 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-preserving Feature Alignment for Old Photo Colorization
Aug 18, 2025Deep learning techniques have made significant advancements in reference-based colorization by training on large-scale datasets. However, directly applying these methods to the task of colorizing old photos is challenging due to the lack of ground truth and the notorious domain gap between natural gray images and old photos. To address this issue, we propose a novel CNN-based algorithm called SFAC, i.e., Structure-preserving Feature Alignment Colorizer. SFAC is trained on only two images for old photo colorization, eliminating the reliance on big data and allowing direct processing of the old photo itself to overcome the domain gap problem. Our primary objective is to establish semantic correspondence between the two images, ensuring that semantically related objects have similar colors. We achieve this through a feature distribution alignment loss that remains robust to different metric choices. However, utilizing robust semantic correspondence to transfer color from the reference to the old photo can result in inevitable structure distortions. To mitigate this, we introduce a structure-preserving mechanism that incorporates a perceptual constraint at the feature level and a frozen-updated pyramid at the pixel level. Extensive experiments demonstrate the effectiveness of our method for old photo colorization, as confirmed by qualitative and quantitative metrics.
Region-Adaptive Video Sharpening via Rate-Perception Optimization
Aug 12, 2025



Sharpening is a widely adopted video enhancement technique. However, uniform sharpening intensity ignores texture variations, degrading video quality. Sharpening also increases bitrate, and there's a lack of techniques to optimally allocate these additional bits across diverse regions. Thus, this paper proposes RPO-AdaSharp, an end-to-end region-adaptive video sharpening model for both perceptual enhancement and bitrate savings. We use the coding tree unit (CTU) partition mask as prior information to guide and constrain the allocation of increased bits. Experiments on benchmarks demonstrate the effectiveness of the proposed model qualitatively and quantitatively.
Frequency-Assisted Adaptive Sharpening Scheme Considering Bitrate and Quality Tradeoff
Aug 12, 2025Sharpening is a widely adopted technique to improve video quality, which can effectively emphasize textures and alleviate blurring. However, increasing the sharpening level comes with a higher video bitrate, resulting in degraded Quality of Service (QoS). Furthermore, the video quality does not necessarily improve with increasing sharpening levels, leading to issues such as over-sharpening. Clearly, it is essential to figure out how to boost video quality with a proper sharpening level while also controlling bandwidth costs effectively. This paper thus proposes a novel Frequency-assisted Sharpening level Prediction model (FreqSP). We first label each video with the sharpening level correlating to the optimal bitrate and quality tradeoff as ground truth. Then taking uncompressed source videos as inputs, the proposed FreqSP leverages intricate CNN features and high-frequency components to estimate the optimal sharpening level. Extensive experiments demonstrate the effectiveness of our method.
Adaptive High-Frequency Preprocessing for Video Coding
Aug 12, 2025
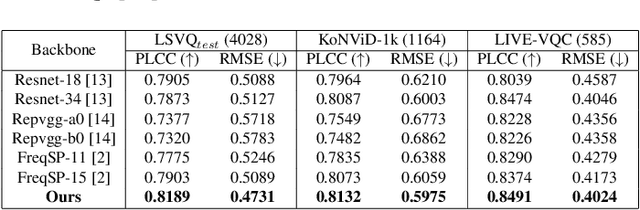
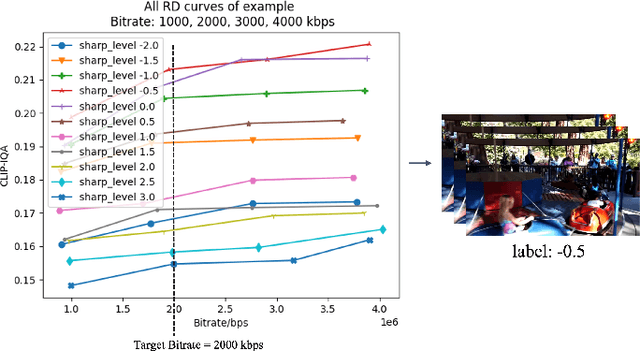
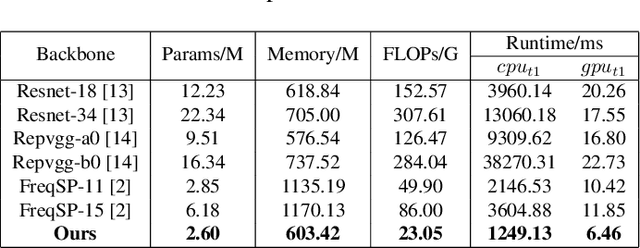
High-frequency components are crucial for maintaining video clarity and realism, but they also significantly impact coding bitrate, resulting in increased bandwidth and storage costs. This paper presents an end-to-end learning-based framework for adaptive high-frequency preprocessing to enhance subjective quality and save bitrate in video coding. The framework employs the Frequency-attentive Feature pyramid Prediction Network (FFPN) to predict the optimal high-frequency preprocessing strategy, guiding subsequent filtering operators to achieve the optimal tradeoff between bitrate and quality after compression. For training FFPN, we pseudo-label each training video with the optimal strategy, determined by comparing the rate-distortion (RD) performance across different preprocessing types and strengths. Distortion is measured using the latest quality assessment metric. Comprehensive evaluations on multiple datasets demonstrate the visually appealing enhancement capabilities and bitrate savings achieved by our framework.
NTIRE 2025 Challenge on UGC Video Enhancement: Methods and Results
May 05, 2025This paper presents an overview of the NTIRE 2025 Challenge on UGC Video Enhancement. The challenge constructed a set of 150 user-generated content videos without reference ground truth, which suffer from real-world degradations such as noise, blur, faded colors, compression artifacts, etc. The goal of the participants was to develop an algorithm capable of improving the visual quality of such videos. Given the widespread use of UGC on short-form video platforms, this task holds substantial practical importance. The evaluation was based on subjective quality assessment in crowdsourcing, obtaining votes from over 8000 assessors. The challenge attracted more than 25 teams submitting solutions, 7 of which passed the final phase with source code verification. The outcomes may provide insights into the state-of-the-art in UGC video enhancement and highlight emerging trends and effective strategies in this evolving research area. All data, including the processed videos and subjective comparison votes and scores, is made publicly available at https://github.com/msu-video-group/NTIRE25_UGC_Video_Enhancement.
Image-to-Image Translation: Methods and Applications
Jan 21, 2021

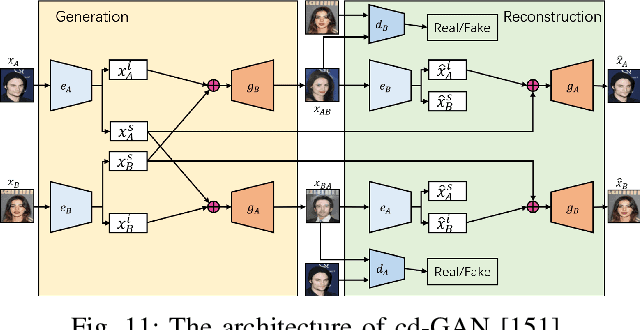
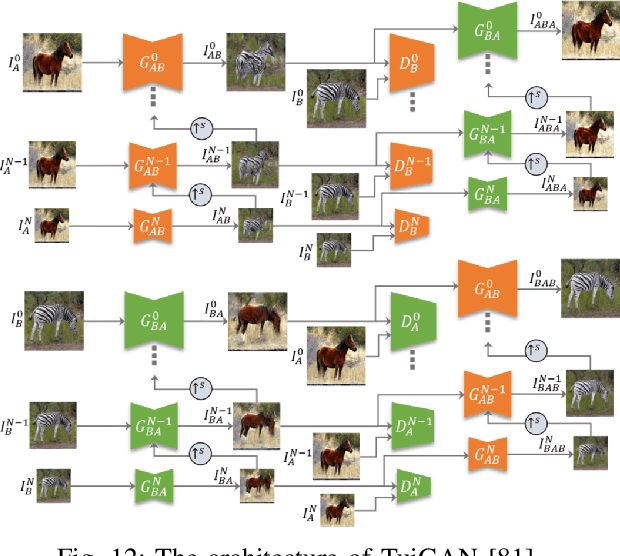
Image-to-image translation (I2I) aims to transfer images from a source domain to a target domain while preserving the content representations. I2I has drawn increasing attention and made tremendous progress in recent years because of its wide range of applications in many computer vision and image processing problems, such as image synthesis, segmentation, style transfer, restoration, and pose estimation. In this paper, we provide an overview of the I2I works developed in recent years. We will analyze the key techniques of the existing I2I works and clarify the main progress the community has made. Additionally, we will elaborate on the effect of I2I on the research and industry community and point out remaining challenges in related fields.
Learning Omni-frequency Region-adaptive Representations for Real Image Super-Resolution
Jan 10, 2021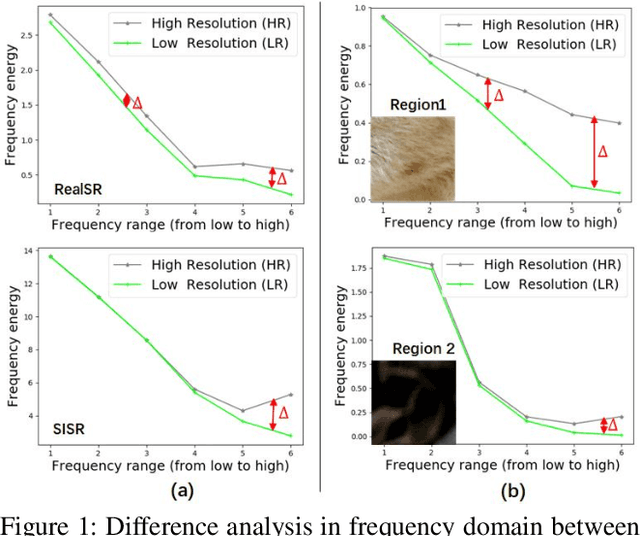
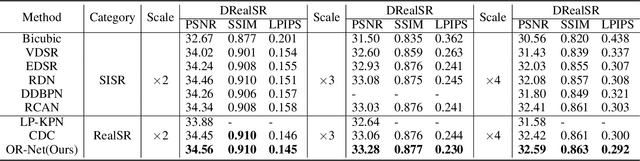
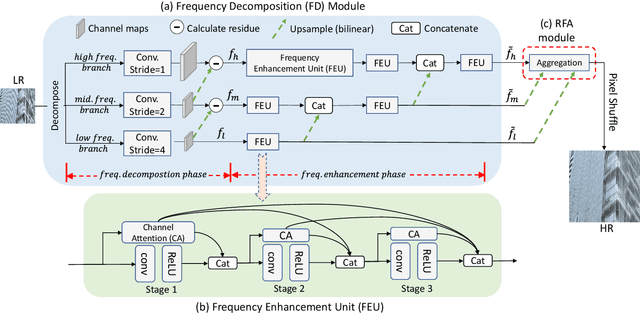
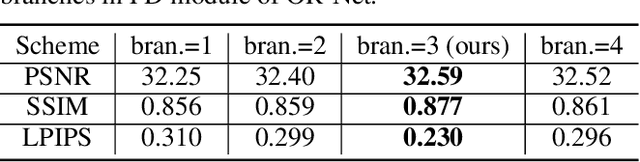
Traditional single image super-resolution (SISR) methods that focus on solving single and uniform degradation (i.e., bicubic down-sampling), typically suffer from poor performance when applied into real-world low-resolution (LR) images due to the complicated realistic degradations. The key to solving this more challenging real image super-resolution (RealSR) problem lies in learning feature representations that are both informative and content-aware. In this paper, we propose an Omni-frequency Region-adaptive Network (ORNet) to address both challenges, here we call features of all low, middle and high frequencies omni-frequency features. Specifically, we start from the frequency perspective and design a Frequency Decomposition (FD) module to separate different frequency components to comprehensively compensate the information lost for real LR image. Then, considering the different regions of real LR image have different frequency information lost, we further design a Region-adaptive Frequency Aggregation (RFA) module by leveraging dynamic convolution and spatial attention to adaptively restore frequency components for different regions. The extensive experiments endorse the effective, and scenario-agnostic nature of our OR-Net for RealSR.
FAN: Frequency Aggregation Network for Real Image Super-resolution
Sep 30, 2020

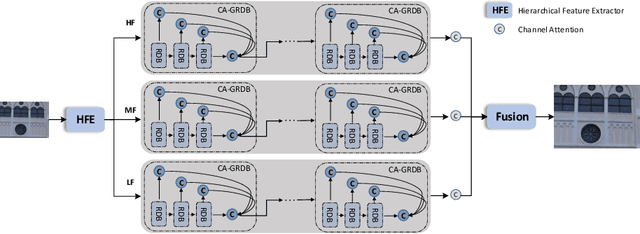

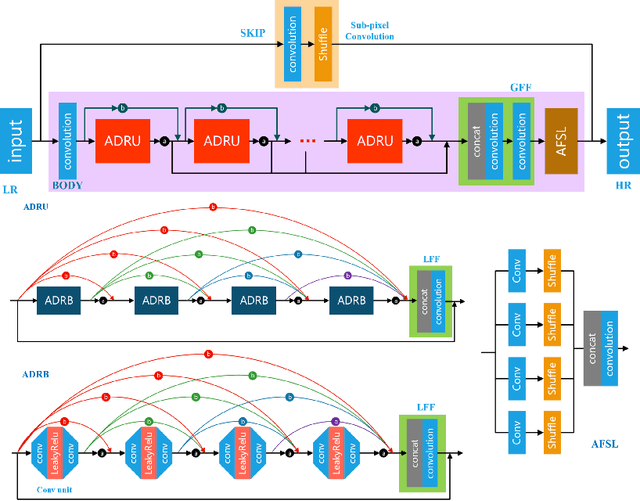
Single image super-resolution (SISR) aims to recover the high-resolution (HR) image from its low-resolution (LR) input image. With the development of deep learning, SISR has achieved great progress. However, It is still a challenge to restore the real-world LR image with complicated authentic degradations. Therefore, we propose FAN, a frequency aggregation network, to address the real-world image super-resolu-tion problem. Specifically, we extract different frequencies of the LR image and pass them to a channel attention-grouped residual dense network (CA-GRDB) individually to output corresponding feature maps. And then aggregating these residual dense feature maps adaptively to recover the HR image with enhanced details and textures. We conduct extensive experiments quantitatively and qualitatively to verify that our FAN performs well on the real image super-resolution task of AIM 2020 challenge. According to the released final results, our team SR-IM achieves the fourth place on the X4 track with PSNR of 31.1735 and SSIM of 0.8728.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020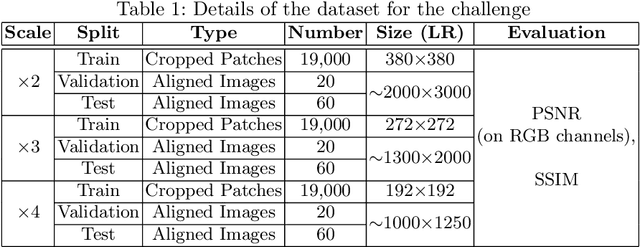
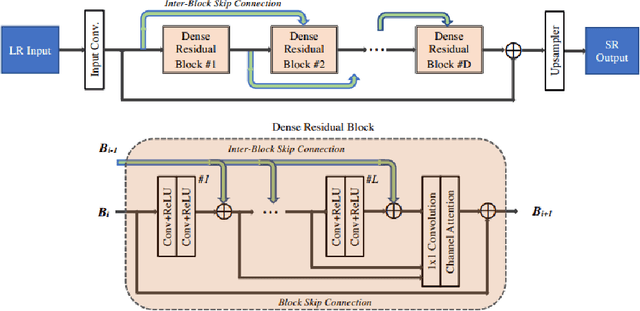
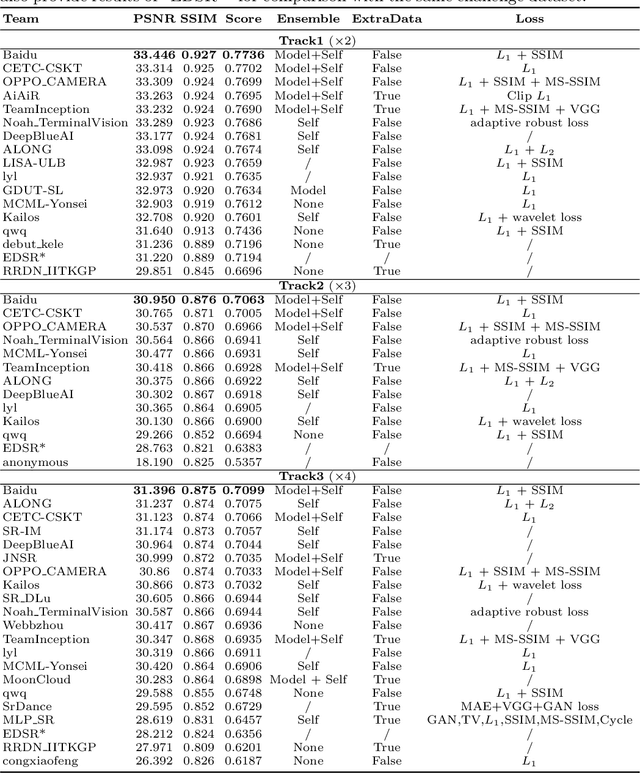
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
TuiGAN: Learning Versatile Image-to-Image Translation with Two Unpaired Images
Apr 09, 2020

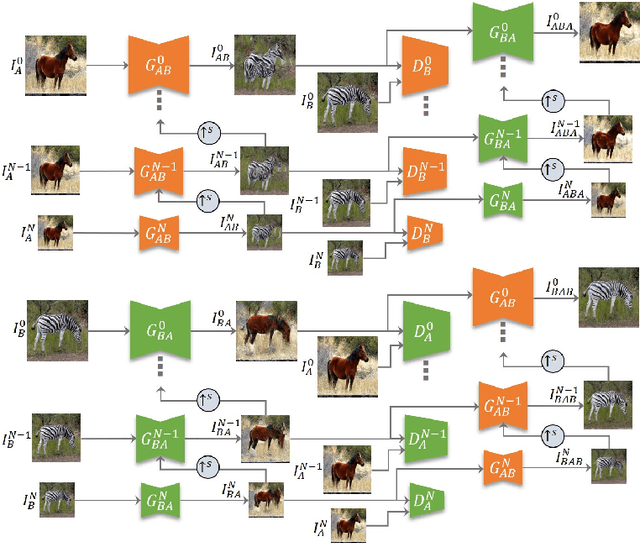
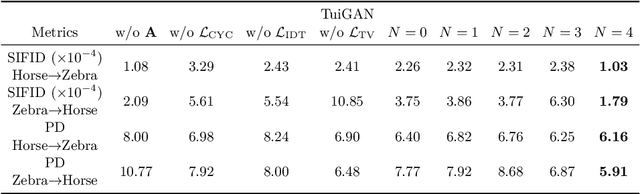
An unsupervised image-to-image translation (UI2I) task deals with learning a mapping between two domains without paired images. While existing UI2I methods usually require numerous unpaired images from different domains for training, there are many scenarios where training data is quite limited. In this paper, we argue that even if each domain contains a single image, UI2I can still be achieved. To this end, we propose TuiGAN, a generative model that is trained on only two unpaired images and amounts to one-shot unsupervised learning. With TuiGAN, an image is translated in a coarse-to-fine manner where the generated image is gradually refined from global structures to local details. We conduct extensive experiments to verify that our versatile method can outperform strong baselines on a wide variety of UI2I tasks. Moreover, TuiGAN is capable of achieving comparable performance with the state-of-the-art UI2I models trained with sufficient data.