 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoGM: Learning to Merge LLMs via Evolutionary Generative Optimization
May 28, 2026Evolutionary model merging provides a powerful framework for the automated, training-free composition of LLMs through parameter-space search. However, existing methods predominantly rely on stochastic, hand-crafted operators that overlook the underlying performance landscape of the coefficient space. We propose Evolutionary Generative Merging (EvoGM), a framework that transcends manual heuristics by employing learnable generative modeling to optimize merging coefficients. Specifically, EvoGM features a dual-generator architecture with cycle-consistent learning to adaptively sample and refine promising merging candidates. By constructing winner-loser pairs from historical search trajectories, our framework effectively captures high-performance parameter distributions and maximizes data efficiency. This generative process is seamlessly integrated into a multi-round evolutionary pipeline, where elite merged models iteratively serve as new expert foundations. Extensive experiments across diverse benchmarks demonstrate that EvoGM significantly outperforms state-of-the-art baselines, exhibiting robust performance on both seen and unseen tasks. Code and data are available at https://github.com/JiangTao97/evogm.
JFAA: Technical Report for the EPIC-KITCHENS-100 Action Anticipation Challenge at EgoVis 2026
May 20, 2026We propose JFAA, a JEPA-based Future Action Anticipation method for the EPIC-KITCHENS-100 (EK-100) Action Anticipation task. Inspired by the representation learning and future prediction ability of V-JEPA 2.1, JFAA uses a frozen encoder and predictor to extract observed context features and near-future latent tokens. A lightweight attentive probe is then trained to predict verb, noun, and action logits with separate task queries. To improve robustness, we further build a field-aware ensemble over selected epoch-level predictions, allowing each output field to benefit from its most reliable candidates. Experimental results on the official challenge server show that JFAA achieves first place in the EgoVis 2026 EK-100 Action Anticipation Challenge. Our code will be released at https://github.com/CorrineQiu/JFAA.
VISTA: Technical Report for the Ego4D Short-Term Object Interaction Anticipation at EgoVis 2026
May 20, 2026We propose VISTA, a V-JEPA Integrated StillFast Temporal Anticipator for the Ego4D Short-Term Object Interaction Anticipation (STA) Challenge at EgoVis 2026. Given an egocentric video timestamp, the task requires anticipating the next human-object interaction, including the future active object's bounding box, noun category, verb category, time-to-contact, and confidence score. VISTA follows a StillFast-style design that combines object-centric spatial detection with short-horizon temporal context. Specifically, a COCO-pretrained Faster R-CNN ResNet-50 FPN detector generates object proposals from the last observed high-resolution frame, while a frozen V-JEPA 2.1 temporal branch extracts clip-level egocentric context from the observed video. The temporal representation is injected into the detection pathway through feature modulation and ROI-level context fusion. The fused proposal features are then passed to multi-head STA predictors for box refinement, noun classification, verb classification, time-to-contact regression, and interaction confidence estimation. For the final submission, we further ensemble complementary predictions to improve robustness. Experimental results on the official challenge server show that VISTA achieves first place in the EgoVis 2026 Ego4D STA Challenge. Our code will be released at https://github.com/CorrineQiu/VISTA.
Efficient Adversarial Training via Criticality-Aware Fine-Tuning
Apr 14, 2026Vision Transformer (ViT) models have achieved remarkable performance across various vision tasks, with scalability being a key advantage when applied to large datasets. This scalability enables ViT models to exhibit strong generalization capabilities. However, as the number of parameters increases, the robustness of ViT models to adversarial examples does not scale proportionally. Adversarial training (AT), one of the most effective methods for enhancing robustness, typically requires fine-tuning the entire model, leading to prohibitively high computational costs, especially for large ViT architectures. In this paper, we aim to robustly fine-tune only a small subset of parameters to achieve robustness comparable to standard AT. To accomplish this, we introduce Criticality-Aware Adversarial Training (CAAT), a novel method that adaptively allocates resources to the most robustness-critical parameters, fine-tuning only selected modules. Specifically, CAAT efficiently identifies parameters that contribute most to adversarial robustness. It then leverages parameter-efficient fine-tuning (PEFT) to robustly adjust weight matrices where the number of critical parameters exceeds a predefined threshold. CAAT exhibits favorable generalization when scaled to larger vision transformer architectures, potentially paving the way for adversarial training at scale, e.g, compared with plain adversarial training, CAAT incurs only a 4.3% decrease in adversarial robustness while tuning approximately 6% of its parameters. Extensive experiments on three widely used adversarial learning datasets demonstrate that CAAT outperforms state-of-the-art lightweight AT methods with fewer trainable parameters.
AlignMamba-2: Enhancing Multimodal Fusion and Sentiment Analysis with Modality-Aware Mamba
Mar 19, 2026In the era of large-scale pre-trained models, effectively adapting general knowledge to specific affective computing tasks remains a challenge, particularly regarding computational efficiency and multimodal heterogeneity. While Transformer-based methods have excelled at modeling inter-modal dependencies, their quadratic computational complexity limits their use with long-sequence data. Mamba-based models have emerged as a computationally efficient alternative; however, their inherent sequential scanning mechanism struggles to capture the global, non-sequential relationships that are crucial for effective cross-modal alignment. To address these limitations, we propose \textbf{AlignMamba-2}, an effective and efficient framework for multimodal fusion and sentiment analysis. Our approach introduces a dual alignment strategy that regularizes the model using both Optimal Transport distance and Maximum Mean Discrepancy, promoting geometric and statistical consistency between modalities without incurring any inference-time overhead. More importantly, we design a Modality-Aware Mamba layer, which employs a Mixture-of-Experts architecture with modality-specific and modality-shared experts to explicitly handle data heterogeneity during the fusion process. Extensive experiments on four challenging benchmarks, including dynamic time-series (on the CMU-MOSI and CMU-MOSEI datasets) and static image-related tasks (on the NYU-Depth V2 and MVSA-Single datasets), demonstrate that AlignMamba-2 establishes a new state-of-the-art in both effectiveness and efficiency across diverse pattern recognition tasks, ranging from dynamic time-series analysis to static image-text classification.
Global Prior Meets Local Consistency: Dual-Memory Augmented Vision-Language-Action Model for Efficient Robotic Manipulation
Feb 22, 2026Hierarchical Vision-Language-Action (VLA) models have rapidly become a dominant paradigm for robotic manipulation. It typically comprising a Vision-Language backbone for perception and understanding, together with a generative policy for action generation. However, its performance is increasingly bottlenecked by the action generation proceess. (i) Low inference efficiency. A pronounced distributional gap between isotropic noise priors and target action distributions, which increases denoising steps and the incidence of infeasible samples. (ii) Poor robustness. Existing policies condition solely on the current observation, neglecting the constraint of history sequence and thus lacking awareness of task progress and temporal consistency. To address these issues, we introduce OptimusVLA, a dual-memory VLA framework with Global Prior Memory (GPM) and Local Consistency Memory (LCM). GPM replaces Gaussian noise with task-level priors retrieved from semantically similar trajectories, thereby shortening the generative path and reducing the umber of function evaluations (NFE). LCM dynamically models executed action sequence to infer task progress and injects a learned consistency constraint that enforces temporal coherence and smoothness of trajectory. Across three simulation benchmarks, OptimusVLA consistently outperforms strong baselines: it achieves 98.6% average success rate on LIBERO, improves over pi_0 by 13.5% on CALVIN, and attains 38% average success rate on RoboTwin 2.0 Hard. In Real-World evaluation, OptimusVLA ranks best on Generalization and Long-horizon suites, surpassing pi_0 by 42.9% and 52.4%, respectively, while delivering 2.9x inference speedup.
Mirage-1: Augmenting and Updating GUI Agent with Hierarchical Multimodal Skills
Jun 12, 2025



Recent efforts to leverage the Multi-modal Large Language Model (MLLM) as GUI agents have yielded promising outcomes. However, these agents still struggle with long-horizon tasks in online environments, primarily due to insufficient knowledge and the inherent gap between offline and online domains. In this paper, inspired by how humans generalize knowledge in open-ended environments, we propose a Hierarchical Multimodal Skills (HMS) module to tackle the issue of insufficient knowledge. It progressively abstracts trajectories into execution skills, core skills, and ultimately meta-skills, providing a hierarchical knowledge structure for long-horizon task planning. To bridge the domain gap, we propose the Skill-Augmented Monte Carlo Tree Search (SA-MCTS) algorithm, which efficiently leverages skills acquired in offline environments to reduce the action search space during online tree exploration. Building on HMS, we propose Mirage-1, a multimodal, cross-platform, plug-and-play GUI agent. To validate the performance of Mirage-1 in real-world long-horizon scenarios, we constructed a new benchmark, AndroidLH. Experimental results show that Mirage-1 outperforms previous agents by 32\%, 19\%, 15\%, and 79\% on AndroidWorld, MobileMiniWob++, Mind2Web-Live, and AndroidLH, respectively. Project page: https://cybertronagent.github.io/Mirage-1.github.io/
Optimus-3: Towards Generalist Multimodal Minecraft Agents with Scalable Task Experts
Jun 12, 2025



Recently, agents based on multimodal large language models (MLLMs) have achieved remarkable progress across various domains. However, building a generalist agent with capabilities such as perception, planning, action, grounding, and reflection in open-world environments like Minecraft remains challenges: insufficient domain-specific data, interference among heterogeneous tasks, and visual diversity in open-world settings. In this paper, we address these challenges through three key contributions. 1) We propose a knowledge-enhanced data generation pipeline to provide scalable and high-quality training data for agent development. 2) To mitigate interference among heterogeneous tasks, we introduce a Mixture-of-Experts (MoE) architecture with task-level routing. 3) We develop a Multimodal Reasoning-Augmented Reinforcement Learning approach to enhance the agent's reasoning ability for visual diversity in Minecraft. Built upon these innovations, we present Optimus-3, a general-purpose agent for Minecraft. Extensive experimental results demonstrate that Optimus-3 surpasses both generalist multimodal large language models and existing state-of-the-art agents across a wide range of tasks in the Minecraft environment. Project page: https://cybertronagent.github.io/Optimus-3.github.io/
Cross-DINO: Cross the Deep MLP and Transformer for Small Object Detection
May 28, 2025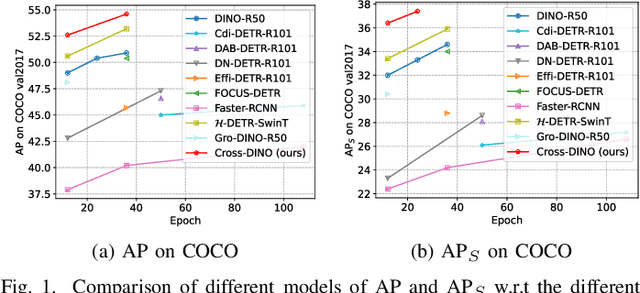



Small Object Detection (SOD) poses significant challenges due to limited information and the model's low class prediction score. While Transformer-based detectors have shown promising performance, their potential for SOD remains largely unexplored. In typical DETR-like frameworks, the CNN backbone network, specialized in aggregating local information, struggles to capture the necessary contextual information for SOD. The multiple attention layers in the Transformer Encoder face difficulties in effectively attending to small objects and can also lead to blurring of features. Furthermore, the model's lower class prediction score of small objects compared to large objects further increases the difficulty of SOD. To address these challenges, we introduce a novel approach called Cross-DINO. This approach incorporates the deep MLP network to aggregate initial feature representations with both short and long range information for SOD. Then, a new Cross Coding Twice Module (CCTM) is applied to integrate these initial representations to the Transformer Encoder feature, enhancing the details of small objects. Additionally, we introduce a new kind of soft label named Category-Size (CS), integrating the Category and Size of objects. By treating CS as new ground truth, we propose a new loss function called Boost Loss to improve the class prediction score of the model. Extensive experimental results on COCO, WiderPerson, VisDrone, AI-TOD, and SODA-D datasets demonstrate that Cross-DINO efficiently improves the performance of DETR-like models on SOD. Specifically, our model achieves 36.4% APs on COCO for SOD with only 45M parameters, outperforming the DINO by +4.4% APS (36.4% vs. 32.0%) with fewer parameters and FLOPs, under 12 epochs training setting. The source codes will be available at https://github.com/Med-Process/Cross-DINO.
Open-Det: An Efficient Learning Framework for Open-Ended Detection
May 27, 2025Open-Ended object Detection (OED) is a novel and challenging task that detects objects and generates their category names in a free-form manner, without requiring additional vocabularies during inference. However, the existing OED models, such as GenerateU, require large-scale datasets for training, suffer from slow convergence, and exhibit limited performance. To address these issues, we present a novel and efficient Open-Det framework, consisting of four collaborative parts. Specifically, Open-Det accelerates model training in both the bounding box and object name generation process by reconstructing the Object Detector and the Object Name Generator. To bridge the semantic gap between Vision and Language modalities, we propose a Vision-Language Aligner with V-to-L and L-to-V alignment mechanisms, incorporating with the Prompts Distiller to transfer knowledge from the VLM into VL-prompts, enabling accurate object name generation for the LLM. In addition, we design a Masked Alignment Loss to eliminate contradictory supervision and introduce a Joint Loss to enhance classification, resulting in more efficient training. Compared to GenerateU, Open-Det, using only 1.5% of the training data (0.077M vs. 5.077M), 20.8% of the training epochs (31 vs. 149), and fewer GPU resources (4 V100 vs. 16 A100), achieves even higher performance (+1.0% in APr). The source codes are available at: https://github.com/Med-Process/Open-Det.