 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeME-IQA: Memory-Enhanced Image Quality Assessment via Re-Ranking
Mar 21, 2026Reasoning-induced vision-language models (VLMs) advance image quality assessment (IQA) with textual reasoning, yet their scalar scores often lack sensitivity and collapse to a few values, so-called discrete collapse. We introduce ME-IQA, a plug-and-play, test-time memory-enhanced re-ranking framework. It (i) builds a memory bank and retrieves semantically and perceptually aligned neighbors using reasoning summaries, (ii) reframes the VLM as a probabilistic comparator to obtain pairwise preference probabilities and fuse this ordinal evidence with the initial score under Thurstone's Case V model, and (iii) performs gated reflection and consolidates memory to improve future decisions. This yields denser, distortion-sensitive predictions and mitigates discrete collapse. Experiments across multiple IQA benchmarks show consistent gains over strong reasoning-induced VLM baselines, existing non-reasoning IQA methods, and test-time scaling alternatives.
AIM 2024 Challenge on Video Super-Resolution Quality Assessment: Methods and Results
Oct 05, 2024



This paper presents the Video Super-Resolution (SR) Quality Assessment (QA) Challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2024. The task of this challenge was to develop an objective QA method for videos upscaled 2x and 4x by modern image- and video-SR algorithms. QA methods were evaluated by comparing their output with aggregate subjective scores collected from >150,000 pairwise votes obtained through crowd-sourced comparisons across 52 SR methods and 1124 upscaled videos. The goal was to advance the state-of-the-art in SR QA, which had proven to be a challenging problem with limited applicability of traditional QA methods. The challenge had 29 registered participants, and 5 teams had submitted their final results, all outperforming the current state-of-the-art. All data, including the private test subset, has been made publicly available on the challenge homepage at https://challenges.videoprocessing.ai/challenges/super-resolution-metrics-challenge.html
StyleAM: Perception-Oriented Unsupervised Domain Adaption for Non-reference Image Quality Assessment
Jul 29, 2022

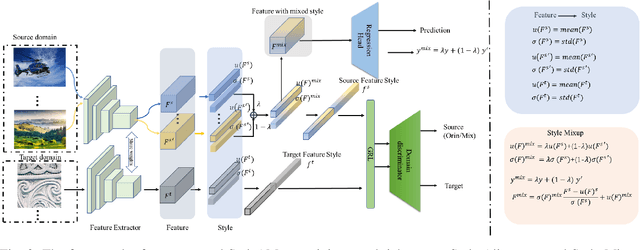

Deep neural networks (DNNs) have shown great potential in non-reference image quality assessment (NR-IQA). However, the annotation of NR-IQA is labor-intensive and time-consuming, which severely limits their application especially for authentic images. To relieve the dependence on quality annotation, some works have applied unsupervised domain adaptation (UDA) to NR-IQA. However, the above methods ignore that the alignment space used in classification is sub-optimal, since the space is not elaborately designed for perception. To solve this challenge, we propose an effective perception-oriented unsupervised domain adaptation method StyleAM for NR-IQA, which transfers sufficient knowledge from label-rich source domain data to label-free target domain images via Style Alignment and Mixup. Specifically, we find a more compact and reliable space i.e., feature style space for perception-oriented UDA based on an interesting/amazing observation, that the feature style (i.e., the mean and variance) of the deep layer in DNNs is exactly associated with the quality score in NR-IQA. Therefore, we propose to align the source and target domains in a more perceptual-oriented space i.e., the feature style space, to reduce the intervention from other quality-irrelevant feature factors. Furthermore, to increase the consistency between quality score and its feature style, we also propose a novel feature augmentation strategy Style Mixup, which mixes the feature styles (i.e., the mean and variance) before the last layer of DNNs together with mixing their labels. Extensive experimental results on two typical cross-domain settings (i.e., synthetic to authentic, and multiple distortions to one distortion) have demonstrated the effectiveness of our proposed StyleAM on NR-IQA.
Source-free Unsupervised Domain Adaptation for Blind Image Quality Assessment
Jul 17, 2022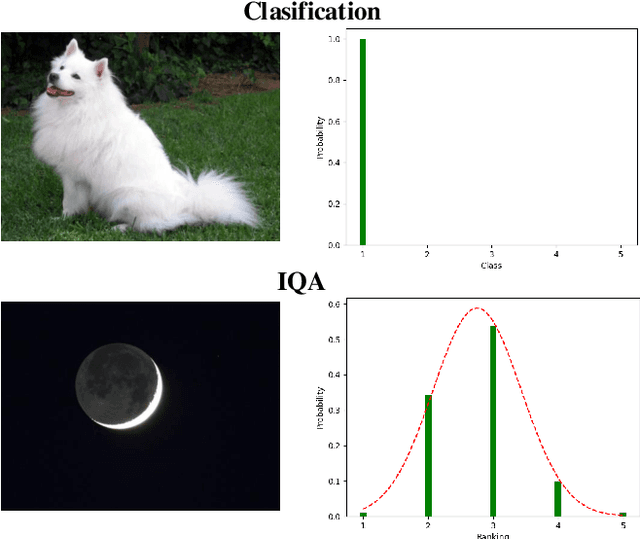

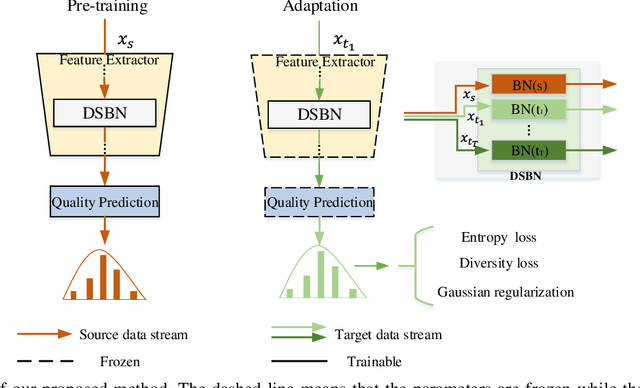

Existing learning-based methods for blind image quality assessment (BIQA) are heavily dependent on large amounts of annotated training data, and usually suffer from a severe performance degradation when encountering the domain/distribution shift problem. Thanks to the development of unsupervised domain adaptation (UDA), some works attempt to transfer the knowledge from a label-sufficient source domain to a label-free target domain under domain shift with UDA. However, it requires the coexistence of source and target data, which might be impractical for source data due to the privacy or storage issues. In this paper, we take the first step towards the source-free unsupervised domain adaptation (SFUDA) in a simple yet efficient manner for BIQA to tackle the domain shift without access to the source data. Specifically, we cast the quality assessment task as a rating distribution prediction problem. Based on the intrinsic properties of BIQA, we present a group of well-designed self-supervised objectives to guide the adaptation of the BN affine parameters towards the target domain. Among them, minimizing the prediction entropy and maximizing the batch prediction diversity aim to encourage more confident results while avoiding the trivial solution. Besides, based on the observation that the IQA rating distribution of single image follows the Gaussian distribution, we apply Gaussian regularization to the predicted rating distribution to make it more consistent with the nature of human scoring. Extensive experimental results under cross-domain scenarios demonstrated the effectiveness of our proposed method to mitigate the domain shift.
SwinIQA: Learned Swin Distance for Compressed Image Quality Assessment
May 09, 2022
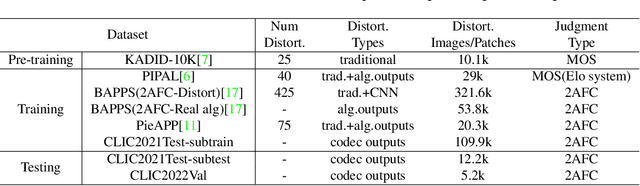

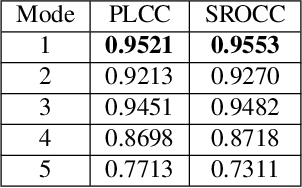
Image compression has raised widespread interest recently due to its significant importance for multimedia storage and transmission. Meanwhile, a reliable image quality assessment (IQA) for compressed images can not only help to verify the performance of various compression algorithms but also help to guide the compression optimization in turn. In this paper, we design a full-reference image quality assessment metric SwinIQA to measure the perceptual quality of compressed images in a learned Swin distance space. It is known that the compression artifacts are usually non-uniformly distributed with diverse distortion types and degrees. To warp the compressed images into the shared representation space while maintaining the complex distortion information, we extract the hierarchical feature representations from each stage of the Swin Transformer. Besides, we utilize cross attention operation to map the extracted feature representations into a learned Swin distance space. Experimental results show that the proposed metric achieves higher consistency with human's perceptual judgment compared with both traditional methods and learning-based methods on CLIC datasets.
FAN: Frequency Aggregation Network for Real Image Super-resolution
Sep 30, 2020

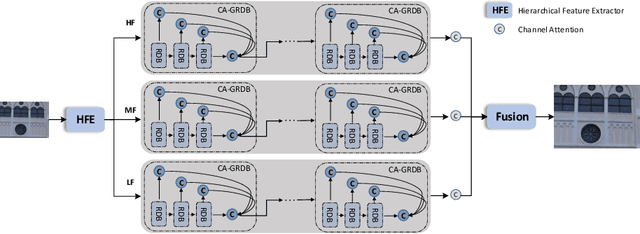

Single image super-resolution (SISR) aims to recover the high-resolution (HR) image from its low-resolution (LR) input image. With the development of deep learning, SISR has achieved great progress. However, It is still a challenge to restore the real-world LR image with complicated authentic degradations. Therefore, we propose FAN, a frequency aggregation network, to address the real-world image super-resolu-tion problem. Specifically, we extract different frequencies of the LR image and pass them to a channel attention-grouped residual dense network (CA-GRDB) individually to output corresponding feature maps. And then aggregating these residual dense feature maps adaptively to recover the HR image with enhanced details and textures. We conduct extensive experiments quantitatively and qualitatively to verify that our FAN performs well on the real image super-resolution task of AIM 2020 challenge. According to the released final results, our team SR-IM achieves the fourth place on the X4 track with PSNR of 31.1735 and SSIM of 0.8728.
LIRA: Lifelong Image Restoration from Unknown Blended Distortions
Aug 19, 2020



Most existing image restoration networks are designed in a disposable way and catastrophically forget previously learned distortions when trained on a new distortion removal task. To alleviate this problem, we raise the novel lifelong image restoration problem for blended distortions. We first design a base fork-join model in which multiple pre-trained expert models specializing in individual distortion removal task work cooperatively and adaptively to handle blended distortions. When the input is degraded by a new distortion, inspired by adult neurogenesis in human memory system, we develop a neural growing strategy where the previously trained model can incorporate a new expert branch and continually accumulate new knowledge without interfering with learned knowledge. Experimental results show that the proposed approach can not only achieve state-of-the-art performance on blended distortions removal tasks in both PSNR/SSIM metrics, but also maintain old expertise while learning new restoration tasks.