 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaultDiffusion: Few-Shot Fault Time Series Generation with Diffusion Model
Nov 19, 2025In industrial equipment monitoring, fault diagnosis is critical for ensuring system reliability and enabling predictive maintenance. However, the scarcity of fault data, due to the rarity of fault events and the high cost of data annotation, significantly hinders data-driven approaches. Existing time-series generation models, optimized for abundant normal data, struggle to capture fault distributions in few-shot scenarios, producing samples that lack authenticity and diversity due to the large domain gap and high intra-class variability of faults. To address this, we propose a novel few-shot fault time-series generation framework based on diffusion models. Our approach employs a positive-negative difference adapter, leveraging pre-trained normal data distributions to model the discrepancies between normal and fault domains for accurate fault synthesis. Additionally, a diversity loss is introduced to prevent mode collapse, encouraging the generation of diverse fault samples through inter-sample difference regularization. Experimental results demonstrate that our model significantly outperforms traditional methods in authenticity and diversity, achieving state-of-the-art performance on key benchmarks.
MTQA:Matrix of Thought for Enhanced Reasoning in Complex Question Answering
Sep 04, 2025Complex Question Answering (QA) is a fundamental and challenging task in NLP. While large language models (LLMs) exhibit impressive performance in QA, they suffer from significant performance degradation when facing complex and abstract QA tasks due to insufficient reasoning capabilities. Works such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) aim to enhance LLMs' reasoning abilities, but they face issues such as in-layer redundancy in tree structures and single paths in chain structures. Although some studies utilize Retrieval-Augmented Generation (RAG) methods to assist LLMs in reasoning, the challenge of effectively utilizing large amounts of information involving multiple entities and hops remains critical. To address this, we propose the Matrix of Thought (MoT), a novel and efficient LLM thought structure. MoT explores the problem in both horizontal and vertical dimensions through the "column-cell communication" mechanism, enabling LLMs to actively engage in multi-strategy and deep-level thinking, reducing redundancy within the column cells and enhancing reasoning capabilities. Furthermore, we develop a fact-correction mechanism by constructing knowledge units from retrieved knowledge graph triples and raw text to enhance the initial knowledge for LLM reasoning and correct erroneous answers. This leads to the development of an efficient and accurate QA framework (MTQA). Experimental results show that our framework outperforms state-of-the-art methods on four widely-used datasets in terms of F1 and EM scores, with reasoning time only 14.4\% of the baseline methods, demonstrating both its efficiency and accuracy. The code for this framework is available at https://github.com/lyfiter/mtqa.
Seasonal Prediction with Neural GCM and Simplified Boundary Forcings: Large-scale Atmospheric Variability and Tropical Cyclone Activity
Apr 30, 2025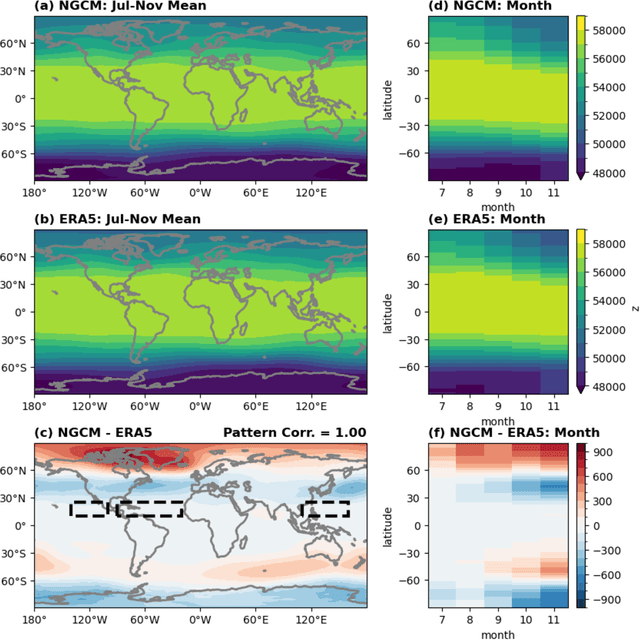
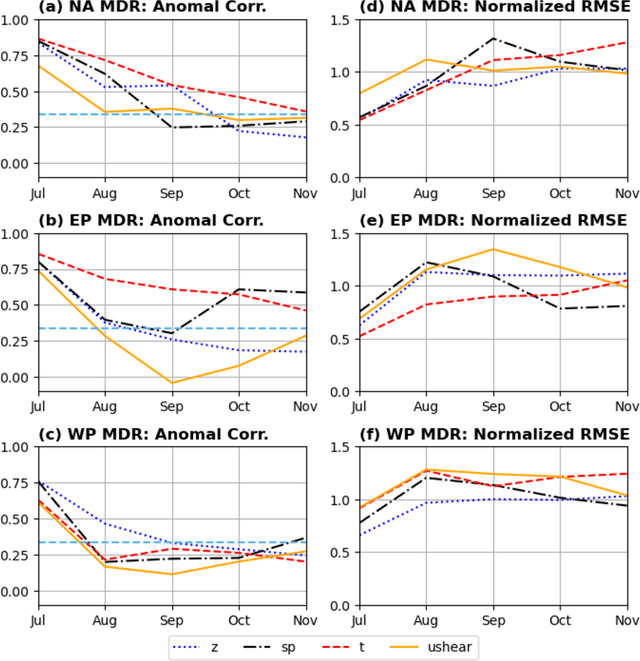
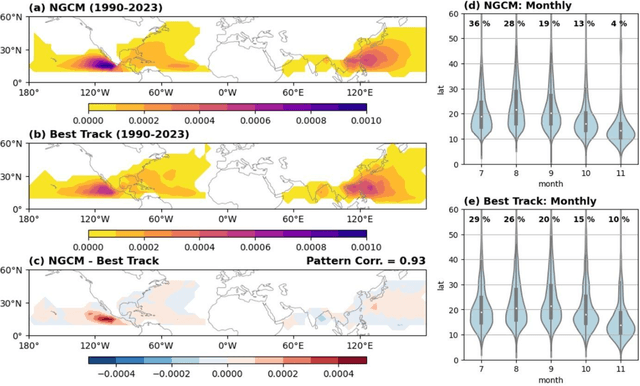
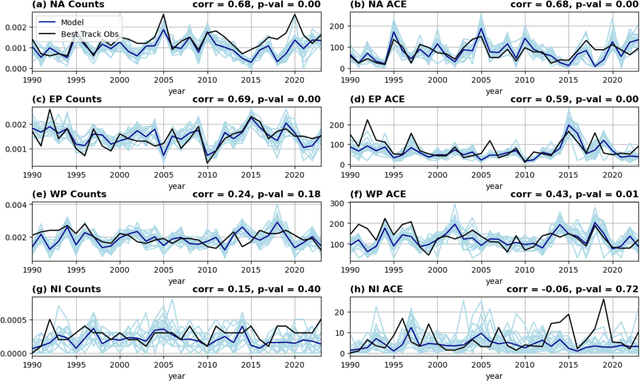
Machine learning (ML) models are successful with weather forecasting and have shown progress in climate simulations, yet leveraging them for useful climate predictions needs exploration. Here we show this feasibility using NeuralGCM, a hybrid ML-physics atmospheric model, for seasonal predictions of large-scale atmospheric variability and Northern Hemisphere tropical cyclone (TC) activity. Inspired by physical model studies, we simplify boundary conditions, assuming sea surface temperature (SST) and sea ice follow their climatological cycle but persist anomalies present at initialization. With such forcings, NeuralGCM simulates realistic atmospheric circulation and TC climatology patterns. Furthermore, this configuration yields useful seasonal predictions (July-November) for the tropical atmosphere and various TC activity metrics. Notably, the prediction skill for TC frequency in the North Atlantic and East Pacific basins is comparable to existing physical models. These findings highlight the promise of leveraging ML models with physical insights to model TC risks and deliver seamless weather-climate predictions.
DMFourLLIE: Dual-Stage and Multi-Branch Fourier Network for Low-Light Image Enhancement
Dec 01, 2024
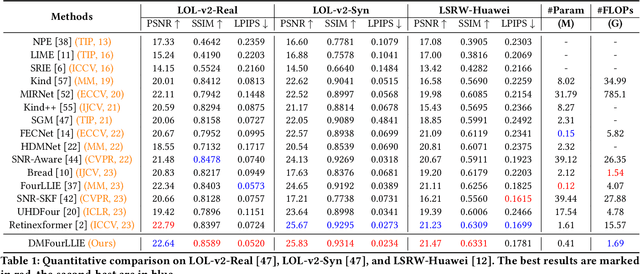
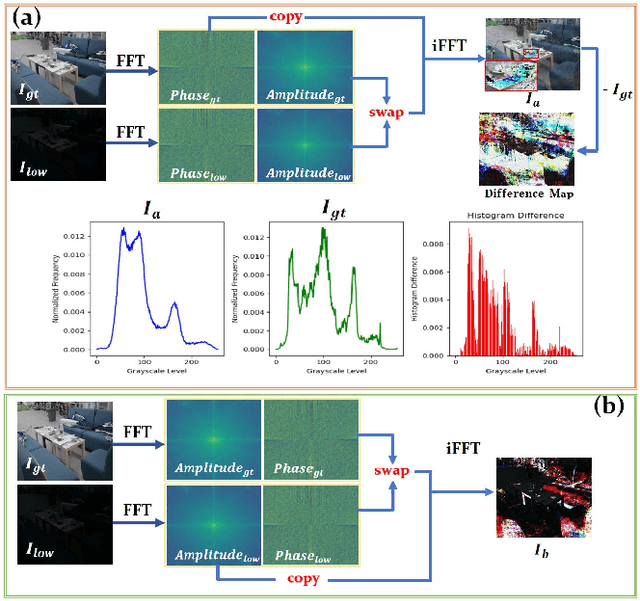
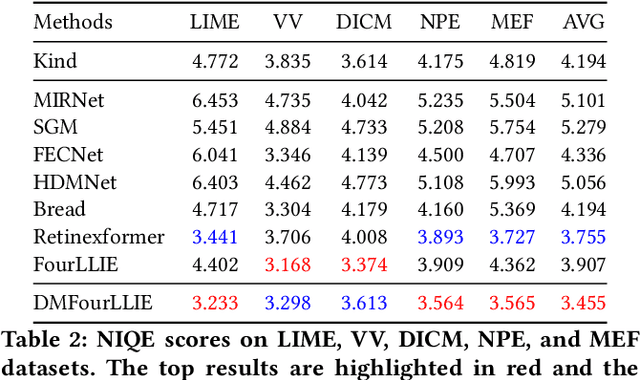
In the Fourier frequency domain, luminance information is primarily encoded in the amplitude component, while spatial structure information is significantly contained within the phase component. Existing low-light image enhancement techniques using Fourier transform have mainly focused on amplifying the amplitude component and simply replicating the phase component, an approach that often leads to color distortions and noise issues. In this paper, we propose a Dual-Stage Multi-Branch Fourier Low-Light Image Enhancement (DMFourLLIE) framework to address these limitations by emphasizing the phase component's role in preserving image structure and detail. The first stage integrates structural information from infrared images to enhance the phase component and employs a luminance-attention mechanism in the luminance-chrominance color space to precisely control amplitude enhancement. The second stage combines multi-scale and Fourier convolutional branches for robust image reconstruction, effectively recovering spatial structures and textures. This dual-branch joint optimization process ensures that complex image information is retained, overcoming the limitations of previous methods that neglected the interplay between amplitude and phase. Extensive experiments across multiple datasets demonstrate that DMFourLLIE outperforms current state-of-the-art methods in low-light image enhancement. Our code is available at https://github.com/bywlzts/DMFourLLIE.
Cross-Modal Pre-Aligned Method with Global and Local Information for Remote-Sensing Image and Text Retrieval
Nov 22, 2024



Remote sensing cross-modal text-image retrieval (RSCTIR) has gained attention for its utility in information mining. However, challenges remain in effectively integrating global and local information due to variations in remote sensing imagery and ensuring proper feature pre-alignment before modal fusion, which affects retrieval accuracy and efficiency. To address these issues, we propose CMPAGL, a cross-modal pre-aligned method leveraging global and local information. Our Gswin transformer block combines local window self-attention and global-local window cross-attention to capture multi-scale features. A pre-alignment mechanism simplifies modal fusion training, improving retrieval performance. Additionally, we introduce a similarity matrix reweighting (SMR) algorithm for reranking, and enhance the triplet loss function with an intra-class distance term to optimize feature learning. Experiments on four datasets, including RSICD and RSITMD, validate CMPAGL's effectiveness, achieving up to 4.65% improvement in R@1 and 2.28% in mean Recall (mR) over state-of-the-art methods.
Multitask Learning for SAR Ship Detection with Gaussian-Mask Joint Segmentation
Nov 21, 2024Detecting ships in synthetic aperture radar (SAR) images is challenging due to strong speckle noise, complex surroundings, and varying scales. This paper proposes MLDet, a multitask learning framework for SAR ship detection, consisting of object detection, speckle suppression, and target segmentation tasks. An angle classification loss with aspect ratio weighting is introduced to improve detection accuracy by addressing angular periodicity and object proportions. The speckle suppression task uses a dual-feature fusion attention mechanism to reduce noise and fuse shallow and denoising features, enhancing robustness. The target segmentation task, leveraging a rotated Gaussian-mask, aids the network in extracting target regions from cluttered backgrounds and improves detection efficiency with pixel-level predictions. The Gaussian-mask ensures ship centers have the highest probabilities, gradually decreasing outward under a Gaussian distribution. Additionally, a weighted rotated boxes fusion (WRBF) strategy combines multi-direction anchor predictions, filtering anchors beyond boundaries or with high overlap but low confidence. Extensive experiments on SSDD+ and HRSID datasets demonstrate the effectiveness and superiority of MLDet.
An Enhanced-State Reinforcement Learning Algorithm for Multi-Task Fusion in Large-Scale Recommender Systems
Sep 18, 2024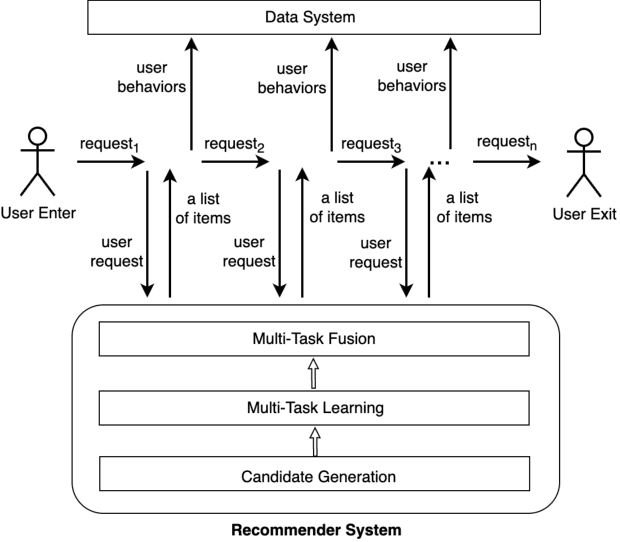
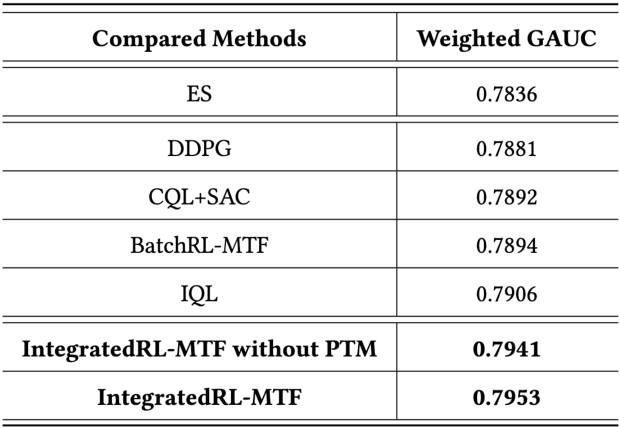
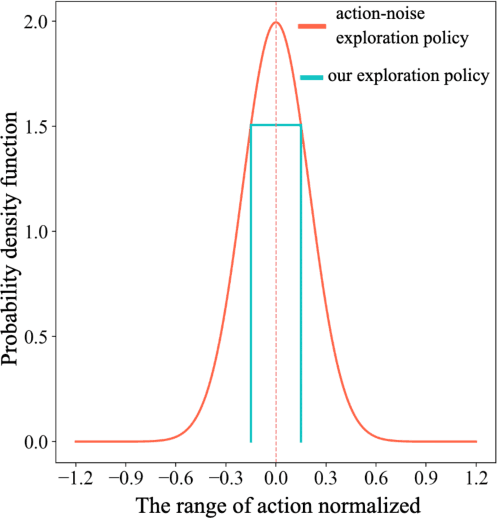
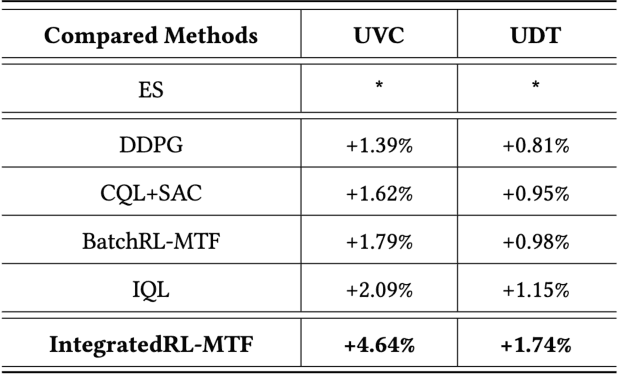
As the last key stage of Recommender Systems (RSs), Multi-Task Fusion (MTF) is in charge of combining multiple scores predicted by Multi-Task Learning (MTL) into a final score to maximize user satisfaction, which decides the ultimate recommendation results. In recent years, to maximize long-term user satisfaction within a recommendation session, Reinforcement Learning (RL) is widely used for MTF in large-scale RSs. However, limited by their modeling pattern, all the current RL-MTF methods can only utilize user features as the state to generate actions for each user, but unable to make use of item features and other valuable features, which leads to suboptimal results. Addressing this problem is a challenge that requires breaking through the current modeling pattern of RL-MTF. To solve this problem, we propose a novel method called Enhanced-State RL for MTF in RSs. Unlike the existing methods mentioned above, our method first defines user features, item features, and other valuable features collectively as the enhanced state; then proposes a novel actor and critic learning process to utilize the enhanced state to make much better action for each user-item pair. To the best of our knowledge, this novel modeling pattern is being proposed for the first time in the field of RL-MTF. We conduct extensive offline and online experiments in a large-scale RS. The results demonstrate that our model outperforms other models significantly. Enhanced-State RL has been fully deployed in our RS more than half a year, improving +3.84% user valid consumption and +0.58% user duration time compared to baseline.
KGV: Integrating Large Language Models with Knowledge Graphs for Cyber Threat Intelligence Credibility Assessment
Aug 15, 2024Cyber threat intelligence is a critical tool that many organizations and individuals use to protect themselves from sophisticated, organized, persistent, and weaponized cyber attacks. However, few studies have focused on the quality assessment of threat intelligence provided by intelligence platforms, and this work still requires manual analysis by cybersecurity experts. In this paper, we propose a knowledge graph-based verifier, a novel Cyber Threat Intelligence (CTI) quality assessment framework that combines knowledge graphs and Large Language Models (LLMs). Our approach introduces LLMs to automatically extract OSCTI key claims to be verified and utilizes a knowledge graph consisting of paragraphs for fact-checking. This method differs from the traditional way of constructing complex knowledge graphs with entities as nodes. By constructing knowledge graphs with paragraphs as nodes and semantic similarity as edges, it effectively enhances the semantic understanding ability of the model and simplifies labeling requirements. Additionally, to fill the gap in the research field, we created and made public the first dataset for threat intelligence assessment from heterogeneous sources. To the best of our knowledge, this work is the first to create a dataset on threat intelligence reliability verification, providing a reference for future research. Experimental results show that KGV (Knowledge Graph Verifier) significantly improves the performance of LLMs in intelligence quality assessment. Compared with traditional methods, we reduce a large amount of data annotation while the model still exhibits strong reasoning capabilities. Finally, our method can achieve XXX accuracy in network threat assessment.
Federated Hypergraph Learning with Hyperedge Completion
Aug 09, 2024
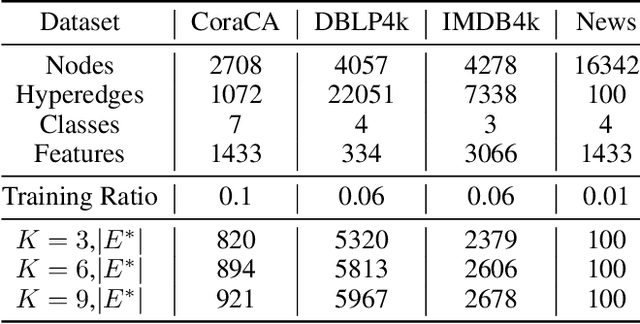
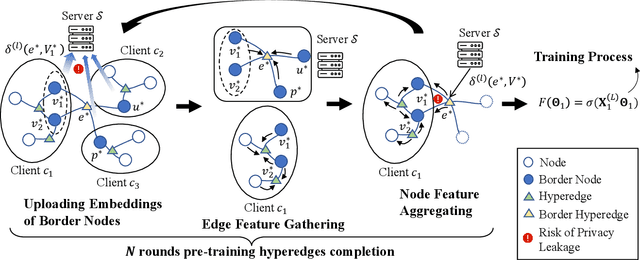
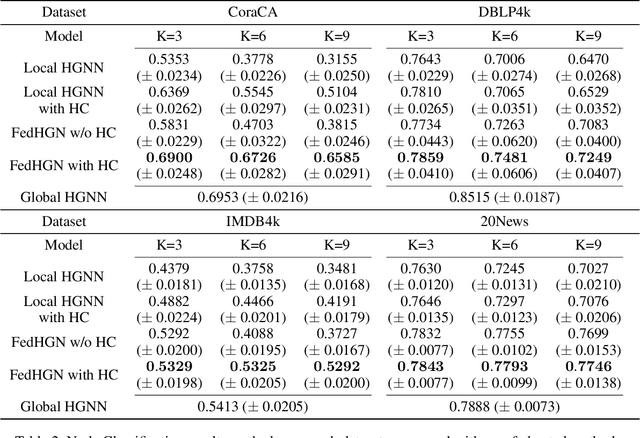
Hypergraph neural networks enhance conventional graph neural networks by capturing high-order relationships among nodes, which proves vital in data-rich environments where interactions are not merely pairwise. As data complexity and interconnectivity grow, it is common for graph-structured data to be split and stored in a distributed manner, underscoring the necessity of federated learning on subgraphs. In this work, we propose FedHGN, a novel algorithm for federated hypergraph learning. Our algorithm utilizes subgraphs of a hypergraph stored on distributed devices to train local HGNN models in a federated manner:by collaboratively developing an effective global HGNN model through sharing model parameters while preserving client privacy. Additionally, considering that hyperedges may span multiple clients, a pre-training step is employed before the training process in which cross-client hyperedge feature gathering is performed at the central server. In this way, the missing cross-client information can be supplemented from the central server during the node feature aggregation phase. Experimental results on seven real-world datasets confirm the effectiveness of our approach and demonstrate its performance advantages over traditional federated graph learning methods.
Large Language Model assisted End-to-End Network Health Management based on Multi-Scale Semanticization
Jun 12, 2024



Network device and system health management is the foundation of modern network operations and maintenance. Traditional health management methods, relying on expert identification or simple rule-based algorithms, struggle to cope with the dynamic heterogeneous networks (DHNs) environment. Moreover, current state-of-the-art distributed anomaly detection methods, which utilize specific machine learning techniques, lack multi-scale adaptivity for heterogeneous device information, resulting in unsatisfactory diagnostic accuracy for DHNs. In this paper, we develop an LLM-assisted end-to-end intelligent network health management framework. The framework first proposes a Multi-Scale Semanticized Anomaly Detection Model (MSADM), incorporating semantic rule trees with an attention mechanism to address the multi-scale anomaly detection problem in DHNs. Secondly, a chain-of-thought-based large language model is embedded in downstream to adaptively analyze the fault detection results and produce an analysis report with detailed fault information and optimization strategies. Experimental results show that the accuracy of our proposed MSADM for heterogeneous network entity anomaly detection is as high as 91.31\%.