 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuardians of Image Quality: Benchmarking Defenses Against Adversarial Attacks on Image Quality Metrics
Aug 02, 2024
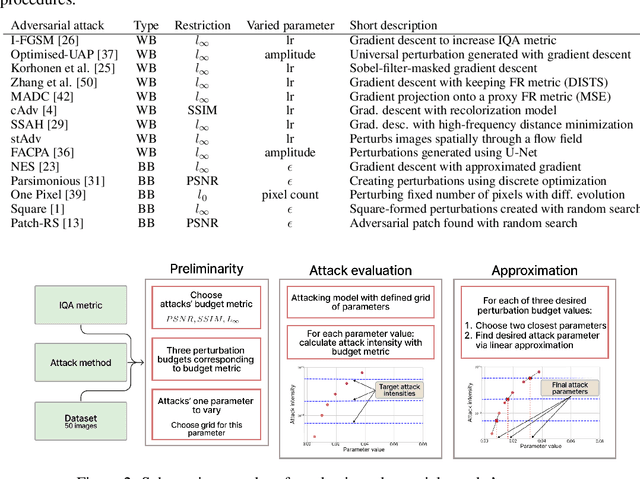


In the field of Image Quality Assessment (IQA), the adversarial robustness of the metrics poses a critical concern. This paper presents a comprehensive benchmarking study of various defense mechanisms in response to the rise in adversarial attacks on IQA. We systematically evaluate 25 defense strategies, including adversarial purification, adversarial training, and certified robustness methods. We applied 14 adversarial attack algorithms of various types in both non-adaptive and adaptive settings and tested these defenses against them. We analyze the differences between defenses and their applicability to IQA tasks, considering that they should preserve IQA scores and image quality. The proposed benchmark aims to guide future developments and accepts submissions of new methods, with the latest results available online: https://videoprocessing.ai/benchmarks/iqa-defenses.html.
Not So Robust After All: Evaluating the Robustness of Deep Neural Networks to Unseen Adversarial Attacks
Aug 12, 2023Deep neural networks (DNNs) have gained prominence in various applications, such as classification, recognition, and prediction, prompting increased scrutiny of their properties. A fundamental attribute of traditional DNNs is their vulnerability to modifications in input data, which has resulted in the investigation of adversarial attacks. These attacks manipulate the data in order to mislead a DNN. This study aims to challenge the efficacy and generalization of contemporary defense mechanisms against adversarial attacks. Specifically, we explore the hypothesis proposed by Ilyas et. al, which posits that DNN image features can be either robust or non-robust, with adversarial attacks targeting the latter. This hypothesis suggests that training a DNN on a dataset consisting solely of robust features should produce a model resistant to adversarial attacks. However, our experiments demonstrate that this is not universally true. To gain further insights into our findings, we analyze the impact of adversarial attack norms on DNN representations, focusing on samples subjected to $L_2$ and $L_{\infty}$ norm attacks. Further, we employ canonical correlation analysis, visualize the representations, and calculate the mean distance between these representations and various DNN decision boundaries. Our results reveal a significant difference between $L_2$ and $L_{\infty}$ norms, which could provide insights into the potential dangers posed by $L_{\infty}$ norm attacks, previously underestimated by the research community.