 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCQA @ Ego4D EgoSchema Challenge 2024
Paper and Code
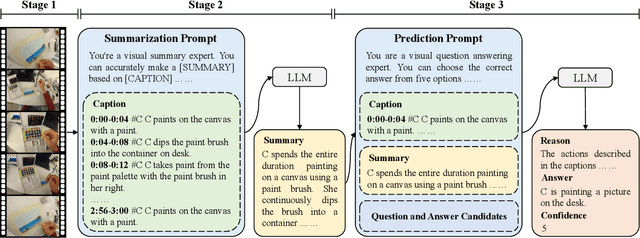



In this report, we present our champion solution for Ego4D EgoSchema Challenge in CVPR 2024. To deeply integrate the powerful egocentric captioning model and question reasoning model, we propose a novel Hierarchical Comprehension scheme for egocentric video Question Answering, named HCQA. It consists of three stages: Fine-grained Caption Generation, Context-driven Summarization, and Inference-guided Answering. Given a long-form video, HCQA captures local detailed visual information and global summarised visual information via Fine-grained Caption Generation and Context-driven Summarization, respectively. Then in Inference-guided Answering, HCQA utilizes this hierarchical information to reason and answer given question. On the EgoSchema blind test set, HCQA achieves 75% accuracy in answering over 5,000 human curated multiple-choice questions. Our code will be released at https://github.com/Hyu-Zhang/HCQA.