 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Abstraction to Instantiation: Learning Behavioral Representation for Vision-Language-Action Model
May 21, 2026Vision-Language-Action (VLA) models often suffer from performance degradation under distribution shifts, as they struggle to learn generalized behavior representations across varying environments. While existing approaches attempt to construct behavior representations through action-centric latent variables, they are often limited by short-horizon temporal fragmentation and static execution-alignment, leading to inconsistent behaviors in complex scenarios. To address these limitations, we propose \textbf{BehaviorVLA}, a framework that facilitates robust manipulation through the learning of a temporally coherent behavioral representations. Our approach features two symmetric components: (1) the \textbf{Visuomotor Behavior Encoder (VBE)}, which utilizes a causal Mamba-based architecture to aggregate long-horizon trajectory information into a unified behavior representation; and (2) the \textbf{Phase-conditioned Behavior Decoder (PBD)}, which decodes this representation into precise actions by dynamically aligning task-level priors with real-time execution progress. Experiments on RoboTwin 2.0, LIBERO, and CALVIN demonstrate state-of-the-art success rates of 58\%, 98\%, and 4.36 (Avg.Len), respectively. Notably, in real-world sim-to-real transfer, BehaviorVLA matches the performance of OpenVLA-OFT using only 50\% of the demonstration data, showcasing its superior data efficiency and generalization.
Global Prior Meets Local Consistency: Dual-Memory Augmented Vision-Language-Action Model for Efficient Robotic Manipulation
Feb 22, 2026Hierarchical Vision-Language-Action (VLA) models have rapidly become a dominant paradigm for robotic manipulation. It typically comprising a Vision-Language backbone for perception and understanding, together with a generative policy for action generation. However, its performance is increasingly bottlenecked by the action generation proceess. (i) Low inference efficiency. A pronounced distributional gap between isotropic noise priors and target action distributions, which increases denoising steps and the incidence of infeasible samples. (ii) Poor robustness. Existing policies condition solely on the current observation, neglecting the constraint of history sequence and thus lacking awareness of task progress and temporal consistency. To address these issues, we introduce OptimusVLA, a dual-memory VLA framework with Global Prior Memory (GPM) and Local Consistency Memory (LCM). GPM replaces Gaussian noise with task-level priors retrieved from semantically similar trajectories, thereby shortening the generative path and reducing the umber of function evaluations (NFE). LCM dynamically models executed action sequence to infer task progress and injects a learned consistency constraint that enforces temporal coherence and smoothness of trajectory. Across three simulation benchmarks, OptimusVLA consistently outperforms strong baselines: it achieves 98.6% average success rate on LIBERO, improves over pi_0 by 13.5% on CALVIN, and attains 38% average success rate on RoboTwin 2.0 Hard. In Real-World evaluation, OptimusVLA ranks best on Generalization and Long-horizon suites, surpassing pi_0 by 42.9% and 52.4%, respectively, while delivering 2.9x inference speedup.
Mirage-1: Augmenting and Updating GUI Agent with Hierarchical Multimodal Skills
Jun 12, 2025



Recent efforts to leverage the Multi-modal Large Language Model (MLLM) as GUI agents have yielded promising outcomes. However, these agents still struggle with long-horizon tasks in online environments, primarily due to insufficient knowledge and the inherent gap between offline and online domains. In this paper, inspired by how humans generalize knowledge in open-ended environments, we propose a Hierarchical Multimodal Skills (HMS) module to tackle the issue of insufficient knowledge. It progressively abstracts trajectories into execution skills, core skills, and ultimately meta-skills, providing a hierarchical knowledge structure for long-horizon task planning. To bridge the domain gap, we propose the Skill-Augmented Monte Carlo Tree Search (SA-MCTS) algorithm, which efficiently leverages skills acquired in offline environments to reduce the action search space during online tree exploration. Building on HMS, we propose Mirage-1, a multimodal, cross-platform, plug-and-play GUI agent. To validate the performance of Mirage-1 in real-world long-horizon scenarios, we constructed a new benchmark, AndroidLH. Experimental results show that Mirage-1 outperforms previous agents by 32\%, 19\%, 15\%, and 79\% on AndroidWorld, MobileMiniWob++, Mind2Web-Live, and AndroidLH, respectively. Project page: https://cybertronagent.github.io/Mirage-1.github.io/
Optimus-3: Towards Generalist Multimodal Minecraft Agents with Scalable Task Experts
Jun 12, 2025



Recently, agents based on multimodal large language models (MLLMs) have achieved remarkable progress across various domains. However, building a generalist agent with capabilities such as perception, planning, action, grounding, and reflection in open-world environments like Minecraft remains challenges: insufficient domain-specific data, interference among heterogeneous tasks, and visual diversity in open-world settings. In this paper, we address these challenges through three key contributions. 1) We propose a knowledge-enhanced data generation pipeline to provide scalable and high-quality training data for agent development. 2) To mitigate interference among heterogeneous tasks, we introduce a Mixture-of-Experts (MoE) architecture with task-level routing. 3) We develop a Multimodal Reasoning-Augmented Reinforcement Learning approach to enhance the agent's reasoning ability for visual diversity in Minecraft. Built upon these innovations, we present Optimus-3, a general-purpose agent for Minecraft. Extensive experimental results demonstrate that Optimus-3 surpasses both generalist multimodal large language models and existing state-of-the-art agents across a wide range of tasks in the Minecraft environment. Project page: https://cybertronagent.github.io/Optimus-3.github.io/
Optimus-2: Multimodal Minecraft Agent with Goal-Observation-Action Conditioned Policy
Feb 27, 2025



Building an agent that can mimic human behavior patterns to accomplish various open-world tasks is a long-term goal. To enable agents to effectively learn behavioral patterns across diverse tasks, a key challenge lies in modeling the intricate relationships among observations, actions, and language. To this end, we propose Optimus-2, a novel Minecraft agent that incorporates a Multimodal Large Language Model (MLLM) for high-level planning, alongside a Goal-Observation-Action Conditioned Policy (GOAP) for low-level control. GOAP contains (1) an Action-guided Behavior Encoder that models causal relationships between observations and actions at each timestep, then dynamically interacts with the historical observation-action sequence, consolidating it into fixed-length behavior tokens, and (2) an MLLM that aligns behavior tokens with open-ended language instructions to predict actions auto-regressively. Moreover, we introduce a high-quality Minecraft Goal-Observation-Action (MGOA)} dataset, which contains 25,000 videos across 8 atomic tasks, providing about 30M goal-observation-action pairs. The automated construction method, along with the MGOA dataset, can contribute to the community's efforts to train Minecraft agents. Extensive experimental results demonstrate that Optimus-2 exhibits superior performance across atomic tasks, long-horizon tasks, and open-ended instruction tasks in Minecraft.
Optimus-1: Hybrid Multimodal Memory Empowered Agents Excel in Long-Horizon Tasks
Aug 07, 2024Building a general-purpose agent is a long-standing vision in the field of artificial intelligence. Existing agents have made remarkable progress in many domains, yet they still struggle to complete long-horizon tasks in an open world. We attribute this to the lack of necessary world knowledge and multimodal experience that can guide agents through a variety of long-horizon tasks. In this paper, we propose a Hybrid Multimodal Memory module to address the above challenges. It 1) transforms knowledge into Hierarchical Directed Knowledge Graph that allows agents to explicitly represent and learn world knowledge, and 2) summarises historical information into Abstracted Multimodal Experience Pool that provide agents with rich references for in-context learning. On top of the Hybrid Multimodal Memory module, a multimodal agent, Optimus-1, is constructed with dedicated Knowledge-guided Planner and Experience-Driven Reflector, contributing to a better planning and reflection in the face of long-horizon tasks in Minecraft. Extensive experimental results show that Optimus-1 significantly outperforms all existing agents on challenging long-horizon task benchmarks, and exhibits near human-level performance on many tasks. In addition, we introduce various Multimodal Large Language Models (MLLMs) as the backbone of Optimus-1. Experimental results show that Optimus-1 exhibits strong generalization with the help of the Hybrid Multimodal Memory module, outperforming the GPT-4V baseline on many tasks.
HCQA @ Ego4D EgoSchema Challenge 2024
Jun 22, 2024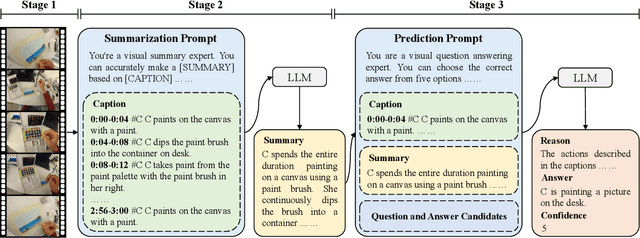



In this report, we present our champion solution for Ego4D EgoSchema Challenge in CVPR 2024. To deeply integrate the powerful egocentric captioning model and question reasoning model, we propose a novel Hierarchical Comprehension scheme for egocentric video Question Answering, named HCQA. It consists of three stages: Fine-grained Caption Generation, Context-driven Summarization, and Inference-guided Answering. Given a long-form video, HCQA captures local detailed visual information and global summarised visual information via Fine-grained Caption Generation and Context-driven Summarization, respectively. Then in Inference-guided Answering, HCQA utilizes this hierarchical information to reason and answer given question. On the EgoSchema blind test set, HCQA achieves 75% accuracy in answering over 5,000 human curated multiple-choice questions. Our code will be released at https://github.com/Hyu-Zhang/HCQA.
ObjectNLQ @ Ego4D Episodic Memory Challenge 2024
Jun 22, 2024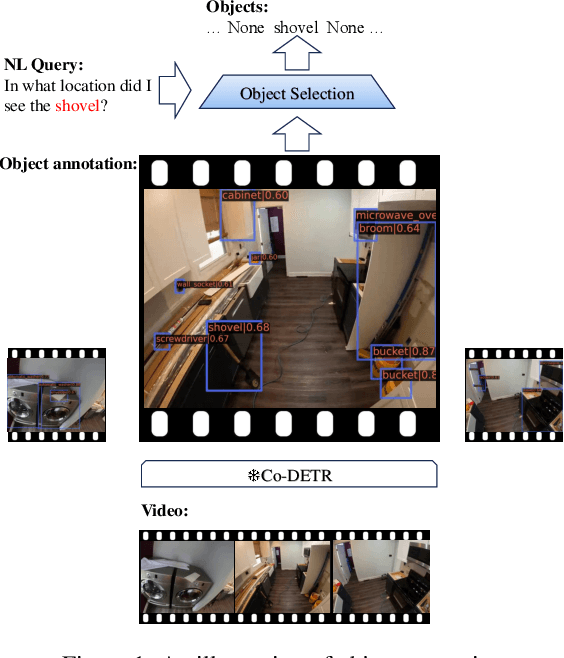
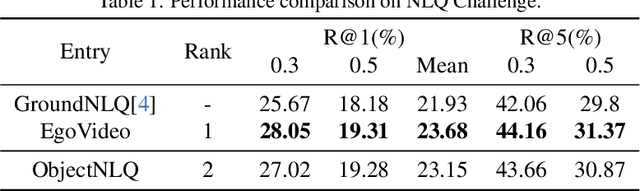
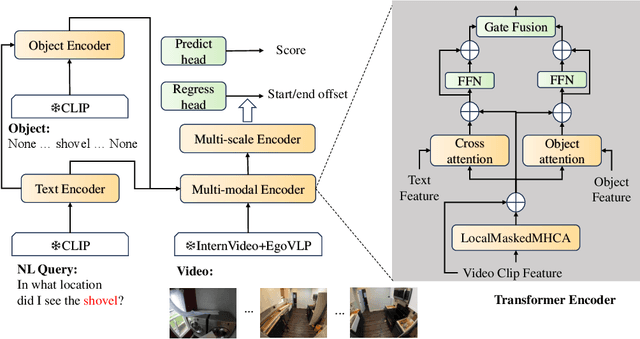

In this report, we present our approach for the Natural Language Query track and Goal Step track of the Ego4D Episodic Memory Benchmark at CVPR 2024. Both challenges require the localization of actions within long video sequences using textual queries. To enhance localization accuracy, our method not only processes the temporal information of videos but also identifies fine-grained objects spatially within the frames. To this end, we introduce a novel approach, termed ObjectNLQ, which incorporates an object branch to augment the video representation with detailed object information, thereby improving grounding efficiency. ObjectNLQ achieves a mean R@1 of 23.15, ranking 2nd in the Natural Language Queries Challenge, and gains 33.00 in terms of the metric R@1, IoU=0.3, ranking 3rd in the Goal Step Challenge. Our code will be released at https://github.com/Yisen-Feng/ObjectNLQ.
Enhancing the Emotional Generation Capability of Large Language Models via Emotional Chain-of-Thought
Jan 12, 2024The Emotional Generation is a subset of emotional intelligence, which aims to output an emotional response based on emotional conditions as input. Emotion generation has a wide range of applications, including emotion chat, emotional visual caption, and emotional rewriting. However, it faces challenges such as a lack of interpretability and poor evaluability. In this paper, we propose the Emotional Chain-of-Thought (ECoT), a plug-and-play prompting method that enhances the performance of Large Language Models (LLMs) on various emotional generation tasks by aligning with human emotional intelligence guidelines. To assess the reliability of ECoT, we propose an automated model-based evaluation method called EGS. Extensive experimental results demonstrate the effectiveness of ECoT and EGS. Further,we discuss the promise of LLMs in the field of sentiment analysis and present key insights into the LLMs with the ECoT in emotional generation tasks.
UniSA: Unified Generative Framework for Sentiment Analysis
Sep 04, 2023



Sentiment analysis is a crucial task that aims to understand people's emotional states and predict emotional categories based on multimodal information. It consists of several subtasks, such as emotion recognition in conversation (ERC), aspect-based sentiment analysis (ABSA), and multimodal sentiment analysis (MSA). However, unifying all subtasks in sentiment analysis presents numerous challenges, including modality alignment, unified input/output forms, and dataset bias. To address these challenges, we propose a Task-Specific Prompt method to jointly model subtasks and introduce a multimodal generative framework called UniSA. Additionally, we organize the benchmark datasets of main subtasks into a new Sentiment Analysis Evaluation benchmark, SAEval. We design novel pre-training tasks and training methods to enable the model to learn generic sentiment knowledge among subtasks to improve the model's multimodal sentiment perception ability. Our experimental results show that UniSA performs comparably to the state-of-the-art on all subtasks and generalizes well to various subtasks in sentiment analysis.