 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Neural Topological Mapping for Multi-Agent Exploration
Nov 01, 2023



This paper investigates the multi-agent cooperative exploration problem, which requires multiple agents to explore an unseen environment via sensory signals in a limited time. A popular approach to exploration tasks is to combine active mapping with planning. Metric maps capture the details of the spatial representation, but are with high communication traffic and may vary significantly between scenarios, resulting in inferior generalization. Topological maps are a promising alternative as they consist only of nodes and edges with abstract but essential information and are less influenced by the scene structures. However, most existing topology-based exploration tasks utilize classical methods for planning, which are time-consuming and sub-optimal due to their handcrafted design. Deep reinforcement learning (DRL) has shown great potential for learning (near) optimal policies through fast end-to-end inference. In this paper, we propose Multi-Agent Neural Topological Mapping (MANTM) to improve exploration efficiency and generalization for multi-agent exploration tasks. MANTM mainly comprises a Topological Mapper and a novel RL-based Hierarchical Topological Planner (HTP). The Topological Mapper employs a visual encoder and distance-based heuristics to construct a graph containing main nodes and their corresponding ghost nodes. The HTP leverages graph neural networks to capture correlations between agents and graph nodes in a coarse-to-fine manner for effective global goal selection. Extensive experiments conducted in a physically-realistic simulator, Habitat, demonstrate that MANTM reduces the steps by at least 26.40% over planning-based baselines and by at least 7.63% over RL-based competitors in unseen scenarios.
Two-Stream Networks for Object Segmentation in Videos
Aug 08, 2022



Existing matching-based approaches perform video object segmentation (VOS) via retrieving support features from a pixel-level memory, while some pixels may suffer from lack of correspondence in the memory (i.e., unseen), which inevitably limits their segmentation performance. In this paper, we present a Two-Stream Network (TSN). Our TSN includes (i) a pixel stream with a conventional pixel-level memory, to segment the seen pixels based on their pixellevel memory retrieval. (ii) an instance stream for the unseen pixels, where a holistic understanding of the instance is obtained with dynamic segmentation heads conditioned on the features of the target instance. (iii) a pixel division module generating a routing map, with which output embeddings of the two streams are fused together. The compact instance stream effectively improves the segmentation accuracy of the unseen pixels, while fusing two streams with the adaptive routing map leads to an overall performance boost. Through extensive experiments, we demonstrate the effectiveness of our proposed TSN, and we also report state-of-the-art performance of 86.1% on YouTube-VOS 2018 and 87.5% on the DAVIS-2017 validation split.
Target-Driven Structured Transformer Planner for Vision-Language Navigation
Jul 19, 2022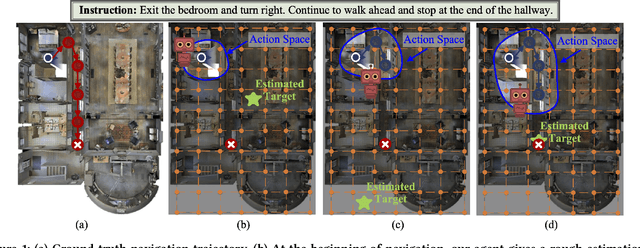
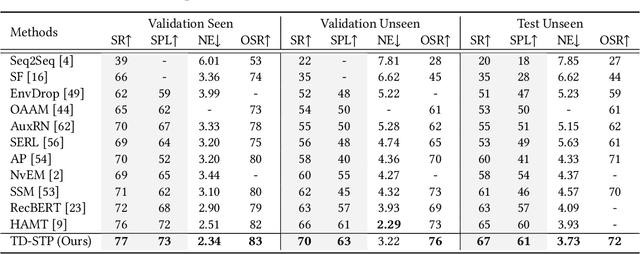

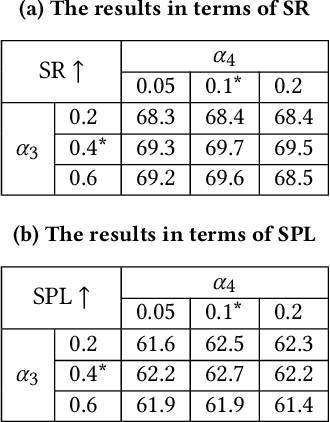
Vision-language navigation is the task of directing an embodied agent to navigate in 3D scenes with natural language instructions. For the agent, inferring the long-term navigation target from visual-linguistic clues is crucial for reliable path planning, which, however, has rarely been studied before in literature. In this article, we propose a Target-Driven Structured Transformer Planner (TD-STP) for long-horizon goal-guided and room layout-aware navigation. Specifically, we devise an Imaginary Scene Tokenization mechanism for explicit estimation of the long-term target (even located in unexplored environments). In addition, we design a Structured Transformer Planner which elegantly incorporates the explored room layout into a neural attention architecture for structured and global planning. Experimental results demonstrate that our TD-STP substantially improves previous best methods' success rate by 2% and 5% on the test set of R2R and REVERIE benchmarks, respectively. Our code is available at https://github.com/YushengZhao/TD-STP .
SideRT: A Real-time Pure Transformer Architecture for Single Image Depth Estimation
Apr 29, 2022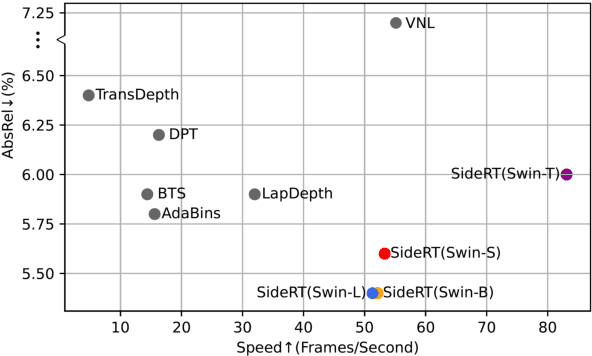
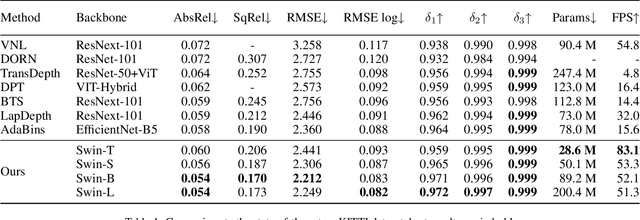
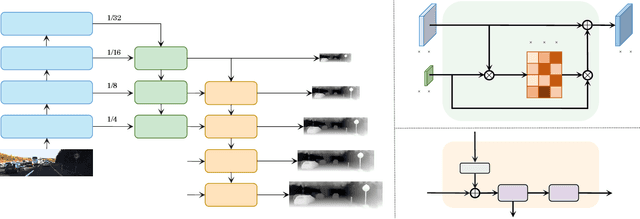
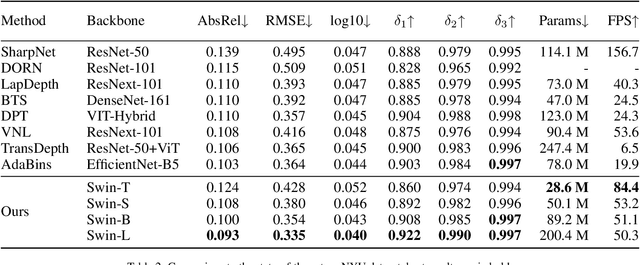
Since context modeling is critical for estimating depth from a single image, researchers put tremendous effort into obtaining global context. Many global manipulations are designed for traditional CNN-based architectures to overcome the locality of convolutions. Attention mechanisms or transformers originally designed for capturing long-range dependencies might be a better choice, but usually complicates architectures and could lead to a decrease in inference speed. In this work, we propose a pure transformer architecture called SideRT that can attain excellent predictions in real-time. In order to capture better global context, Cross-Scale Attention (CSA) and Multi-Scale Refinement (MSR) modules are designed to work collaboratively to fuse features of different scales efficiently. CSA modules focus on fusing features of high semantic similarities, while MSR modules aim to fuse features at corresponding positions. These two modules contain a few learnable parameters without convolutions, based on which a lightweight yet effective model is built. This architecture achieves state-of-the-art performances in real-time (51.3 FPS) and becomes much faster with a reasonable performance drop on a smaller backbone Swin-T (83.1 FPS). Furthermore, its performance surpasses the previous state-of-the-art by a large margin, improving AbsRel metric 6.9% on KITTI and 9.7% on NYU. To the best of our knowledge, this is the first work to show that transformer-based networks can attain state-of-the-art performance in real-time in the single image depth estimation field. Code will be made available soon.
3D-SPS: Single-Stage 3D Visual Grounding via Referred Point Progressive Selection
Apr 13, 2022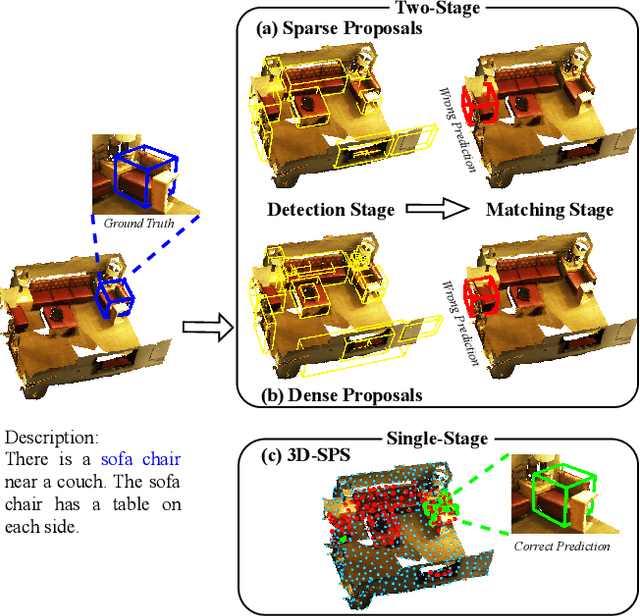
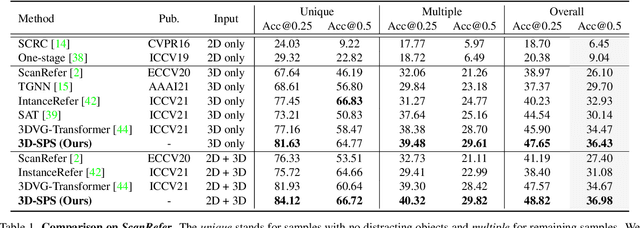
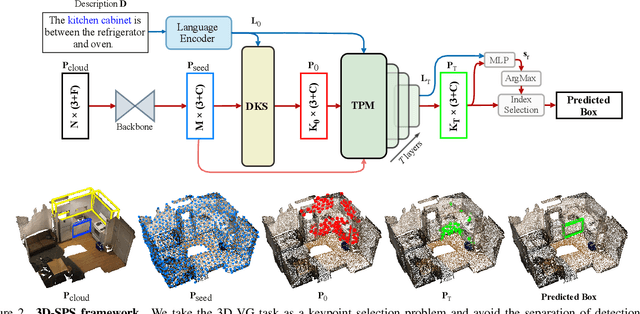
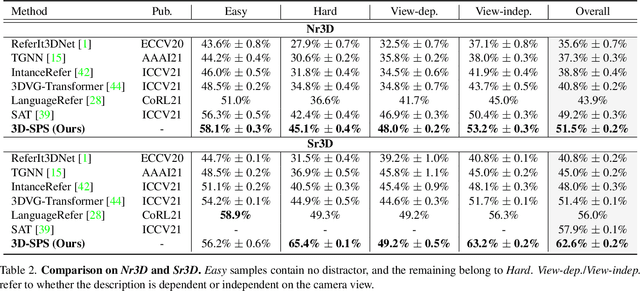
3D visual grounding aims to locate the referred target object in 3D point cloud scenes according to a free-form language description. Previous methods mostly follow a two-stage paradigm, i.e., language-irrelevant detection and cross-modal matching, which is limited by the isolated architecture. In such a paradigm, the detector needs to sample keypoints from raw point clouds due to the inherent properties of 3D point clouds (irregular and large-scale), to generate the corresponding object proposal for each keypoint. However, sparse proposals may leave out the target in detection, while dense proposals may confuse the matching model. Moreover, the language-irrelevant detection stage can only sample a small proportion of keypoints on the target, deteriorating the target prediction. In this paper, we propose a 3D Single-Stage Referred Point Progressive Selection (3D-SPS) method, which progressively selects keypoints with the guidance of language and directly locates the target. Specifically, we propose a Description-aware Keypoint Sampling (DKS) module to coarsely focus on the points of language-relevant objects, which are significant clues for grounding. Besides, we devise a Target-oriented Progressive Mining (TPM) module to finely concentrate on the points of the target, which is enabled by progressive intra-modal relation modeling and inter-modal target mining. 3D-SPS bridges the gap between detection and matching in the 3D visual grounding task, localizing the target at a single stage. Experiments demonstrate that 3D-SPS achieves state-of-the-art performance on both ScanRefer and Nr3D/Sr3D datasets.
PromptDet: Expand Your Detector Vocabulary with Uncurated Images
Mar 30, 2022

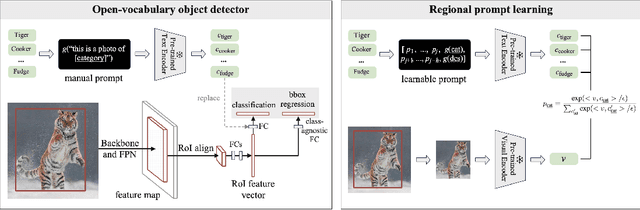

The goal of this work is to establish a scalable pipeline for expanding an object detector towards novel/unseen categories, using zero manual annotations. To achieve that, we make the following four contributions: (i) in pursuit of generalisation, we propose a two-stage open-vocabulary object detector that categorises each box proposal by a classifier generated from the text encoder of a pre-trained visual-language model; (ii) To pair the visual latent space (from RPN box proposal) with that of the pre-trained text encoder, we propose the idea of regional prompt learning to optimise a couple of learnable prompt vectors, converting the textual embedding space to fit those visually object-centric images; (iii) To scale up the learning procedure towards detecting a wider spectrum of objects, we exploit the available online resource, iteratively updating the prompts, and later self-training the proposed detector with pseudo labels generated on a large corpus of noisy, uncurated web images. The self-trained detector, termed as PromptDet, significantly improves the detection performance on categories for which manual annotations are unavailable or hard to obtain, e.g. rare categories. Finally, (iv) to validate the necessity of our proposed components, we conduct extensive experiments on the challenging LVIS and MS-COCO dataset, showing superior performance over existing approaches with fewer additional training images and zero manual annotations whatsoever. Project page with code: https://fcjian.github.io/promptdet.
Twins: Revisiting the Design of Spatial Attention in Vision Transformers
May 11, 2021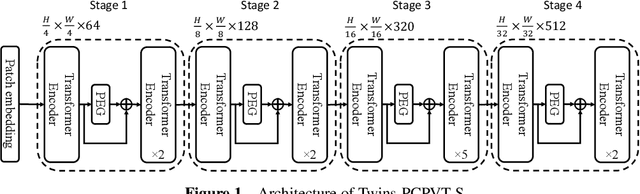
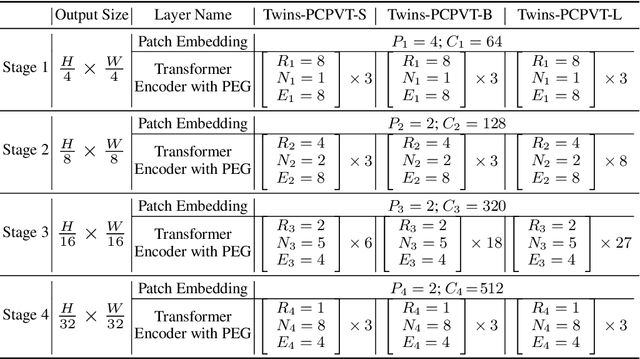
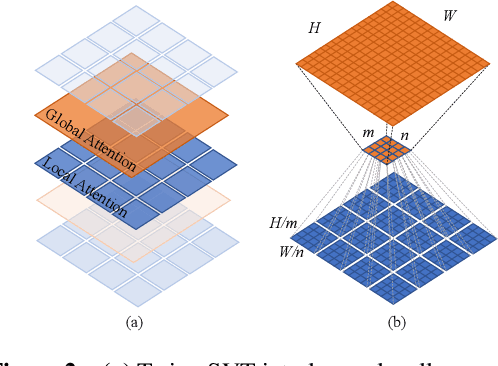
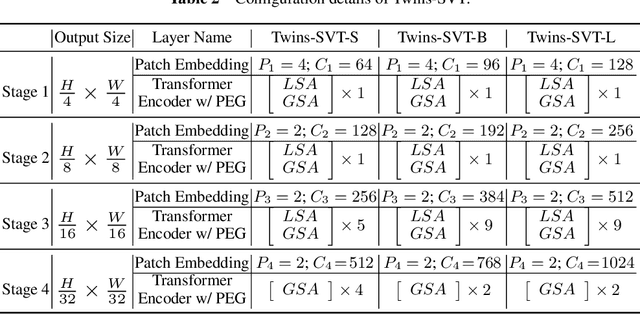
Very recently, a variety of vision transformer architectures for dense prediction tasks have been proposed and they show that the design of spatial attention is critical to their success in these tasks. In this work, we revisit the design of the spatial attention and demonstrate that a carefully-devised yet simple spatial attention mechanism performs favourably against the state-of-the-art schemes. As a result, we propose two vision transformer architectures, namely, Twins-PCPVT and Twins-SVT. Our proposed architectures are highly-efficient and easy to implement, only involving matrix multiplications that are highly optimized in modern deep learning frameworks. More importantly, the proposed architectures achieve excellent performance on a wide range of visual tasks including imagelevel classification as well as dense detection and segmentation. The simplicity and strong performance suggest that our proposed architectures may serve as stronger backbones for many vision tasks. Our code will be released soon at https://github.com/Meituan-AutoML/Twins .
SwiftNet: Real-time Video Object Segmentation
Feb 09, 2021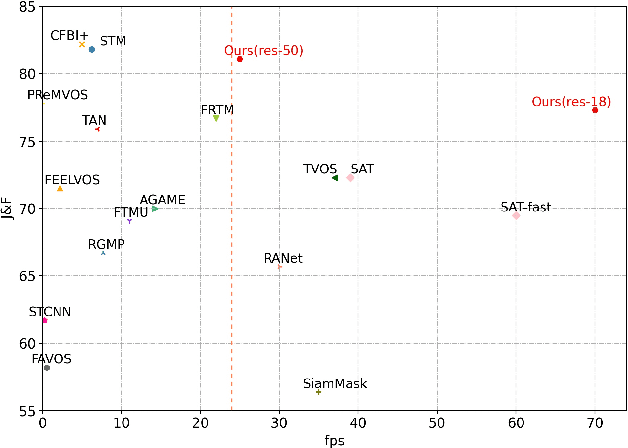


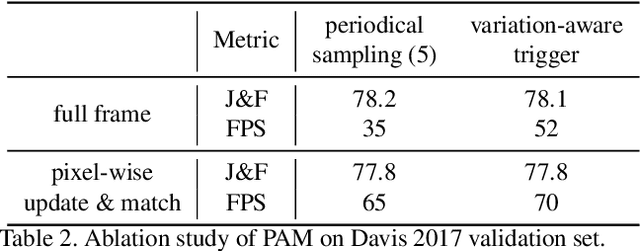
In this work we present SwiftNet for real-time semi-supervised video object segmentation (one-shot VOS), which reports 77.8% J&F and 70 FPS on DAVIS 2017 validation dataset, leading all present solutions in overall accuracy and speed performance. We achieve this by elaborately compressing spatiotemporal redundancy in matching-based VOS via Pixel-Adaptive Memory (PAM). Temporally, PAM adaptively triggers memory updates on frames where objects display noteworthy inter-frame variations. Spatially, PAM selectively performs memory update and match on dynamic pixels while ignoring the static ones, significantly reducing redundant computations wasted on segmentation-irrelevant pixels. To promote efficient reference encoding, light-aggregation encoder is also introduced in SwiftNet deploying reversed sub-pixel. We hope SwiftNet could set a strong and efficient baseline for real-time VOS and facilitate its application in mobile vision.