 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectNLQ @ Ego4D Episodic Memory Challenge 2024
Paper and Code
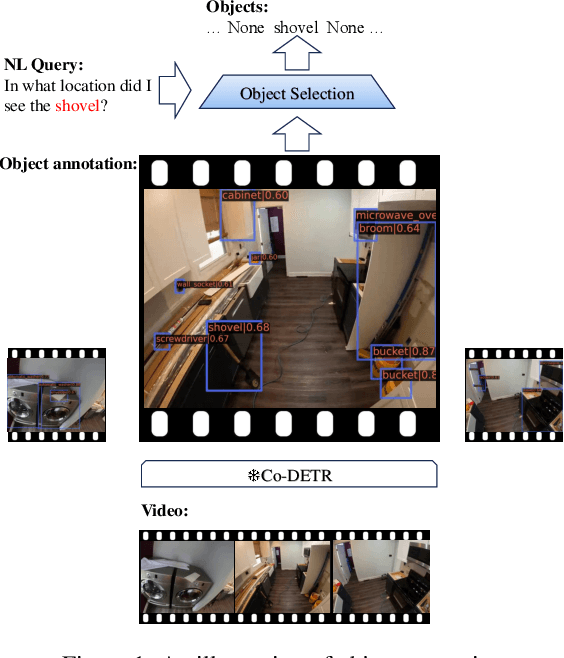
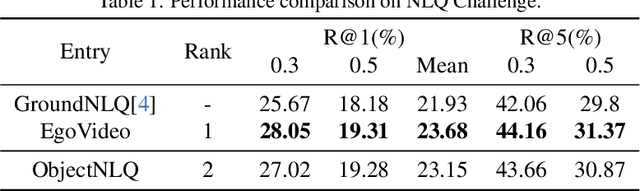
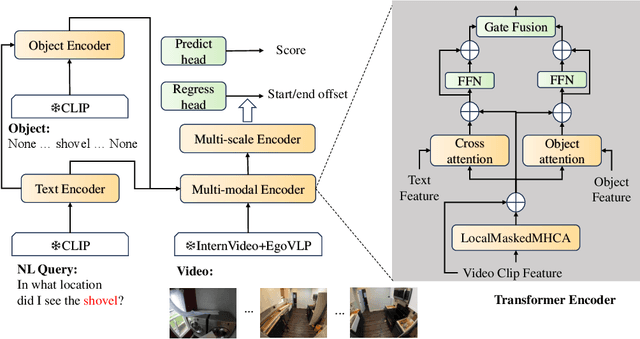

In this report, we present our approach for the Natural Language Query track and Goal Step track of the Ego4D Episodic Memory Benchmark at CVPR 2024. Both challenges require the localization of actions within long video sequences using textual queries. To enhance localization accuracy, our method not only processes the temporal information of videos but also identifies fine-grained objects spatially within the frames. To this end, we introduce a novel approach, termed ObjectNLQ, which incorporates an object branch to augment the video representation with detailed object information, thereby improving grounding efficiency. ObjectNLQ achieves a mean R@1 of 23.15, ranking 2nd in the Natural Language Queries Challenge, and gains 33.00 in terms of the metric R@1, IoU=0.3, ranking 3rd in the Goal Step Challenge. Our code will be released at https://github.com/Yisen-Feng/ObjectNLQ.