 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-Local Collaborative Inference with LLM for Lidar-Based Open-Vocabulary Detection
Jul 12, 2024Open-Vocabulary Detection (OVD) is the task of detecting all interesting objects in a given scene without predefined object classes. Extensive work has been done to deal with the OVD for 2D RGB images, but the exploration of 3D OVD is still limited. Intuitively, lidar point clouds provide 3D information, both object level and scene level, to generate trustful detection results. However, previous lidar-based OVD methods only focus on the usage of object-level features, ignoring the essence of scene-level information. In this paper, we propose a Global-Local Collaborative Scheme (GLIS) for the lidar-based OVD task, which contains a local branch to generate object-level detection result and a global branch to obtain scene-level global feature. With the global-local information, a Large Language Model (LLM) is applied for chain-of-thought inference, and the detection result can be refined accordingly. We further propose Reflected Pseudo Labels Generation (RPLG) to generate high-quality pseudo labels for supervision and Background-Aware Object Localization (BAOL) to select precise object proposals. Extensive experiments on ScanNetV2 and SUN RGB-D demonstrate the superiority of our methods. Code is released at https://github.com/GradiusTwinbee/GLIS.
Eliminating Cross-modal Conflicts in BEV Space for LiDAR-Camera 3D Object Detection
Mar 12, 2024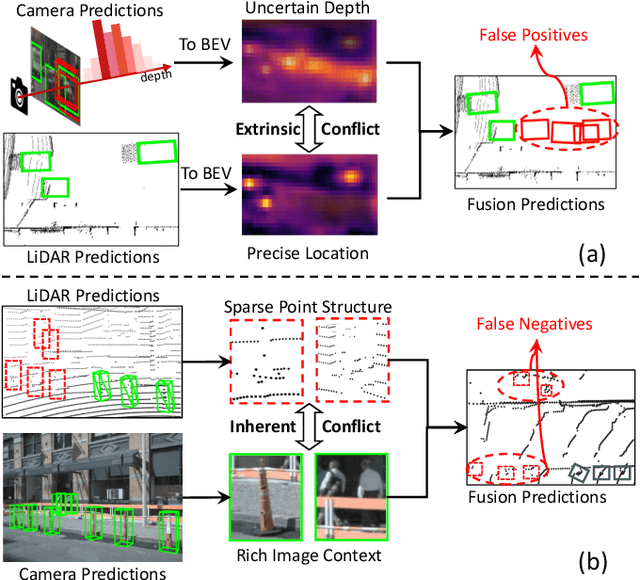
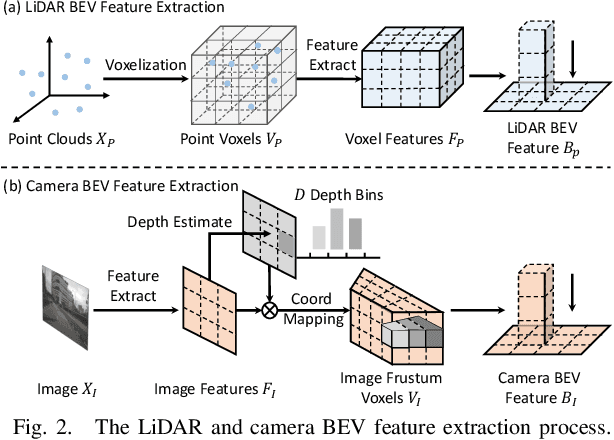
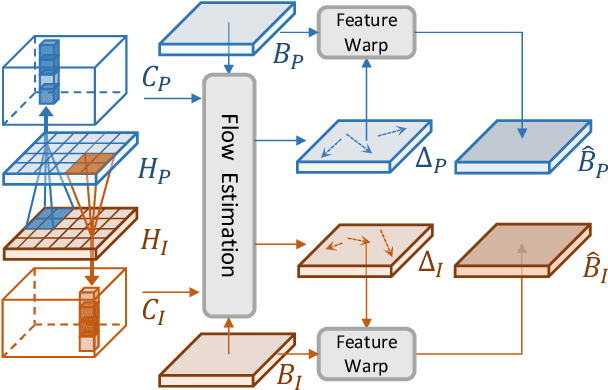
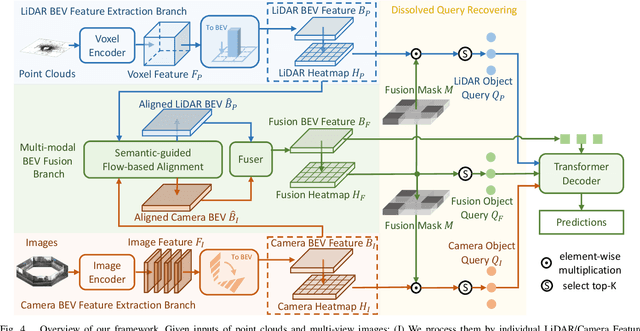
Recent 3D object detectors typically utilize multi-sensor data and unify multi-modal features in the shared bird's-eye view (BEV) representation space. However, our empirical findings indicate that previous methods have limitations in generating fusion BEV features free from cross-modal conflicts. These conflicts encompass extrinsic conflicts caused by BEV feature construction and inherent conflicts stemming from heterogeneous sensor signals. Therefore, we propose a novel Eliminating Conflicts Fusion (ECFusion) method to explicitly eliminate the extrinsic/inherent conflicts in BEV space and produce improved multi-modal BEV features. Specifically, we devise a Semantic-guided Flow-based Alignment (SFA) module to resolve extrinsic conflicts via unifying spatial distribution in BEV space before fusion. Moreover, we design a Dissolved Query Recovering (DQR) mechanism to remedy inherent conflicts by preserving objectness clues that are lost in the fusion BEV feature. In general, our method maximizes the effective information utilization of each modality and leverages inter-modal complementarity. Our method achieves state-of-the-art performance in the highly competitive nuScenes 3D object detection dataset. The code is released at https://github.com/fjhzhixi/ECFusion.
Two-Stream Networks for Object Segmentation in Videos
Aug 08, 2022



Existing matching-based approaches perform video object segmentation (VOS) via retrieving support features from a pixel-level memory, while some pixels may suffer from lack of correspondence in the memory (i.e., unseen), which inevitably limits their segmentation performance. In this paper, we present a Two-Stream Network (TSN). Our TSN includes (i) a pixel stream with a conventional pixel-level memory, to segment the seen pixels based on their pixellevel memory retrieval. (ii) an instance stream for the unseen pixels, where a holistic understanding of the instance is obtained with dynamic segmentation heads conditioned on the features of the target instance. (iii) a pixel division module generating a routing map, with which output embeddings of the two streams are fused together. The compact instance stream effectively improves the segmentation accuracy of the unseen pixels, while fusing two streams with the adaptive routing map leads to an overall performance boost. Through extensive experiments, we demonstrate the effectiveness of our proposed TSN, and we also report state-of-the-art performance of 86.1% on YouTube-VOS 2018 and 87.5% on the DAVIS-2017 validation split.
Target-Driven Structured Transformer Planner for Vision-Language Navigation
Jul 19, 2022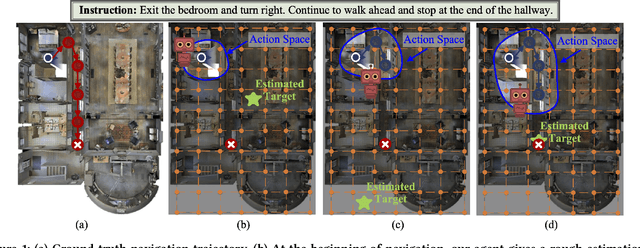
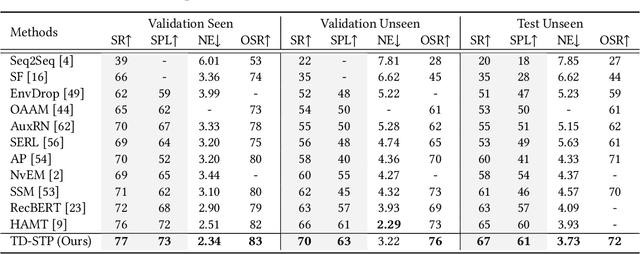

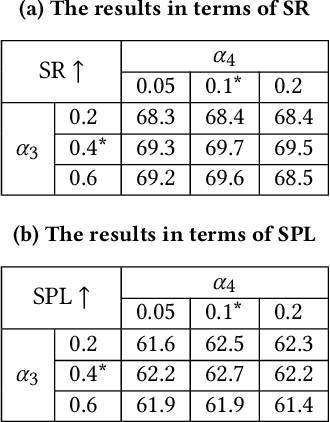
Vision-language navigation is the task of directing an embodied agent to navigate in 3D scenes with natural language instructions. For the agent, inferring the long-term navigation target from visual-linguistic clues is crucial for reliable path planning, which, however, has rarely been studied before in literature. In this article, we propose a Target-Driven Structured Transformer Planner (TD-STP) for long-horizon goal-guided and room layout-aware navigation. Specifically, we devise an Imaginary Scene Tokenization mechanism for explicit estimation of the long-term target (even located in unexplored environments). In addition, we design a Structured Transformer Planner which elegantly incorporates the explored room layout into a neural attention architecture for structured and global planning. Experimental results demonstrate that our TD-STP substantially improves previous best methods' success rate by 2% and 5% on the test set of R2R and REVERIE benchmarks, respectively. Our code is available at https://github.com/YushengZhao/TD-STP .
CenterMask: single shot instance segmentation with point representation
Apr 11, 2020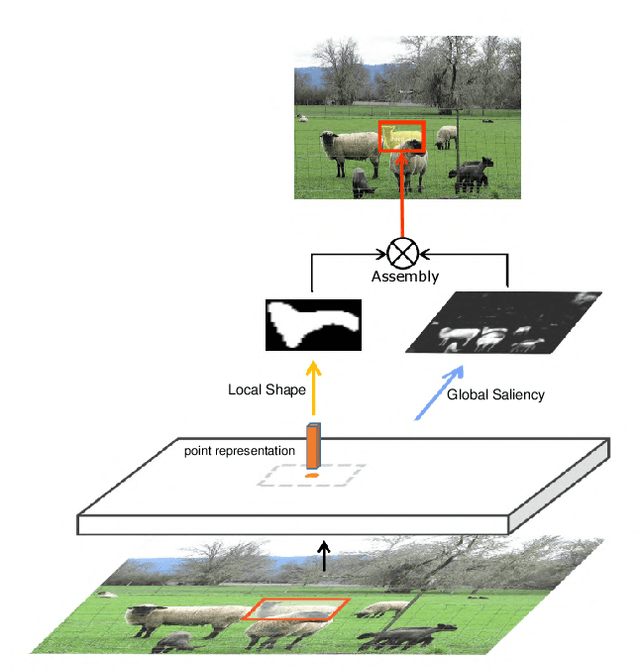


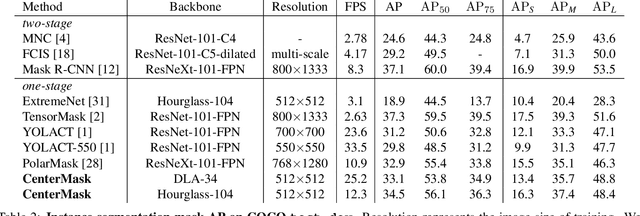
In this paper, we propose a single-shot instance segmentation method, which is simple, fast and accurate. There are two main challenges for one-stage instance segmentation: object instances differentiation and pixel-wise feature alignment. Accordingly, we decompose the instance segmentation into two parallel subtasks: Local Shape prediction that separates instances even in overlapping conditions, and Global Saliency generation that segments the whole image in a pixel-to-pixel manner. The outputs of the two branches are assembled to form the final instance masks. To realize that, the local shape information is adopted from the representation of object center points. Totally trained from scratch and without any bells and whistles, the proposed CenterMask achieves 34.5 mask AP with a speed of 12.3 fps, using a single-model with single-scale training/testing on the challenging COCO dataset. The accuracy is higher than all other one-stage instance segmentation methods except the 5 times slower TensorMask, which shows the effectiveness of CenterMask. Besides, our method can be easily embedded to other one-stage object detectors such as FCOS and performs well, showing the generalization of CenterMask.
Selective Sampling and Mixture Models in Generative Adversarial Networks
Feb 02, 2018
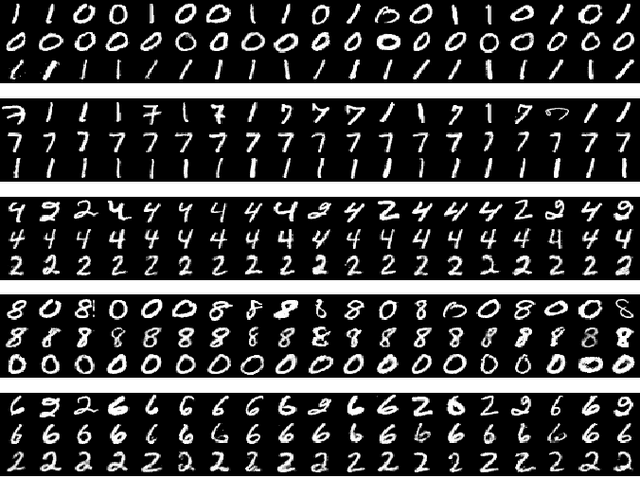

In this paper, we propose a multi-generator extension to the adversarial training framework, in which the objective of each generator is to represent a unique component of a target mixture distribution. In the training phase, the generators cooperate to represent, as a mixture, the target distribution while maintaining distinct manifolds. As opposed to traditional generative models, inference from a particular generator after training resembles selective sampling from a unique component in the target distribution. We demonstrate the feasibility of the proposed architecture both analytically and with basic Multi-Layer Perceptron (MLP) models trained on the MNIST dataset.