 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Beyond Views: Multi-View Driving Scene Video Generation with Holistic Attention
Dec 04, 2024
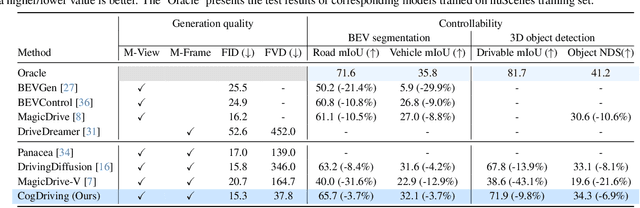


Generating multi-view videos for autonomous driving training has recently gained much attention, with the challenge of addressing both cross-view and cross-frame consistency. Existing methods typically apply decoupled attention mechanisms for spatial, temporal, and view dimensions. However, these approaches often struggle to maintain consistency across dimensions, particularly when handling fast-moving objects that appear at different times and viewpoints. In this paper, we present CogDriving, a novel network designed for synthesizing high-quality multi-view driving videos. CogDriving leverages a Diffusion Transformer architecture with holistic-4D attention modules, enabling simultaneous associations across the spatial, temporal, and viewpoint dimensions. We also propose a lightweight controller tailored for CogDriving, i.e., Micro-Controller, which uses only 1.1% of the parameters of the standard ControlNet, enabling precise control over Bird's-Eye-View layouts. To enhance the generation of object instances crucial for autonomous driving, we propose a re-weighted learning objective, dynamically adjusting the learning weights for object instances during training. CogDriving demonstrates strong performance on the nuScenes validation set, achieving an FVD score of 37.8, highlighting its ability to generate realistic driving videos. The project can be found at https://luhannan.github.io/CogDrivingPage/.
Evaluation of Text-to-Video Generation Models: A Dynamics Perspective
Jul 01, 2024Comprehensive and constructive evaluation protocols play an important role in the development of sophisticated text-to-video (T2V) generation models. Existing evaluation protocols primarily focus on temporal consistency and content continuity, yet largely ignore the dynamics of video content. Dynamics are an essential dimension for measuring the visual vividness and the honesty of video content to text prompts. In this study, we propose an effective evaluation protocol, termed DEVIL, which centers on the dynamics dimension to evaluate T2V models. For this purpose, we establish a new benchmark comprising text prompts that fully reflect multiple dynamics grades, and define a set of dynamics scores corresponding to various temporal granularities to comprehensively evaluate the dynamics of each generated video. Based on the new benchmark and the dynamics scores, we assess T2V models with the design of three metrics: dynamics range, dynamics controllability, and dynamics-based quality. Experiments show that DEVIL achieves a Pearson correlation exceeding 90% with human ratings, demonstrating its potential to advance T2V generation models. Code is available at https://github.com/MingXiangL/DEVIL.
Fine-tuning Diffusion Models for Enhancing Face Quality in Text-to-image Generation
Jun 24, 2024



Diffusion models (DMs) have achieved significant success in generating imaginative images given textual descriptions. However, they are likely to fall short when it comes to real-life scenarios with intricate details.The low-quality, unrealistic human faces in text-to-image generation are one of the most prominent issues, hindering the wide application of DMs in practice. Targeting addressing such an issue, we first assess the face quality of generations from popular pre-trained DMs with the aid of human annotators and then evaluate the alignment between existing metrics such as ImageReward, Human Preference Score, Aesthetic Score Predictor, and Face Quality Assessment, with human judgments. Observing that existing metrics can be unsatisfactory for quantifying face quality, we develop a novel metric named Face Score (FS) by fine-tuning ImageReward on a dataset of (good, bad) face pairs cheaply crafted by an inpainting pipeline of DMs. Extensive studies reveal that FS enjoys a superior alignment with humans. On the other hand, FS opens up the door for refining DMs for better face generation. To achieve this, we incorporate a guidance loss on the denoising trajectories of the aforementioned face pairs for fine-tuning pre-trained DMs such as Stable Diffusion V1.5 and Realistic Vision V5.1. Intuitively, such a loss pushes the trajectory of bad faces toward that of good ones. Comprehensive experiments verify the efficacy of our approach for improving face quality while preserving general capability.
Two-Stream Networks for Object Segmentation in Videos
Aug 08, 2022



Existing matching-based approaches perform video object segmentation (VOS) via retrieving support features from a pixel-level memory, while some pixels may suffer from lack of correspondence in the memory (i.e., unseen), which inevitably limits their segmentation performance. In this paper, we present a Two-Stream Network (TSN). Our TSN includes (i) a pixel stream with a conventional pixel-level memory, to segment the seen pixels based on their pixellevel memory retrieval. (ii) an instance stream for the unseen pixels, where a holistic understanding of the instance is obtained with dynamic segmentation heads conditioned on the features of the target instance. (iii) a pixel division module generating a routing map, with which output embeddings of the two streams are fused together. The compact instance stream effectively improves the segmentation accuracy of the unseen pixels, while fusing two streams with the adaptive routing map leads to an overall performance boost. Through extensive experiments, we demonstrate the effectiveness of our proposed TSN, and we also report state-of-the-art performance of 86.1% on YouTube-VOS 2018 and 87.5% on the DAVIS-2017 validation split.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020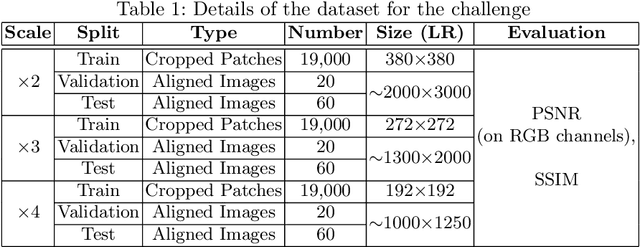
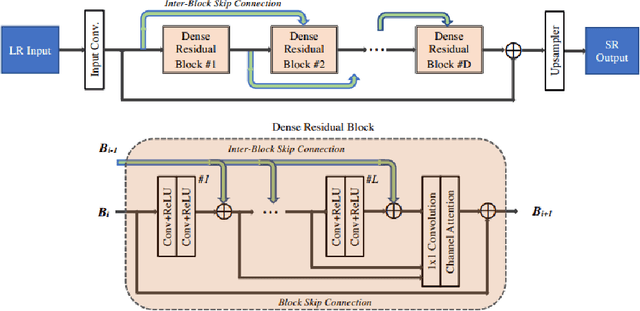
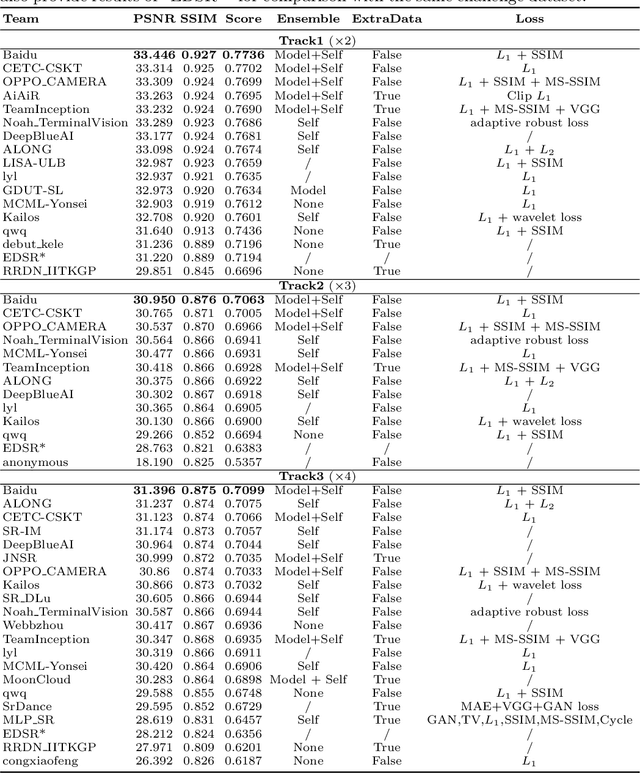
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
Component Divide-and-Conquer for Real-World Image Super-Resolution
Aug 05, 2020In this paper, we present a large-scale Diverse Real-world image Super-Resolution dataset, i.e., DRealSR, as well as a divide-and-conquer Super-Resolution (SR) network, exploring the utility of guiding SR model with low-level image components. DRealSR establishes a new SR benchmark with diverse real-world degradation processes, mitigating the limitations of conventional simulated image degradation. In general, the targets of SR vary with image regions with different low-level image components, e.g., smoothness preserving for flat regions, sharpening for edges, and detail enhancing for textures. Learning an SR model with conventional pixel-wise loss usually is easily dominated by flat regions and edges, and fails to infer realistic details of complex textures. We propose a Component Divide-and-Conquer (CDC) model and a Gradient-Weighted (GW) loss for SR. Our CDC parses an image with three components, employs three Component-Attentive Blocks (CABs) to learn attentive masks and intermediate SR predictions with an intermediate supervision learning strategy, and trains an SR model following a divide-and-conquer learning principle. Our GW loss also provides a feasible way to balance the difficulties of image components for SR. Extensive experiments validate the superior performance of our CDC and the challenging aspects of our DRealSR dataset related to diverse real-world scenarios. Our dataset and codes are publicly available at https://github.com/xiezw5/Component-Divide-and-Conquer-for-Real-World-Image-Super-Resolution
Blind Super-Resolution With Iterative Kernel Correction
Apr 06, 2019
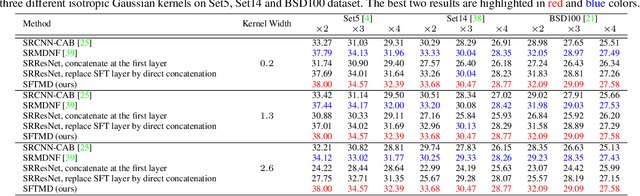
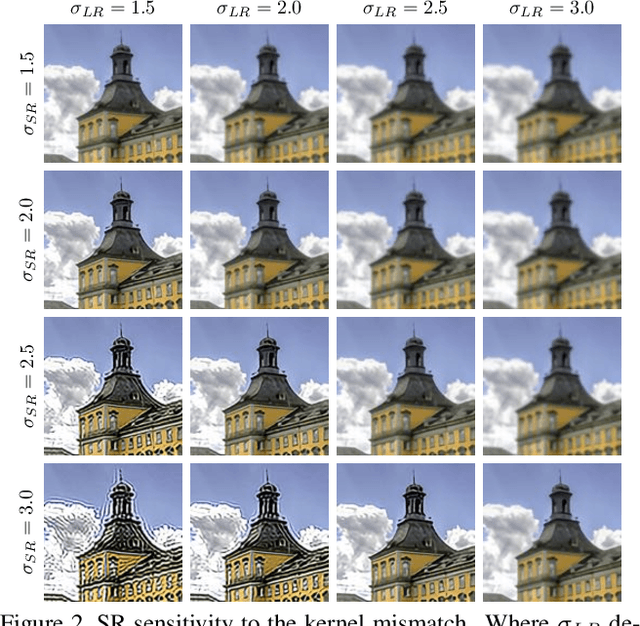
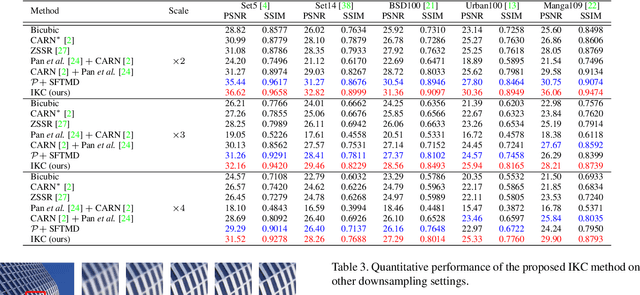
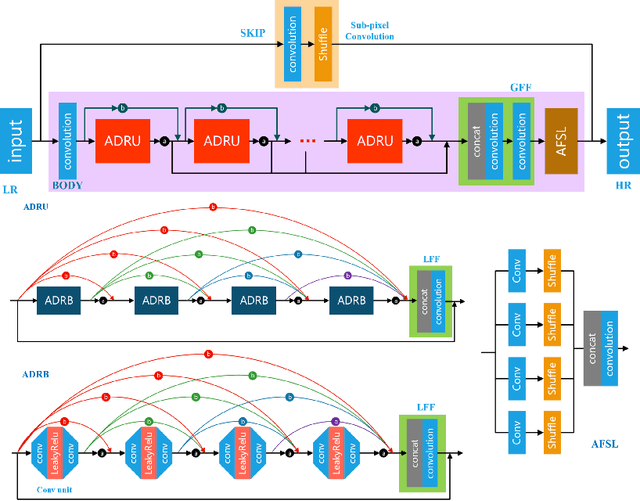
Deep learning based methods have dominated super-resolution (SR) field due to their remarkable performance in terms of effectiveness and efficiency. Most of these methods assume that the blur kernel during downsampling is predefined/known (e.g., bicubic). However, the blur kernels involved in real applications are complicated and unknown, resulting in severe performance drop for the advanced SR methods. In this paper, we propose an Iterative Kernel Correction (IKC) method for blur kernel estimation in blind SR problem, where the blur kernels are unknown. We draw the observation that kernel mismatch could bring regular artifacts (either over-sharpening or over-smoothing), which can be applied to correct inaccurate blur kernels. Thus we introduce an iterative correction scheme -- IKC that achieves better results than direct kernel estimation. We further propose an effective SR network architecture using spatial feature transform (SFT) layers to handle multiple blur kernels, named SFTMD. Extensive experiments on synthetic and real-world images show that the proposed IKC method with SFTMD can provide visually favorable SR results and the state-of-the-art performance in blind SR problem.