 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCQA-1.5 @ Ego4D EgoSchema Challenge 2025
May 27, 2025In this report, we present the method that achieves third place for Ego4D EgoSchema Challenge in CVPR 2025. To improve the reliability of answer prediction in egocentric video question answering, we propose an effective extension to the previously proposed HCQA framework. Our approach introduces a multi-source aggregation strategy to generate diverse predictions, followed by a confidence-based filtering mechanism that selects high-confidence answers directly. For low-confidence cases, we incorporate a fine-grained reasoning module that performs additional visual and contextual analysis to refine the predictions. Evaluated on the EgoSchema blind test set, our method achieves 77% accuracy on over 5,000 human-curated multiple-choice questions, outperforming last year's winning solution and the majority of participating teams. Our code will be added at https://github.com/Hyu-Zhang/HCQA.
Object-Shot Enhanced Grounding Network for Egocentric Video
May 07, 2025Egocentric video grounding is a crucial task for embodied intelligence applications, distinct from exocentric video moment localization. Existing methods primarily focus on the distributional differences between egocentric and exocentric videos but often neglect key characteristics of egocentric videos and the fine-grained information emphasized by question-type queries. To address these limitations, we propose OSGNet, an Object-Shot enhanced Grounding Network for egocentric video. Specifically, we extract object information from videos to enrich video representation, particularly for objects highlighted in the textual query but not directly captured in the video features. Additionally, we analyze the frequent shot movements inherent to egocentric videos, leveraging these features to extract the wearer's attention information, which enhances the model's ability to perform modality alignment. Experiments conducted on three datasets demonstrate that OSGNet achieves state-of-the-art performance, validating the effectiveness of our approach. Our code can be found at https://github.com/Yisen-Feng/OSGNet.
ObjectNLQ @ Ego4D Episodic Memory Challenge 2024
Jun 22, 2024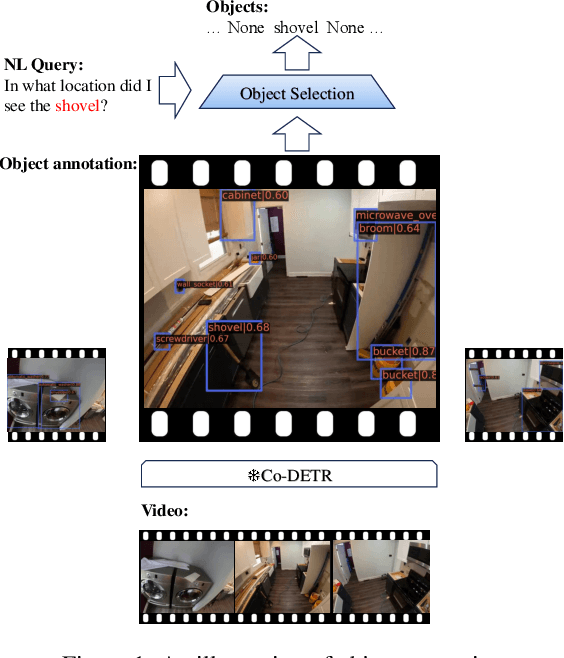
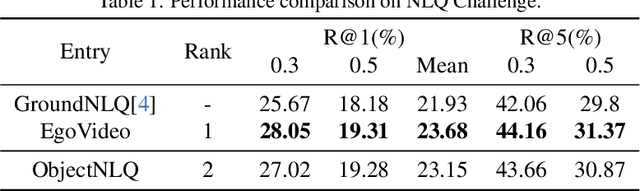
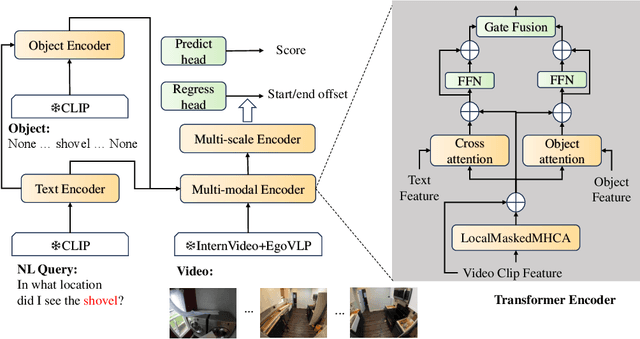

In this report, we present our approach for the Natural Language Query track and Goal Step track of the Ego4D Episodic Memory Benchmark at CVPR 2024. Both challenges require the localization of actions within long video sequences using textual queries. To enhance localization accuracy, our method not only processes the temporal information of videos but also identifies fine-grained objects spatially within the frames. To this end, we introduce a novel approach, termed ObjectNLQ, which incorporates an object branch to augment the video representation with detailed object information, thereby improving grounding efficiency. ObjectNLQ achieves a mean R@1 of 23.15, ranking 2nd in the Natural Language Queries Challenge, and gains 33.00 in terms of the metric R@1, IoU=0.3, ranking 3rd in the Goal Step Challenge. Our code will be released at https://github.com/Yisen-Feng/ObjectNLQ.
HCQA @ Ego4D EgoSchema Challenge 2024
Jun 22, 2024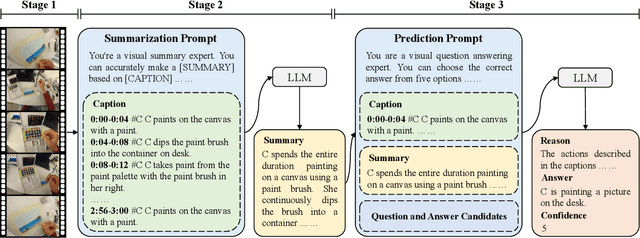



In this report, we present our champion solution for Ego4D EgoSchema Challenge in CVPR 2024. To deeply integrate the powerful egocentric captioning model and question reasoning model, we propose a novel Hierarchical Comprehension scheme for egocentric video Question Answering, named HCQA. It consists of three stages: Fine-grained Caption Generation, Context-driven Summarization, and Inference-guided Answering. Given a long-form video, HCQA captures local detailed visual information and global summarised visual information via Fine-grained Caption Generation and Context-driven Summarization, respectively. Then in Inference-guided Answering, HCQA utilizes this hierarchical information to reason and answer given question. On the EgoSchema blind test set, HCQA achieves 75% accuracy in answering over 5,000 human curated multiple-choice questions. Our code will be released at https://github.com/Hyu-Zhang/HCQA.