 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeapAlign: Post-Training Flow Matching Models at Any Generation Step by Building Two-Step Trajectories
Apr 16, 2026This paper focuses on the alignment of flow matching models with human preferences. A promising way is fine-tuning by directly backpropagating reward gradients through the differentiable generation process of flow matching. However, backpropagating through long trajectories results in prohibitive memory costs and gradient explosion. Therefore, direct-gradient methods struggle to update early generation steps, which are crucial for determining the global structure of the final image. To address this issue, we introduce LeapAlign, a fine-tuning method that reduces computational cost and enables direct gradient propagation from reward to early generation steps. Specifically, we shorten the long trajectory into only two steps by designing two consecutive leaps, each skipping multiple ODE sampling steps and predicting future latents in a single step. By randomizing the start and end timesteps of the leaps, LeapAlign leads to efficient and stable model updates at any generation step. To better use such shortened trajectories, we assign higher training weights to those that are more consistent with the long generation path. To further enhance gradient stability, we reduce the weights of gradient terms with large magnitude, instead of completely removing them as done in previous works. When fine-tuning the Flux model, LeapAlign consistently outperforms state-of-the-art GRPO-based and direct-gradient methods across various metrics, achieving superior image quality and image-text alignment.
Seedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
X-SAM: From Segment Anything to Any Segmentation
Aug 06, 2025Large Language Models (LLMs) demonstrate strong capabilities in broad knowledge representation, yet they are inherently deficient in pixel-level perceptual understanding. Although the Segment Anything Model (SAM) represents a significant advancement in visual-prompt-driven image segmentation, it exhibits notable limitations in multi-mask prediction and category-specific segmentation tasks, and it cannot integrate all segmentation tasks within a unified model architecture. To address these limitations, we present X-SAM, a streamlined Multimodal Large Language Model (MLLM) framework that extends the segmentation paradigm from \textit{segment anything} to \textit{any segmentation}. Specifically, we introduce a novel unified framework that enables more advanced pixel-level perceptual comprehension for MLLMs. Furthermore, we propose a new segmentation task, termed Visual GrounDed (VGD) segmentation, which segments all instance objects with interactive visual prompts and empowers MLLMs with visual grounded, pixel-wise interpretative capabilities. To enable effective training on diverse data sources, we present a unified training strategy that supports co-training across multiple datasets. Experimental results demonstrate that X-SAM achieves state-of-the-art performance on a wide range of image segmentation benchmarks, highlighting its efficiency for multimodal, pixel-level visual understanding. Code is available at https://github.com/wanghao9610/X-SAM.
RoboTron-Sim: Improving Real-World Driving via Simulated Hard-Case
Aug 06, 2025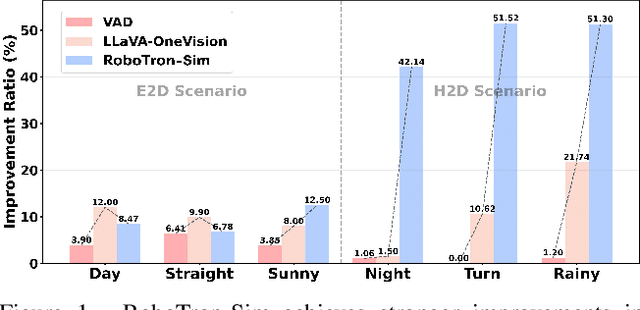



Collecting real-world data for rare high-risk scenarios, long-tailed driving events, and complex interactions remains challenging, leading to poor performance of existing autonomous driving systems in these critical situations. In this paper, we propose RoboTron-Sim that improves real-world driving in critical situations by utilizing simulated hard cases. First, we develop a simulated dataset called Hard-case Augmented Synthetic Scenarios (HASS), which covers 13 high-risk edge-case categories, as well as balanced environmental conditions such as day/night and sunny/rainy. Second, we introduce Scenario-aware Prompt Engineering (SPE) and an Image-to-Ego Encoder (I2E Encoder) to enable multimodal large language models to effectively learn real-world challenging driving skills from HASS, via adapting to environmental deviations and hardware differences between real-world and simulated scenarios. Extensive experiments on nuScenes show that RoboTron-Sim improves driving performance in challenging scenarios by around 50%, achieving state-of-the-art results in real-world open-loop planning. Qualitative results further demonstrate the effectiveness of RoboTron-Sim in better managing rare high-risk driving scenarios. Project page: https://stars79689.github.io/RoboTron-Sim/
DisTime: Distribution-based Time Representation for Video Large Language Models
May 30, 2025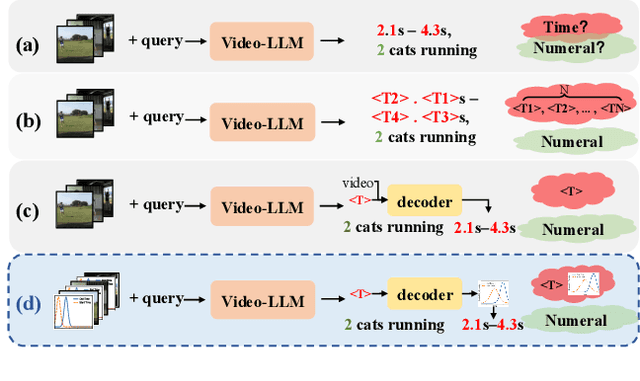
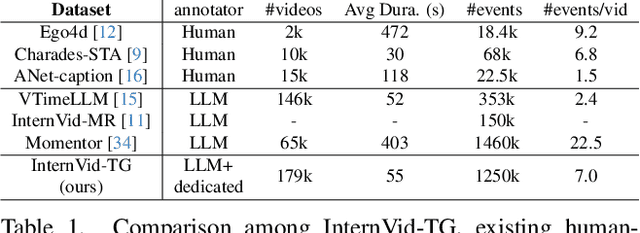
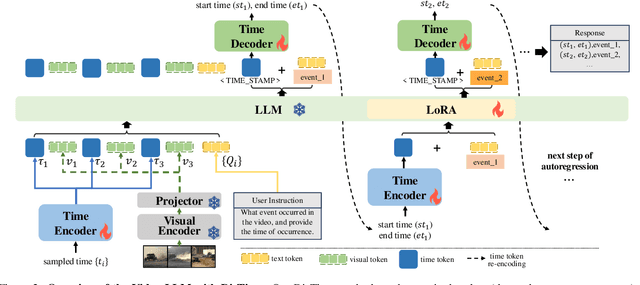
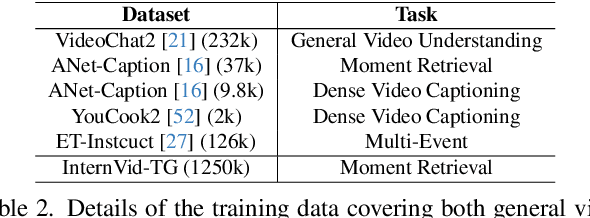
Despite advances in general video understanding, Video Large Language Models (Video-LLMs) face challenges in precise temporal localization due to discrete time representations and limited temporally aware datasets. Existing methods for temporal expression either conflate time with text-based numerical values, add a series of dedicated temporal tokens, or regress time using specialized temporal grounding heads. To address these issues, we introduce DisTime, a lightweight framework designed to enhance temporal comprehension in Video-LLMs. DisTime employs a learnable token to create a continuous temporal embedding space and incorporates a Distribution-based Time Decoder that generates temporal probability distributions, effectively mitigating boundary ambiguities and maintaining temporal continuity. Additionally, the Distribution-based Time Encoder re-encodes timestamps to provide time markers for Video-LLMs. To overcome temporal granularity limitations in existing datasets, we propose an automated annotation paradigm that combines the captioning capabilities of Video-LLMs with the localization expertise of dedicated temporal models. This leads to the creation of InternVid-TG, a substantial dataset with 1.25M temporally grounded events across 179k videos, surpassing ActivityNet-Caption by 55 times. Extensive experiments demonstrate that DisTime achieves state-of-the-art performance across benchmarks in three time-sensitive tasks while maintaining competitive performance in Video QA tasks. Code and data are released at https://github.com/josephzpng/DisTime.
AP-CAP: Advancing High-Quality Data Synthesis for Animal Pose Estimation via a Controllable Image Generation Pipeline
Apr 01, 2025The task of 2D animal pose estimation plays a crucial role in advancing deep learning applications in animal behavior analysis and ecological research. Despite notable progress in some existing approaches, our study reveals that the scarcity of high-quality datasets remains a significant bottleneck, limiting the full potential of current methods. To address this challenge, we propose a novel Controllable Image Generation Pipeline for synthesizing animal pose estimation data, termed AP-CAP. Within this pipeline, we introduce a Multi-Modal Animal Image Generation Model capable of producing images with expected poses. To enhance the quality and diversity of the generated data, we further propose three innovative strategies: (1) Modality-Fusion-Based Animal Image Synthesis Strategy to integrate multi-source appearance representations, (2) Pose-Adjustment-Based Animal Image Synthesis Strategy to dynamically capture diverse pose variations, and (3) Caption-Enhancement-Based Animal Image Synthesis Strategy to enrich visual semantic understanding. Leveraging the proposed model and strategies, we create the MPCH Dataset (Modality-Pose-Caption Hybrid), the first hybrid dataset that innovatively combines synthetic and real data, establishing the largest-scale multi-source heterogeneous benchmark repository for animal pose estimation to date. Extensive experiments demonstrate the superiority of our method in improving both the performance and generalization capability of animal pose estimators.
DataPlatter: Boosting Robotic Manipulation Generalization with Minimal Costly Data
Mar 25, 2025The growing adoption of Vision-Language-Action (VLA) models in embodied AI intensifies the demand for diverse manipulation demonstrations. However, high costs associated with data collection often result in insufficient data coverage across all scenarios, which limits the performance of the models. It is observed that the spatial reasoning phase (SRP) in large workspace dominates the failure cases. Fortunately, this data can be collected with low cost, underscoring the potential of leveraging inexpensive data to improve model performance. In this paper, we introduce the DataPlatter method, a framework that decouples training trajectories into distinct task stages and leverages abundant easily collectible SRP data to enhance VLA model's generalization. Through analysis we demonstrate that sub-task-specific training with additional SRP data with proper proportion can act as a performance catalyst for robot manipulation, maximizing the utilization of costly physical interaction phase (PIP) data. Experiments show that through introducing large proportion of cost-effective SRP trajectories into a limited set of PIP data, we can achieve a maximum improvement of 41\% on success rate in zero-shot scenes, while with the ability to transfer manipulation skill to novel targets.
DriveMM: All-in-One Large Multimodal Model for Autonomous Driving
Dec 10, 2024



Large Multimodal Models (LMMs) have demonstrated exceptional comprehension and interpretation capabilities in Autonomous Driving (AD) by incorporating large language models. Despite the advancements, current data-driven AD approaches tend to concentrate on a single dataset and specific tasks, neglecting their overall capabilities and ability to generalize. To bridge these gaps, we propose DriveMM, a general large multimodal model designed to process diverse data inputs, such as images and multi-view videos, while performing a broad spectrum of AD tasks, including perception, prediction, and planning. Initially, the model undergoes curriculum pre-training to process varied visual signals and perform basic visual comprehension and perception tasks. Subsequently, we augment and standardize various AD-related datasets to fine-tune the model, resulting in an all-in-one LMM for autonomous driving. To assess the general capabilities and generalization ability, we conduct evaluations on six public benchmarks and undertake zero-shot transfer on an unseen dataset, where DriveMM achieves state-of-the-art performance across all tasks. We hope DriveMM as a promising solution for future end-toend autonomous driving applications in the real world.
RoboMM: All-in-One Multimodal Large Model for Robotic Manipulation
Dec 10, 2024



In recent years, robotics has advanced significantly through the integration of larger models and large-scale datasets. However, challenges remain in applying these models to 3D spatial interactions and managing data collection costs. To address these issues, we propose the multimodal robotic manipulation model, RoboMM, along with the comprehensive dataset, RoboData. RoboMM enhances 3D perception through camera parameters and occupancy supervision. Building on OpenFlamingo, it incorporates Modality-Isolation-Mask and multimodal decoder blocks, improving modality fusion and fine-grained perception. RoboData offers the complete evaluation system by integrating several well-known datasets, achieving the first fusion of multi-view images, camera parameters, depth maps, and actions, and the space alignment facilitates comprehensive learning from diverse robotic datasets. Equipped with RoboData and the unified physical space, RoboMM is the generalist policy that enables simultaneous evaluation across all tasks within multiple datasets, rather than focusing on limited selection of data or tasks. Its design significantly enhances robotic manipulation performance, increasing the average sequence length on the CALVIN from 1.7 to 3.3 and ensuring cross-embodiment capabilities, achieving state-of-the-art results across multiple datasets.