 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariation-based Cause Effect Identification
Nov 22, 2022


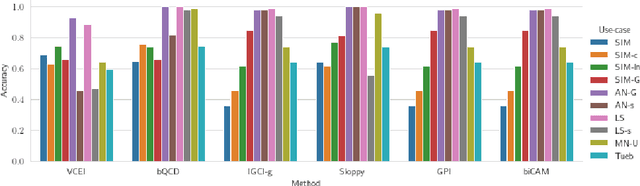
Mining genuine mechanisms underlying the complex data generation process in real-world systems is a fundamental step in promoting interpretability of, and thus trust in, data-driven models. Therefore, we propose a variation-based cause effect identification (VCEI) framework for causal discovery in bivariate systems from a single observational setting. Our framework relies on the principle of independence of cause and mechanism (ICM) under the assumption of an existing acyclic causal link, and offers a practical realization of this principle. Principally, we artificially construct two settings in which the marginal distributions of one covariate, claimed to be the cause, are guaranteed to have non-negligible variations. This is achieved by re-weighting samples of the marginal so that the resultant distribution is notably distinct from this marginal according to some discrepancy measure. In the causal direction, such variations are expected to have no impact on the effect generation mechanism. Therefore, quantifying the impact of these variations on the conditionals reveals the genuine causal direction. Moreover, we formulate our approach in the kernel-based maximum mean discrepancy, lifting all constraints on the data types of cause-and-effect covariates, and rendering such artificial interventions a convex optimization problem. We provide a series of experiments on real and synthetic data showing that VCEI is, in principle, competitive to other cause effect identification frameworks.
Neural Network Ensembles to Real-time Identification of Plug-level Appliance Measurements
Feb 20, 2018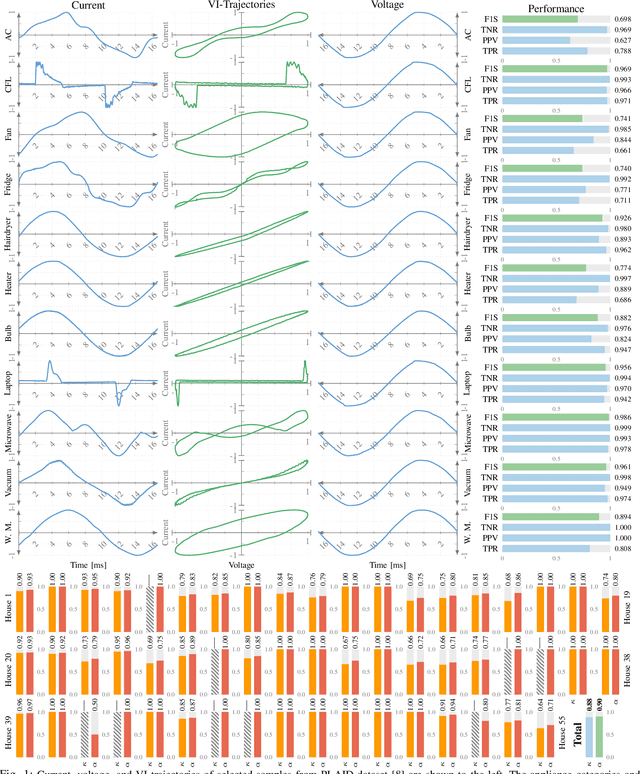
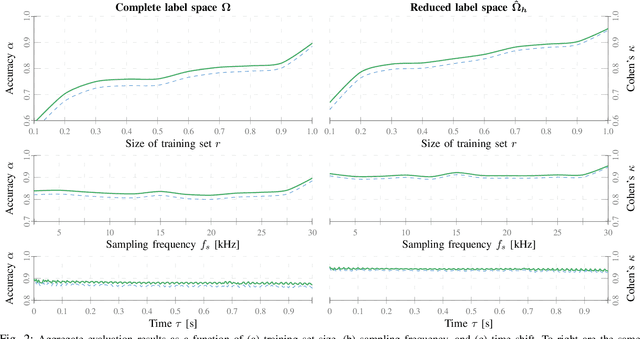
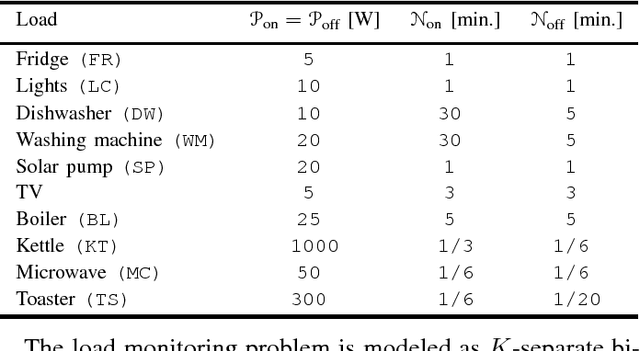
The problem of identifying end-use electrical appliances from their individual consumption profiles, known as the appliance identification problem, is a primary stage in both Non-Intrusive Load Monitoring (NILM) and automated plug-wise metering. Therefore, appliance identification has received dedicated studies with various electric appliance signatures, classification models, and evaluation datasets. In this paper, we propose a neural network ensembles approach to address this problem using high resolution measurements. The models are trained on the raw current and voltage waveforms, and thus, eliminating the need for well engineered appliance signatures. We evaluate the proposed model on a publicly available appliance dataset from 55 residential buildings, 11 appliance categories, and over 1000 measurements. We further study the stability of the trained models with respect to training dataset, sampling frequency, and variations in the steady-state operation of appliances.
On the Feasibility of Generic Deep Disaggregation for Single-Load Extraction
Feb 05, 2018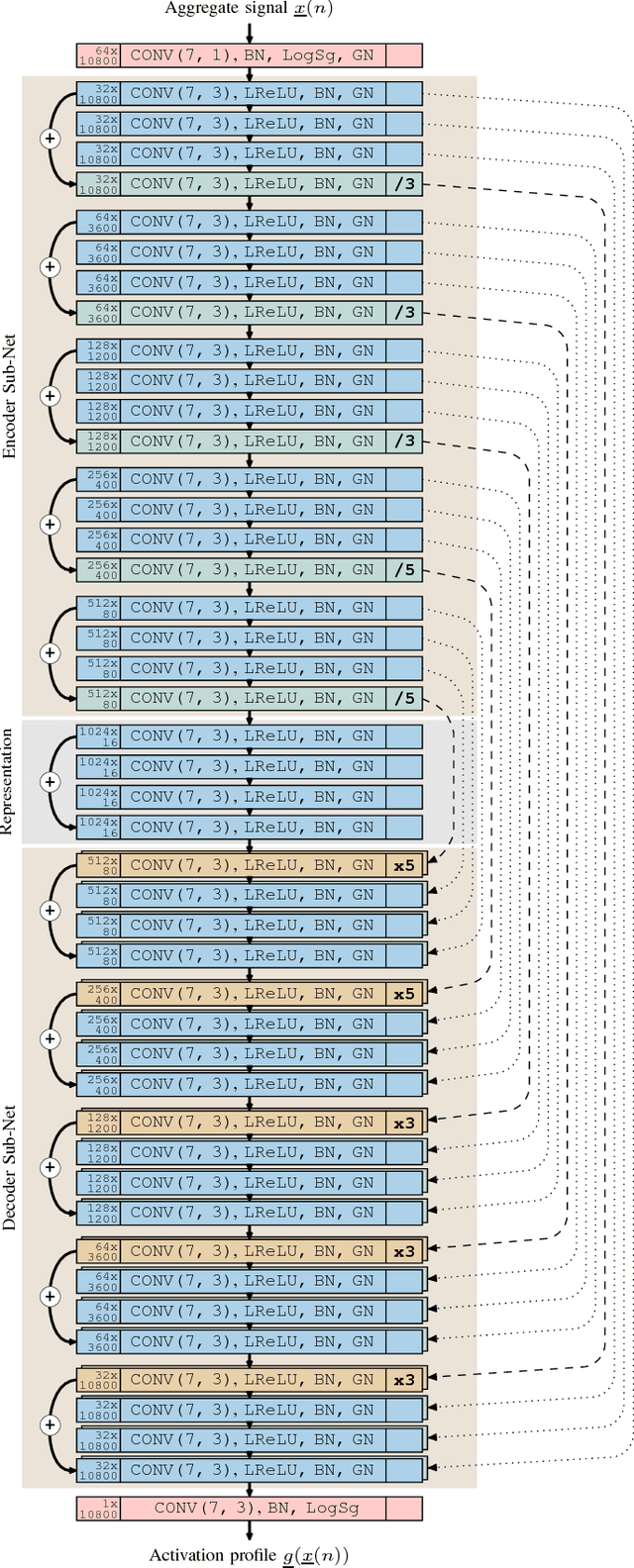
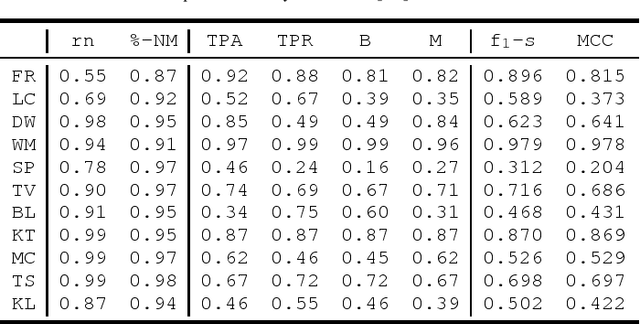
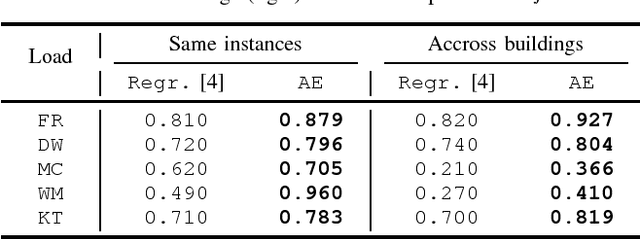
Recently, and with the growing development of big energy datasets, data-driven learning techniques began to represent a potential solution to the energy disaggregation problem outperforming engineered and hand-crafted models. However, most proposed deep disaggregation models are load-dependent in the sense that either expert knowledge or a hyper-parameter optimization stage is required prior to training and deployment (normally for each load category) even upon acquisition and cleansing of aggregate and sub-metered data. In this paper, we present a feasibility study on the development of a generic disaggregation model based on data-driven learning. Specifically, we present a generic deep disaggregation model capable of achieving state-of-art performance in load monitoring for a variety of load categories. The developed model is evaluated on the publicly available UK-DALE dataset with a moderately low sampling frequency and various domestic loads.
Selective Sampling and Mixture Models in Generative Adversarial Networks
Feb 02, 2018
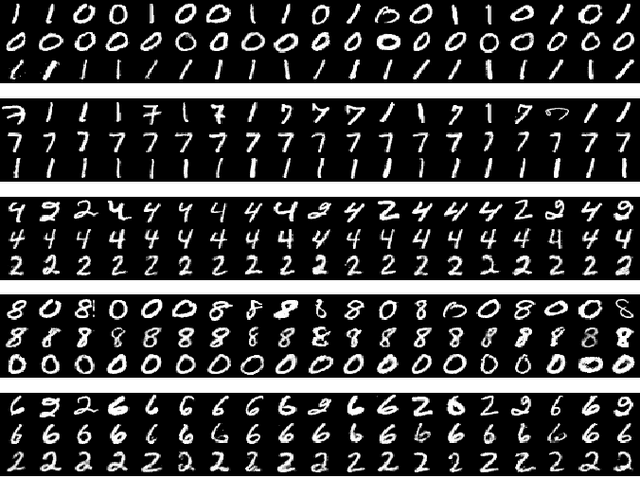

In this paper, we propose a multi-generator extension to the adversarial training framework, in which the objective of each generator is to represent a unique component of a target mixture distribution. In the training phase, the generators cooperate to represent, as a mixture, the target distribution while maintaining distinct manifolds. As opposed to traditional generative models, inference from a particular generator after training resembles selective sampling from a unique component in the target distribution. We demonstrate the feasibility of the proposed architecture both analytically and with basic Multi-Layer Perceptron (MLP) models trained on the MNIST dataset.