 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLRD: Global-Local Collaborative Reason and Debate with PSL for 3D Open-Vocabulary Detection
Mar 26, 2025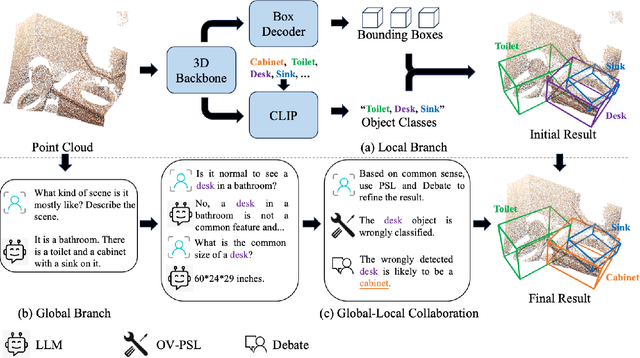
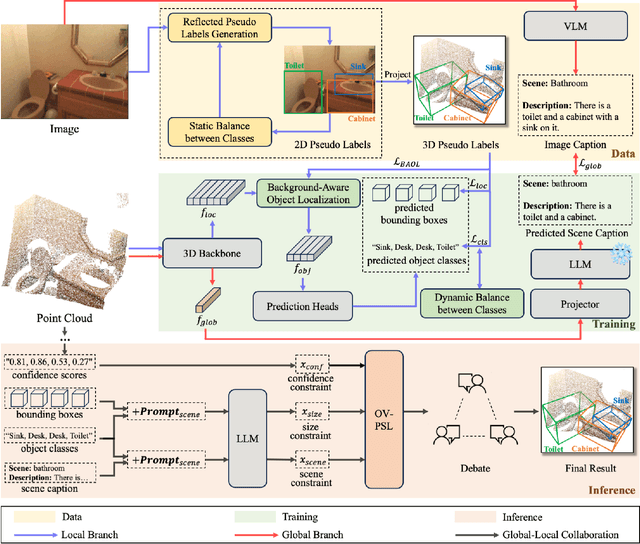
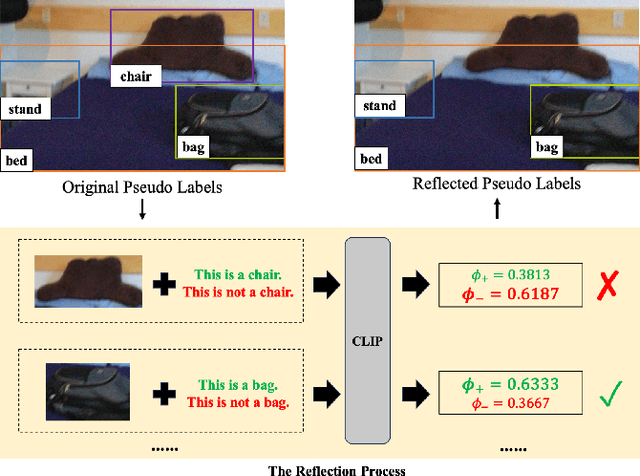
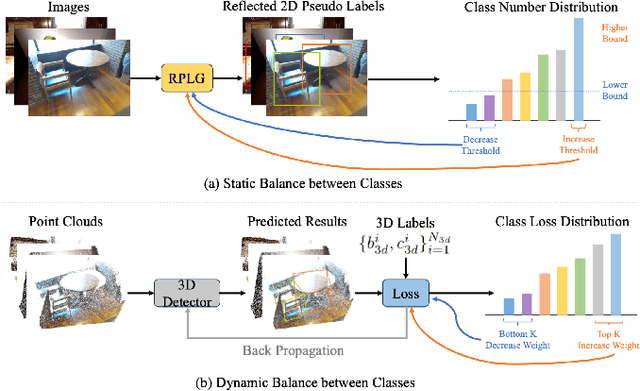
The task of LiDAR-based 3D Open-Vocabulary Detection (3D OVD) requires the detector to learn to detect novel objects from point clouds without off-the-shelf training labels. Previous methods focus on the learning of object-level representations and ignore the scene-level information, thus it is hard to distinguish objects with similar classes. In this work, we propose a Global-Local Collaborative Reason and Debate with PSL (GLRD) framework for the 3D OVD task, considering both local object-level information and global scene-level information. Specifically, LLM is utilized to perform common sense reasoning based on object-level and scene-level information, where the detection result is refined accordingly. To further boost the LLM's ability of precise decisions, we also design a probabilistic soft logic solver (OV-PSL) to search for the optimal solution, and a debate scheme to confirm the class of confusable objects. In addition, to alleviate the uneven distribution of classes, a static balance scheme (SBC) and a dynamic balance scheme (DBC) are designed. In addition, to reduce the influence of noise in data and training, we further propose Reflected Pseudo Labels Generation (RPLG) and Background-Aware Object Localization (BAOL). Extensive experiments conducted on ScanNet and SUN RGB-D demonstrate the superiority of GLRD, where absolute improvements in mean average precision are $+2.82\%$ on SUN RGB-D and $+3.72\%$ on ScanNet in the partial open-vocabulary setting. In the full open-vocabulary setting, the absolute improvements in mean average precision are $+4.03\%$ on ScanNet and $+14.11\%$ on SUN RGB-D.
Target-Driven Structured Transformer Planner for Vision-Language Navigation
Jul 19, 2022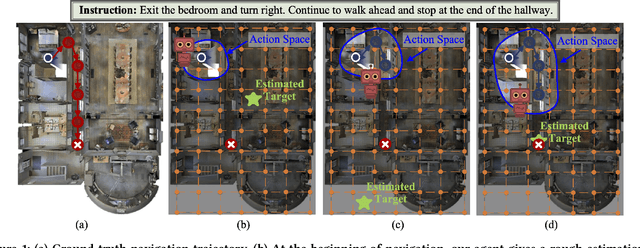
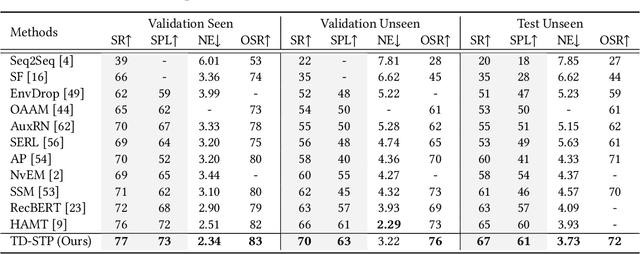

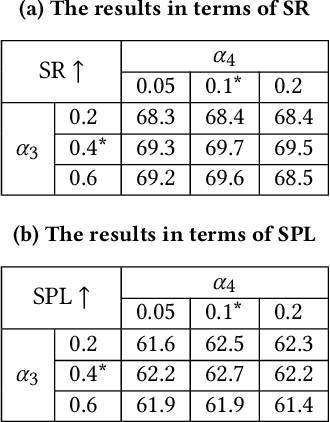
Vision-language navigation is the task of directing an embodied agent to navigate in 3D scenes with natural language instructions. For the agent, inferring the long-term navigation target from visual-linguistic clues is crucial for reliable path planning, which, however, has rarely been studied before in literature. In this article, we propose a Target-Driven Structured Transformer Planner (TD-STP) for long-horizon goal-guided and room layout-aware navigation. Specifically, we devise an Imaginary Scene Tokenization mechanism for explicit estimation of the long-term target (even located in unexplored environments). In addition, we design a Structured Transformer Planner which elegantly incorporates the explored room layout into a neural attention architecture for structured and global planning. Experimental results demonstrate that our TD-STP substantially improves previous best methods' success rate by 2% and 5% on the test set of R2R and REVERIE benchmarks, respectively. Our code is available at https://github.com/YushengZhao/TD-STP .
3D-SPS: Single-Stage 3D Visual Grounding via Referred Point Progressive Selection
Apr 13, 2022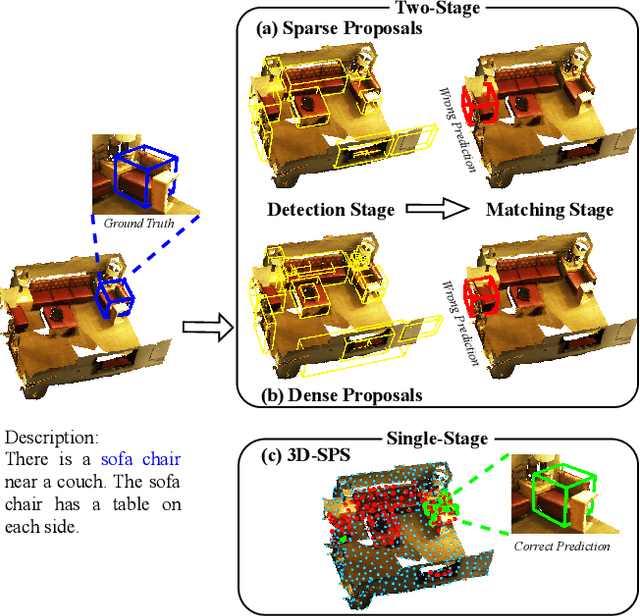
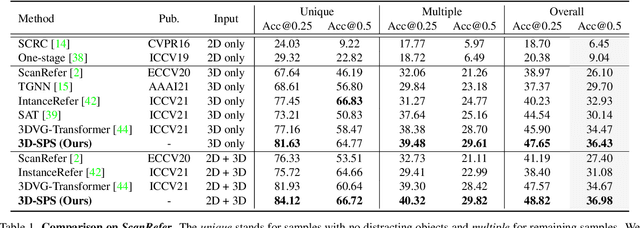
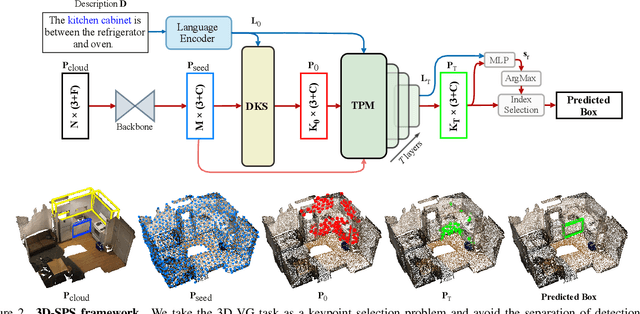
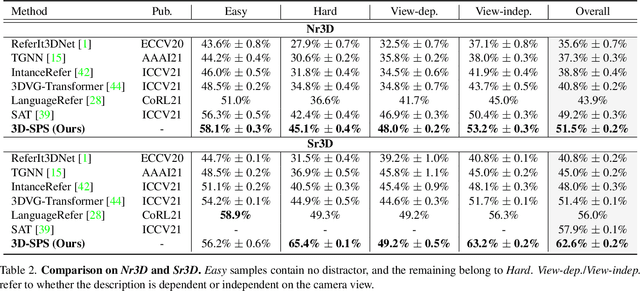
3D visual grounding aims to locate the referred target object in 3D point cloud scenes according to a free-form language description. Previous methods mostly follow a two-stage paradigm, i.e., language-irrelevant detection and cross-modal matching, which is limited by the isolated architecture. In such a paradigm, the detector needs to sample keypoints from raw point clouds due to the inherent properties of 3D point clouds (irregular and large-scale), to generate the corresponding object proposal for each keypoint. However, sparse proposals may leave out the target in detection, while dense proposals may confuse the matching model. Moreover, the language-irrelevant detection stage can only sample a small proportion of keypoints on the target, deteriorating the target prediction. In this paper, we propose a 3D Single-Stage Referred Point Progressive Selection (3D-SPS) method, which progressively selects keypoints with the guidance of language and directly locates the target. Specifically, we propose a Description-aware Keypoint Sampling (DKS) module to coarsely focus on the points of language-relevant objects, which are significant clues for grounding. Besides, we devise a Target-oriented Progressive Mining (TPM) module to finely concentrate on the points of the target, which is enabled by progressive intra-modal relation modeling and inter-modal target mining. 3D-SPS bridges the gap between detection and matching in the 3D visual grounding task, localizing the target at a single stage. Experiments demonstrate that 3D-SPS achieves state-of-the-art performance on both ScanRefer and Nr3D/Sr3D datasets.
Twins: Revisiting the Design of Spatial Attention in Vision Transformers
May 11, 2021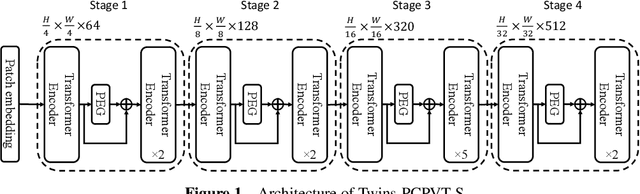
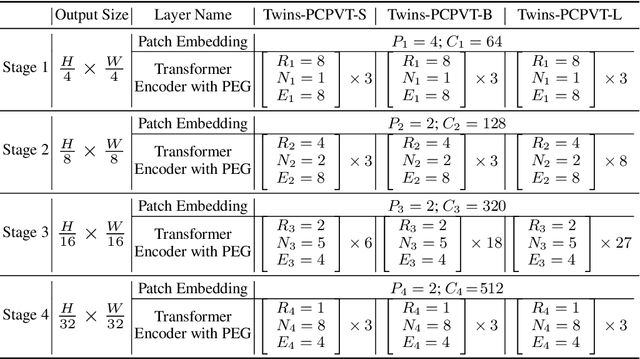
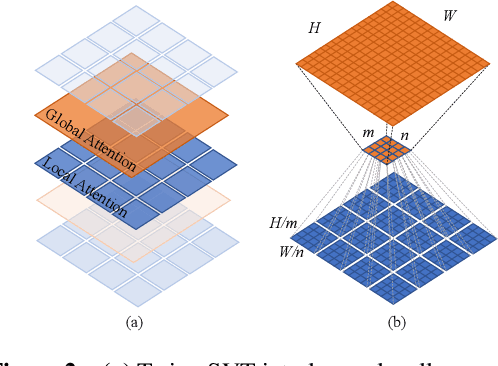
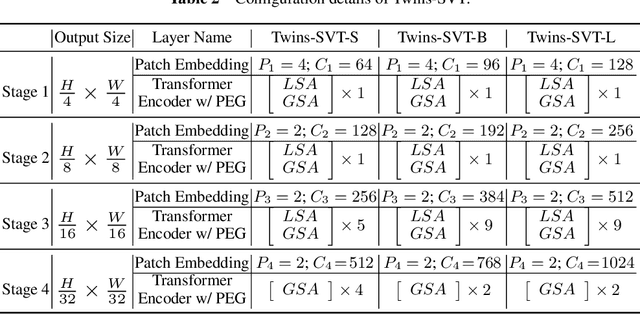
Very recently, a variety of vision transformer architectures for dense prediction tasks have been proposed and they show that the design of spatial attention is critical to their success in these tasks. In this work, we revisit the design of the spatial attention and demonstrate that a carefully-devised yet simple spatial attention mechanism performs favourably against the state-of-the-art schemes. As a result, we propose two vision transformer architectures, namely, Twins-PCPVT and Twins-SVT. Our proposed architectures are highly-efficient and easy to implement, only involving matrix multiplications that are highly optimized in modern deep learning frameworks. More importantly, the proposed architectures achieve excellent performance on a wide range of visual tasks including imagelevel classification as well as dense detection and segmentation. The simplicity and strong performance suggest that our proposed architectures may serve as stronger backbones for many vision tasks. Our code will be released soon at https://github.com/Meituan-AutoML/Twins .
Conditional Positional Encodings for Vision Transformers
Mar 18, 2021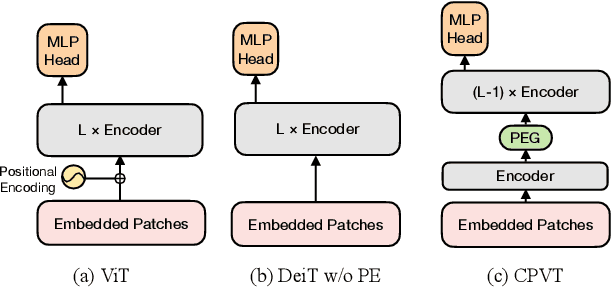
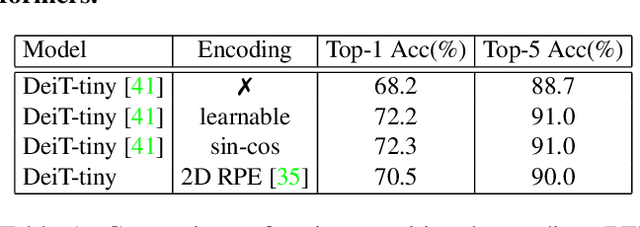
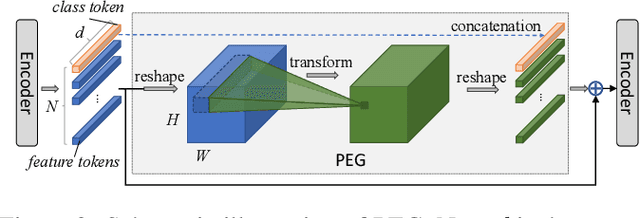
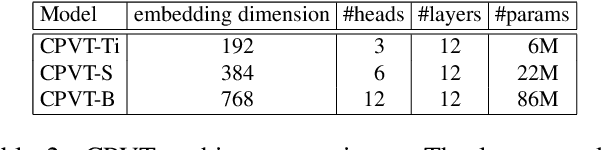
We propose a conditional positional encoding (CPE) scheme for vision Transformers. Unlike previous fixed or learnable positional encodings, which are pre-defined and independent of input tokens, CPE is dynamically generated and conditioned on the local neighborhood of the input tokens. As a result, CPE can easily generalize to the input sequences that are longer than what the model has ever seen during training. Besides, CPE can keep the desired translation-invariance in the image classification task, resulting in improved classification accuracy. CPE can be effortlessly implemented with a simple Position Encoding Generator (PEG), and it can be seamlessly incorporated into the current Transformer framework. Built on PEG, we present Conditional Position encoding Vision Transformer (CPVT). We demonstrate that CPVT has visually similar attention maps compared to those with learned positional encodings. Benefit from the conditional positional encoding scheme, we obtain state-of-the-art results on the ImageNet classification task compared with vision Transformers to date. Our code will be made available at https://github.com/Meituan-AutoML/CPVT .
End-to-End Video Instance Segmentation with Transformers
Dec 04, 2020

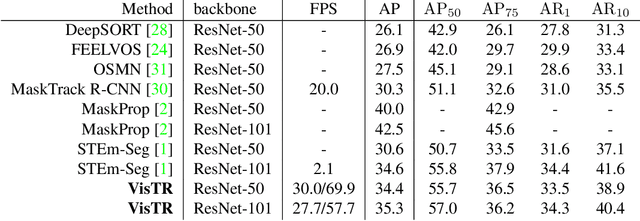

Video instance segmentation (VIS) is the task that requires simultaneously classifying, segmenting and tracking object instances of interest in video. Recent methods typically develop sophisticated pipelines to tackle this task. Here, we propose a new video instance segmentation framework built upon Transformers, termed VisTR, which views the VIS task as a direct end-to-end parallel sequence decoding/prediction problem. Given a video clip consisting of multiple image frames as input, VisTR outputs the sequence of masks for each instance in the video in order directly. At the core is a new, effective instance sequence matching and segmentation strategy, which supervises and segments instances at the sequence level as a whole. VisTR frames the instance segmentation and tracking in the same perspective of similarity learning, thus considerably simplifying the overall pipeline and is significantly different from existing approaches. Without bells and whistles, VisTR achieves the highest speed among all existing VIS models, and achieves the best result among methods using single model on the YouTube-VIS dataset. For the first time, we demonstrate a much simpler and faster video instance segmentation framework built upon Transformers, achieving competitive accuracy. We hope that VisTR can motivate future research for more video understanding tasks.
Robust Trajectory Forecasting for Multiple Intelligent Agents in Dynamic Scene
May 27, 2020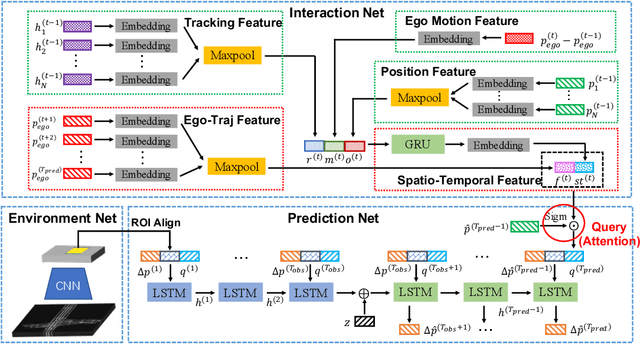
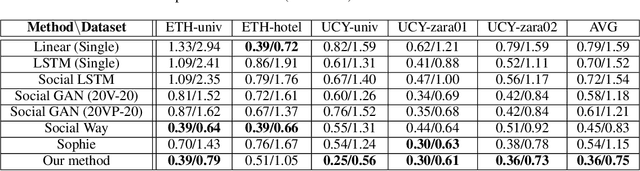
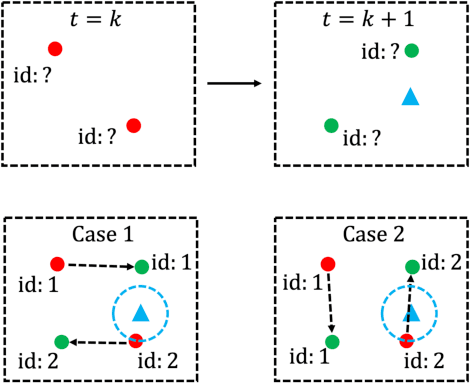
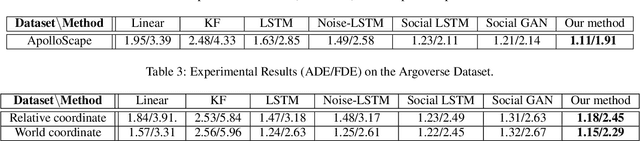
Trajectory forecasting, or trajectory prediction, of multiple interacting agents in dynamic scenes, is an important problem for many applications, such as robotic systems and autonomous driving. The problem is a great challenge because of the complex interactions among the agents and their interactions with the surrounding scenes. In this paper, we present a novel method for the robust trajectory forecasting of multiple intelligent agents in dynamic scenes. The proposed method consists of three major interrelated components: an interaction net for global spatiotemporal interactive feature extraction, an environment net for decoding dynamic scenes (i.e., the surrounding road topology of an agent), and a prediction net that combines the spatiotemporal feature, the scene feature, the past trajectories of agents and some random noise for the robust trajectory prediction of agents. Experiments on pedestrian-walking and vehicle-pedestrian heterogeneous datasets demonstrate that the proposed method outperforms the state-of-the-art prediction methods in terms of prediction accuracy.
VisionNet: A Drivable-space-based Interactive Motion Prediction Network for Autonomous Driving
Jan 08, 2020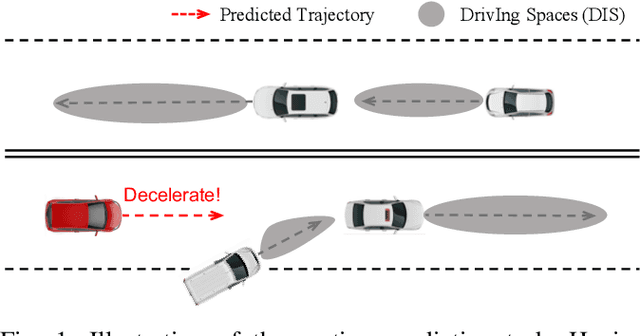
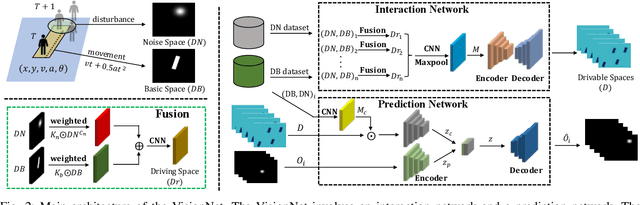
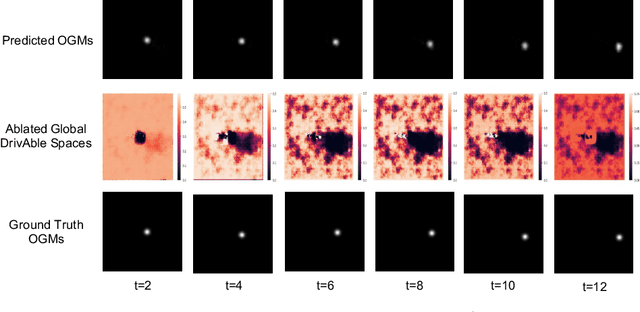
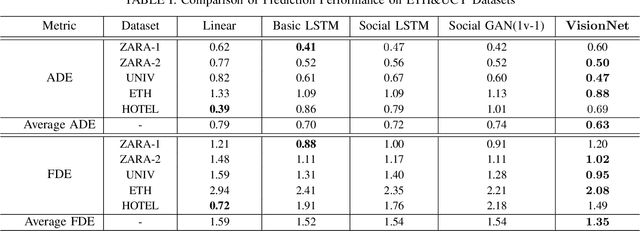
The comprehension of environmental traffic situation largely ensures the driving safety of autonomous vehicles. Recently, the mission has been investigated by plenty of researches, while it is hard to be well addressed due to the limitation of collective influence in complex scenarios. These approaches model the interactions through the spatial relations between the target obstacle and its neighbors. However, they oversimplify the challenge since the training stage of the interactions lacks effective supervision. As a result, these models are far from promising. More intuitively, we transform the problem into calculating the interaction-aware drivable spaces and propose the CNN-based VisionNet for trajectory prediction. The VisionNet accepts a sequence of motion states, i.e., location, velocity, and acceleration, to estimate the future drivable spaces. The reified interactions significantly increase the interpretation ability of the VisionNet and refine the prediction. To further advance the performance, we propose an interactive loss to guide the generation of the drivable spaces. Experiments on multiple public datasets demonstrate the effectiveness of the proposed VisionNet.
StarNet: Pedestrian Trajectory Prediction using Deep Neural Network in Star Topology
Jun 05, 2019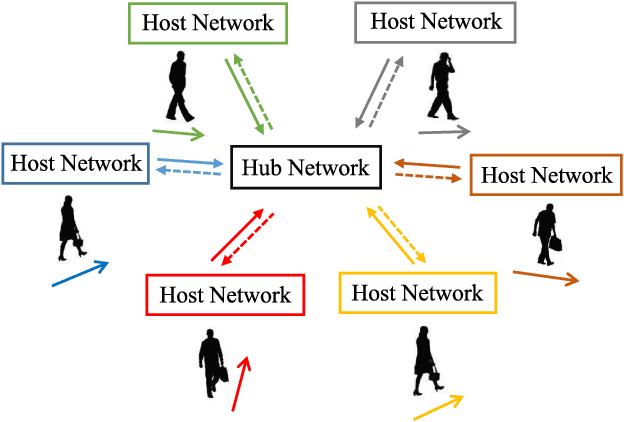
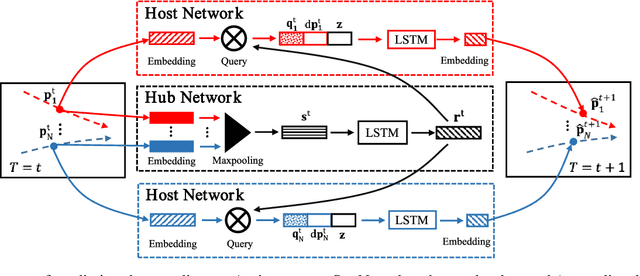
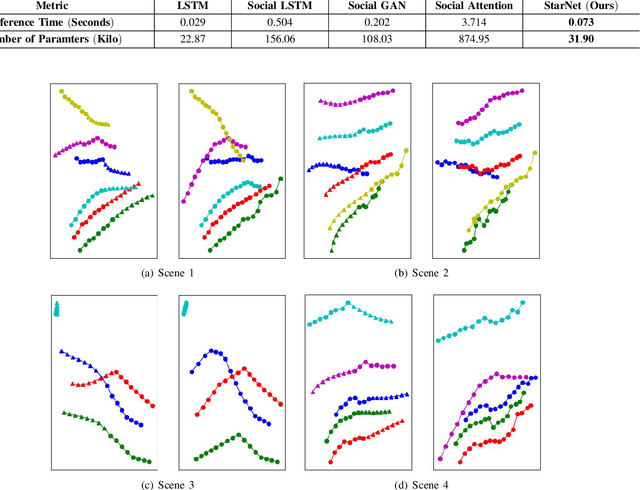
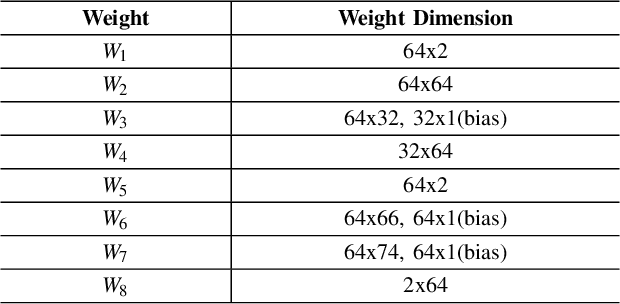
Pedestrian trajectory prediction is crucial for many important applications. This problem is a great challenge because of complicated interactions among pedestrians. Previous methods model only the pairwise interactions between pedestrians, which not only oversimplifies the interactions among pedestrians but also is computationally inefficient. In this paper, we propose a novel model StarNet to deal with these issues. StarNet has a star topology which includes a unique hub network and multiple host networks. The hub network takes observed trajectories of all pedestrians to produce a comprehensive description of the interpersonal interactions. Then the host networks, each of which corresponds to one pedestrian, consult the description and predict future trajectories. The star topology gives StarNet two advantages over conventional models. First, StarNet is able to consider the collective influence among all pedestrians in the hub network, making more accurate predictions. Second, StarNet is computationally efficient since the number of host network is linear to the number of pedestrians. Experiments on multiple public datasets demonstrate that StarNet outperforms multiple state-of-the-arts by a large margin in terms of both accuracy and efficiency.