 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptDet: Expand Your Detector Vocabulary with Uncurated Images
Paper and Code


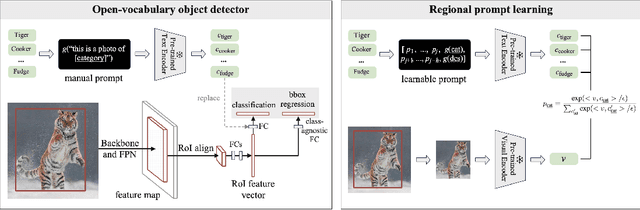

The goal of this work is to establish a scalable pipeline for expanding an object detector towards novel/unseen categories, using zero manual annotations. To achieve that, we make the following four contributions: (i) in pursuit of generalisation, we propose a two-stage open-vocabulary object detector that categorises each box proposal by a classifier generated from the text encoder of a pre-trained visual-language model; (ii) To pair the visual latent space (from RPN box proposal) with that of the pre-trained text encoder, we propose the idea of regional prompt learning to optimise a couple of learnable prompt vectors, converting the textual embedding space to fit those visually object-centric images; (iii) To scale up the learning procedure towards detecting a wider spectrum of objects, we exploit the available online resource, iteratively updating the prompts, and later self-training the proposed detector with pseudo labels generated on a large corpus of noisy, uncurated web images. The self-trained detector, termed as PromptDet, significantly improves the detection performance on categories for which manual annotations are unavailable or hard to obtain, e.g. rare categories. Finally, (iv) to validate the necessity of our proposed components, we conduct extensive experiments on the challenging LVIS and MS-COCO dataset, showing superior performance over existing approaches with fewer additional training images and zero manual annotations whatsoever. Project page with code: https://fcjian.github.io/promptdet.