquisition errors (such as patient motion) or a reconstruction algorithm's inability to represent the anatomy while ensuring a trade-off in accuracy. Our proposed regularization module makes it robust to these scenarios and ensures the reliability of lesion segmentation.
Not So Robust After All: Evaluating the Robustness of Deep Neural Networks to Unseen Adversarial Attacks
Aug 12, 2023Deep neural networks (DNNs) have gained prominence in various applications, such as classification, recognition, and prediction, prompting increased scrutiny of their properties. A fundamental attribute of traditional DNNs is their vulnerability to modifications in input data, which has resulted in the investigation of adversarial attacks. These attacks manipulate the data in order to mislead a DNN. This study aims to challenge the efficacy and generalization of contemporary defense mechanisms against adversarial attacks. Specifically, we explore the hypothesis proposed by Ilyas et. al, which posits that DNN image features can be either robust or non-robust, with adversarial attacks targeting the latter. This hypothesis suggests that training a DNN on a dataset consisting solely of robust features should produce a model resistant to adversarial attacks. However, our experiments demonstrate that this is not universally true. To gain further insights into our findings, we analyze the impact of adversarial attack norms on DNN representations, focusing on samples subjected to $L_2$ and $L_{\infty}$ norm attacks. Further, we employ canonical correlation analysis, visualize the representations, and calculate the mean distance between these representations and various DNN decision boundaries. Our results reveal a significant difference between $L_2$ and $L_{\infty}$ norms, which could provide insights into the potential dangers posed by $L_{\infty}$ norm attacks, previously underestimated by the research community.
Exploring Semantic Variations in GAN Latent Spaces via Matrix Factorization
May 23, 2023Controlled data generation with GANs is desirable but challenging due to the nonlinearity and high dimensionality of their latent spaces. In this work, we explore image manipulations learned by GANSpace, a state-of-the-art method based on PCA. Through quantitative and qualitative assessments we show: (a) GANSpace produces a wide range of high-quality image manipulations, but they can be highly entangled, limiting potential use cases; (b) Replacing PCA with ICA improves the quality and disentanglement of manipulations; (c) The quality of the generated images can be sensitive to the size of GANs, but regardless of their complexity, fundamental controlling directions can be observed in their latent spaces.
UATTA-ENS: Uncertainty Aware Test Time Augmented Ensemble for PIRC Diabetic Retinopathy Detection
Nov 08, 2022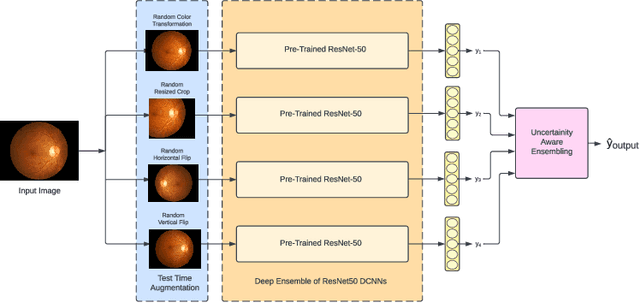
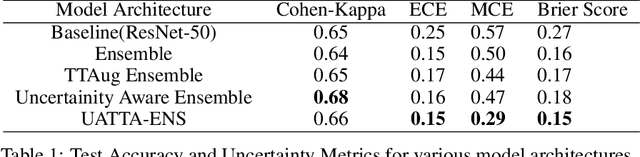
Deep Ensemble Convolutional Neural Networks has become a methodology of choice for analyzing medical images with a diagnostic performance comparable to a physician, including the diagnosis of Diabetic Retinopathy. However, commonly used techniques are deterministic and are therefore unable to provide any estimate of predictive uncertainty. Quantifying model uncertainty is crucial for reducing the risk of misdiagnosis. A reliable architecture should be well-calibrated to avoid over-confident predictions. To address this, we propose a UATTA-ENS: Uncertainty-Aware Test-Time Augmented Ensemble Technique for 5 Class PIRC Diabetic Retinopathy Classification to produce reliable and well-calibrated predictions.
RepFair-GAN: Mitigating Representation Bias in GANs Using Gradient Clipping
Jul 13, 2022

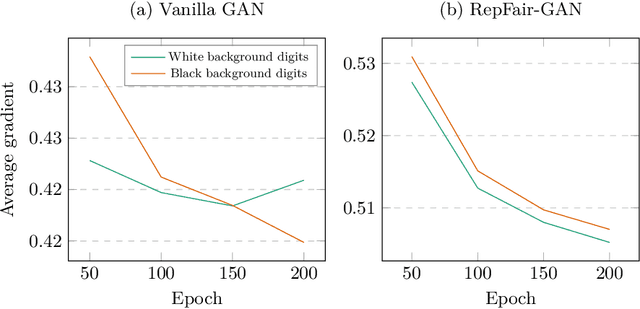
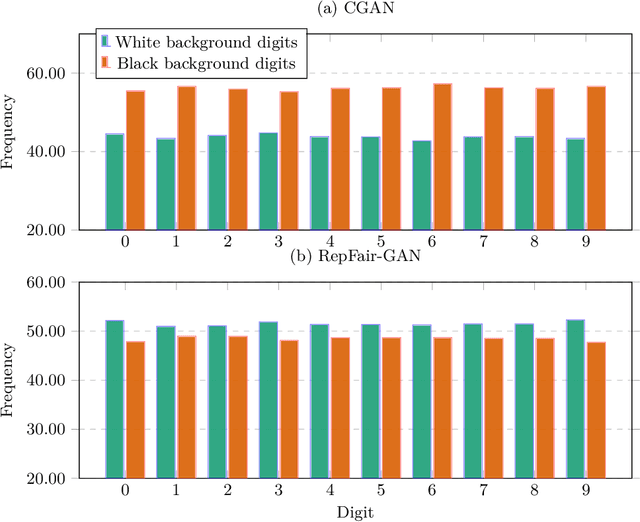
Fairness has become an essential problem in many domains of Machine Learning (ML), such as classification, natural language processing, and Generative Adversarial Networks (GANs). In this research effort, we study the unfairness of GANs. We formally define a new fairness notion for generative models in terms of the distribution of generated samples sharing the same protected attributes (gender, race, etc.). The defined fairness notion (representational fairness) requires the distribution of the sensitive attributes at the test time to be uniform, and, in particular for GAN model, we show that this fairness notion is violated even when the dataset contains equally represented groups, i.e., the generator favors generating one group of samples over the others at the test time. In this work, we shed light on the source of this representation bias in GANs along with a straightforward method to overcome this problem. We first show on two widely used datasets (MNIST, SVHN) that when the norm of the gradient of one group is more important than the other during the discriminator's training, the generator favours sampling data from one group more than the other at test time. We then show that controlling the groups' gradient norm by performing group-wise gradient norm clipping in the discriminator during the training leads to a more fair data generation in terms of representational fairness compared to existing models while preserving the quality of generated samples.
Bridging the Domain Gap for Stance Detection for the Zulu language
May 06, 2022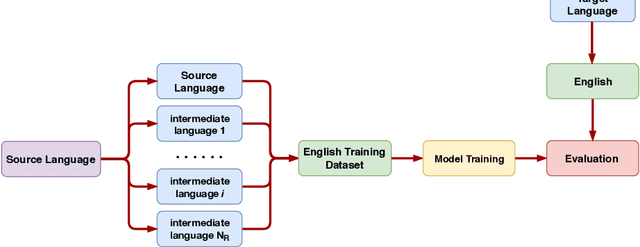
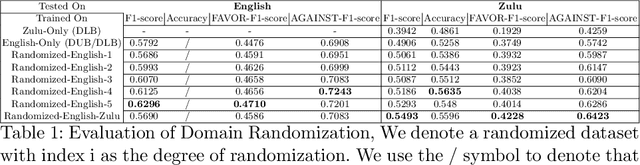
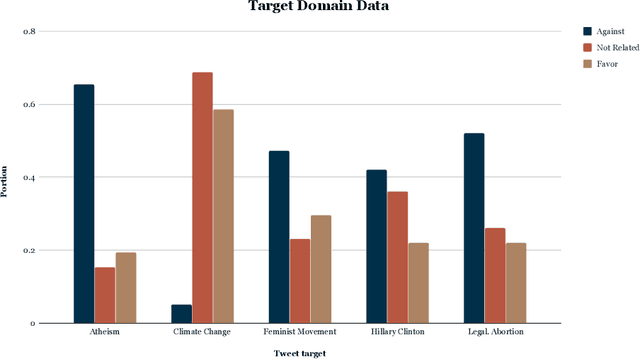

Misinformation has become a major concern in recent last years given its spread across our information sources. In the past years, many NLP tasks have been introduced in this area, with some systems reaching good results on English language datasets. Existing AI based approaches for fighting misinformation in literature suggest automatic stance detection as an integral first step to success. Our paper aims at utilizing this progress made for English to transfers that knowledge into other languages, which is a non-trivial task due to the domain gap between English and the target languages. We propose a black-box non-intrusive method that utilizes techniques from Domain Adaptation to reduce the domain gap, without requiring any human expertise in the target language, by leveraging low-quality data in both a supervised and unsupervised manner. This allows us to rapidly achieve similar results for stance detection for the Zulu language, the target language in this work, as are found for English. We also provide a stance detection dataset in the Zulu language. Our experimental results show that by leveraging English datasets and machine translation we can increase performances on both English data along with other languages.