 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFS-IQA: Certified Feature Smoothing for Robust Image Quality Assessment
Aug 07, 2025We propose a novel certified defense method for Image Quality Assessment (IQA) models based on randomized smoothing with noise applied in the feature space rather than the input space. Unlike prior approaches that inject Gaussian noise directly into input images, often degrading visual quality, our method preserves image fidelity while providing robustness guarantees. To formally connect noise levels in the feature space with corresponding input-space perturbations, we analyze the maximum singular value of the backbone network's Jacobian. Our approach supports both full-reference (FR) and no-reference (NR) IQA models without requiring any architectural modifications, suitable for various scenarios. It is also computationally efficient, requiring a single backbone forward pass per image. Compared to previous methods, it reduces inference time by 99.5% without certification and by 20.6% when certification is applied. We validate our method with extensive experiments on two benchmark datasets, involving six widely-used FR and NR IQA models and comparisons against five state-of-the-art certified defenses. Our results demonstrate consistent improvements in correlation with subjective quality scores by up to 30.9%.
NIC-RobustBench: A Comprehensive Open-Source Toolkit for Neural Image Compression and Robustness Analysis
Jun 23, 2025Adversarial robustness of neural networks is an increasingly important area of research, combining studies on computer vision models, large language models (LLMs), and others. With the release of JPEG AI -- the first standard for end-to-end neural image compression (NIC) methods -- the question of evaluating NIC robustness has become critically significant. However, previous research has been limited to a narrow range of codecs and attacks. To address this, we present \textbf{NIC-RobustBench}, the first open-source framework to evaluate NIC robustness and adversarial defenses' efficiency, in addition to comparing Rate-Distortion (RD) performance. The framework includes the largest number of codecs among all known NIC libraries and is easily scalable. The paper demonstrates a comprehensive overview of the NIC-RobustBench framework and employs it to analyze NIC robustness. Our code is available online at https://github.com/msu-video-group/NIC-RobustBench.
Robustness as Architecture: Designing IQA Models to Withstand Adversarial Perturbations
Jun 05, 2025Image Quality Assessment (IQA) models are increasingly relied upon to evaluate image quality in real-world systems -- from compression and enhancement to generation and streaming. Yet their adoption brings a fundamental risk: these models are inherently unstable. Adversarial manipulations can easily fool them, inflating scores and undermining trust. Traditionally, such vulnerabilities are addressed through data-driven defenses -- adversarial retraining, regularization, or input purification. But what if this is the wrong lens? What if robustness in perceptual models is not something to learn but something to design? In this work, we propose a provocative idea: robustness as an architectural prior. Rather than training models to resist perturbations, we reshape their internal structure to suppress sensitivity from the ground up. We achieve this by enforcing orthogonal information flow, constraining the network to norm-preserving operations -- and further stabilizing the system through pruning and fine-tuning. The result is a robust IQA architecture that withstands adversarial attacks without requiring adversarial training or significant changes to the original model. This approach suggests a shift in perspective: from optimizing robustness through data to engineering it through design.
Cross-Modal Transferable Image-to-Video Attack on Video Quality Metrics
Jan 14, 2025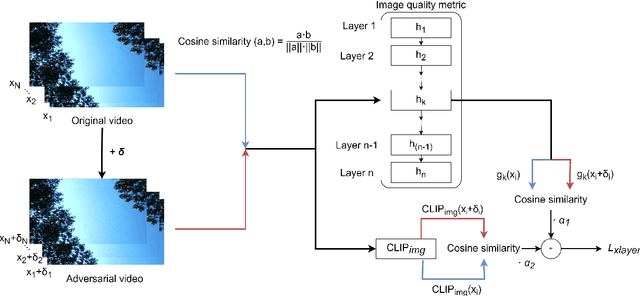
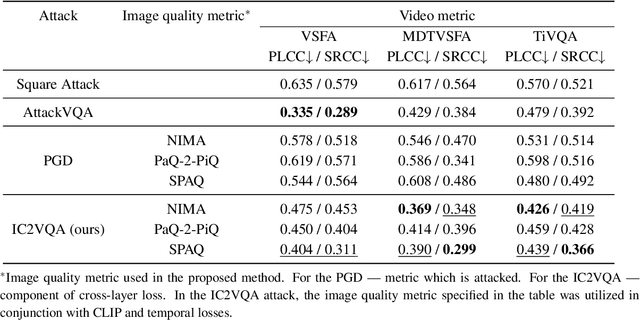
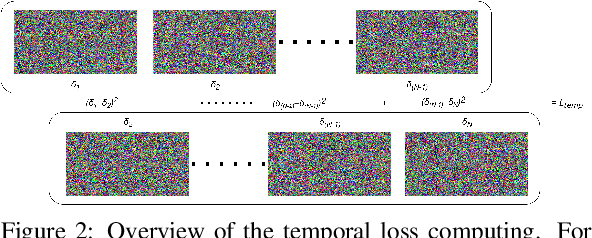

Recent studies have revealed that modern image and video quality assessment (IQA/VQA) metrics are vulnerable to adversarial attacks. An attacker can manipulate a video through preprocessing to artificially increase its quality score according to a certain metric, despite no actual improvement in visual quality. Most of the attacks studied in the literature are white-box attacks, while black-box attacks in the context of VQA have received less attention. Moreover, some research indicates a lack of transferability of adversarial examples generated for one model to another when applied to VQA. In this paper, we propose a cross-modal attack method, IC2VQA, aimed at exploring the vulnerabilities of modern VQA models. This approach is motivated by the observation that the low-level feature spaces of images and videos are similar. We investigate the transferability of adversarial perturbations across different modalities; specifically, we analyze how adversarial perturbations generated on a white-box IQA model with an additional CLIP module can effectively target a VQA model. The addition of the CLIP module serves as a valuable aid in increasing transferability, as the CLIP model is known for its effective capture of low-level semantics. Extensive experiments demonstrate that IC2VQA achieves a high success rate in attacking three black-box VQA models. We compare our method with existing black-box attack strategies, highlighting its superiority in terms of attack success within the same number of iterations and levels of attack strength. We believe that the proposed method will contribute to the deeper analysis of robust VQA metrics.
IQA-Adapter: Exploring Knowledge Transfer from Image Quality Assessment to Diffusion-based Generative Models
Dec 02, 2024



Diffusion-based models have recently transformed conditional image generation, achieving unprecedented fidelity in generating photorealistic and semantically accurate images. However, consistently generating high-quality images remains challenging, partly due to the lack of mechanisms for conditioning outputs on perceptual quality. In this work, we propose methods to integrate image quality assessment (IQA) models into diffusion-based generators, enabling quality-aware image generation. First, we experiment with gradient-based guidance to optimize image quality directly and show this approach has limited generalizability. To address this, we introduce IQA-Adapter, a novel architecture that conditions generation on target quality levels by learning the relationship between images and quality scores. When conditioned on high target quality, IQA-Adapter shifts the distribution of generated images towards a higher-quality subdomain. This approach achieves up to a 10% improvement across multiple objective metrics, as confirmed by a subjective study, while preserving generative diversity and content. Additionally, IQA-Adapter can be used inversely as a degradation model, generating progressively more distorted images when conditioned on lower quality scores. Our quality-aware methods also provide insights into the adversarial robustness of IQA models, underscoring the potential of quality conditioning in generative modeling and the importance of robust IQA methods.
Stochastic BIQA: Median Randomized Smoothing for Certified Blind Image Quality Assessment
Nov 19, 2024



Most modern No-Reference Image-Quality Assessment (NR-IQA) metrics are based on neural networks vulnerable to adversarial attacks. Attacks on such metrics lead to incorrect image/video quality predictions, which poses significant risks, especially in public benchmarks. Developers of image processing algorithms may unfairly increase the score of a target IQA metric without improving the actual quality of the adversarial image. Although some empirical defenses for IQA metrics were proposed, they do not provide theoretical guarantees and may be vulnerable to adaptive attacks. This work focuses on developing a provably robust no-reference IQA metric. Our method is based on Median Smoothing (MS) combined with an additional convolution denoiser with ranking loss to improve the SROCC and PLCC scores of the defended IQA metric. Compared with two prior methods on three datasets, our method exhibited superior SROCC and PLCC scores while maintaining comparable certified guarantees.
Exploring adversarial robustness of JPEG AI: methodology, comparison and new methods
Nov 18, 2024



Adversarial robustness of neural networks is an increasingly important area of research, combining studies on computer vision models, large language models (LLMs), and others. With the release of JPEG AI - the first standard for end-to-end neural image compression (NIC) methods - the question of its robustness has become critically significant. JPEG AI is among the first international, real-world applications of neural-network-based models to be embedded in consumer devices. However, research on NIC robustness has been limited to open-source codecs and a narrow range of attacks. This paper proposes a new methodology for measuring NIC robustness to adversarial attacks. We present the first large-scale evaluation of JPEG AI's robustness, comparing it with other NIC models. Our evaluation results and code are publicly available online (link is hidden for a blind review).
Machine vision-aware quality metrics for compressed image and video assessment
Nov 11, 2024A main goal in developing video-compression algorithms is to enhance human-perceived visual quality while maintaining file size. But modern video-analysis efforts such as detection and recognition, which are integral to video surveillance and autonomous vehicles, involve so much data that they necessitate machine-vision processing with minimal human intervention. In such cases, the video codec must be optimized for machine vision. This paper explores the effects of compression on detection and recognition algorithms (objects, faces, and license plates) and introduces novel full-reference image/video-quality metrics for each task, tailored to machine vision. Experimental results indicate our proposed metrics correlate better with the machine-vision results for the respective tasks than do existing image/video-quality metrics.
JPEG AI Image Compression Visual Artifacts: Detection Methods and Dataset
Nov 11, 2024
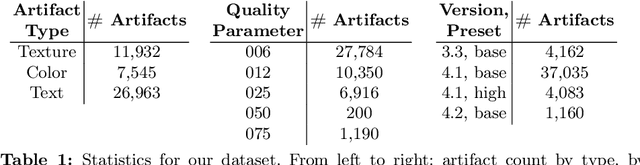

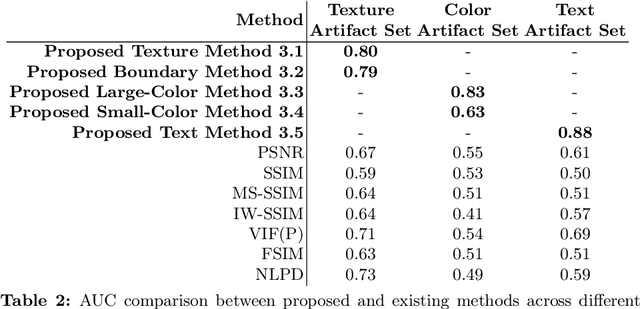
Learning-based image compression methods have improved in recent years and started to outperform traditional codecs. However, neural-network approaches can unexpectedly introduce visual artifacts in some images. We therefore propose methods to separately detect three types of artifacts (texture and boundary degradation, color change, and text corruption), to localize the affected regions, and to quantify the artifact strength. We consider only those regions that exhibit distortion due solely to the neural compression but that a traditional codec recovers successfully at a comparable bitrate. We employed our methods to collect artifacts for the JPEG AI verification model with respect to HM-18.0, the H.265 reference software. We processed about 350,000 unique images from the Open Images dataset using different compression-quality parameters; the result is a dataset of 46,440 artifacts validated through crowd-sourced subjective assessment. Our proposed dataset and methods are valuable for testing neural-network-based image codecs, identifying bugs in these codecs, and enhancing their performance. We make source code of the methods and the dataset publicly available.
AIM 2024 Challenge on Video Super-Resolution Quality Assessment: Methods and Results
Oct 05, 2024



This paper presents the Video Super-Resolution (SR) Quality Assessment (QA) Challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2024. The task of this challenge was to develop an objective QA method for videos upscaled 2x and 4x by modern image- and video-SR algorithms. QA methods were evaluated by comparing their output with aggregate subjective scores collected from >150,000 pairwise votes obtained through crowd-sourced comparisons across 52 SR methods and 1124 upscaled videos. The goal was to advance the state-of-the-art in SR QA, which had proven to be a challenging problem with limited applicability of traditional QA methods. The challenge had 29 registered participants, and 5 teams had submitted their final results, all outperforming the current state-of-the-art. All data, including the private test subset, has been made publicly available on the challenge homepage at https://challenges.videoprocessing.ai/challenges/super-resolution-metrics-challenge.html