 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSAINet: An Efficient Dual-Scale Attentive Interaction Network for General EEG Decoding
Apr 20, 2026In real-world applications of noninvasive electroencephalography (EEG), specialized decoders often show limited generalizability across diverse tasks under subject-independent settings. One central challenge is that task-relevant EEG signals often follow different temporal organization patterns across tasks, while many existing methods rely on task-tailored architectural designs that introduce task-specific temporal inductive biases. This mismatch makes it difficult to adapt temporal modeling across tasks without changing the model configuration. To address these challenges, we propose DSAINet, an efficient dual-scale attentive interaction network for general EEG decoding. Specifically, DSAINet constructs shared spatiotemporal token representations from raw EEG signals and models diverse temporal dynamics through parallel convolutional branches at fine and coarse scales. The resulting representations are then adaptively refined by intra-branch attention to emphasize salient scale-specific patterns and by inter-branch attention to integrate task-relevant features across scales, followed by adaptive token aggregation to yield a compact representation for prediction. Extensive experiments on five downstream EEG decoding tasks across ten public datasets show that DSAINet consistently outperforms 13 representative baselines under strict subject-independent evaluation. Notably, this performance is achieved using the same architecture hyperparameters across datasets. Moreover, DSAINet achieves a favorable accuracy-efficiency trade-off with only about 77K trainable parameters and provides interpretable neurophysiological insights. The code is publicly available at https://github.com/zy0929/DSAINet.
SEA-Nav: Efficient Policy Learning for Safe and Agile Quadruped Navigation in Cluttered Environments
Mar 10, 2026Efficiently training quadruped robot navigation in densely cluttered environments remains a significant challenge. Existing methods are either limited by a lack of safety and agility in simple obstacle distributions or suffer from slow locomotion in complex environments, often requiring excessively long training phases. To this end, we propose SEA-Nav (Safe, Efficient, and Agile Navigation), a reinforcement learning framework for quadruped navigation. Within diverse and dense obstacle environments, a differentiable control barrier function (CBF)-based shield constraints the navigation policy to output safe velocity commands. An adaptive collision replay mechanism and hazardous exploration rewards are introduced to increase the probability of learning from critical experiences, guiding efficient exploration and exploitation. Finally, kinematic action constraints are incorporated to ensure safe velocity commands, facilitating successful physical deployment. To the best of our knowledge, this is the first approach that achieves highly challenging quadruped navigation in the real world with minute-level training time.
Federated Hypergraph Learning with Hyperedge Completion
Aug 09, 2024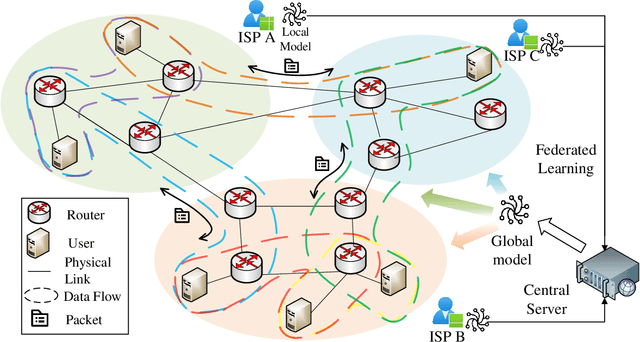
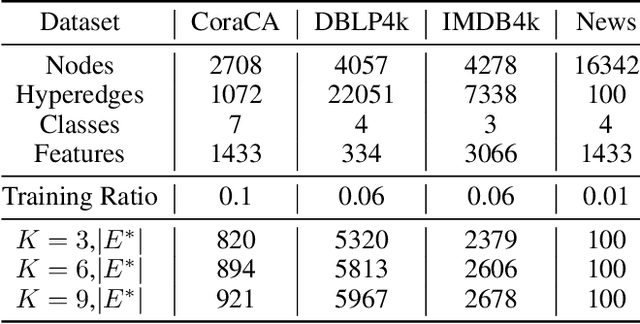
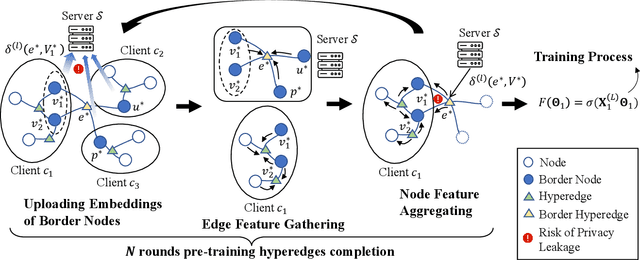
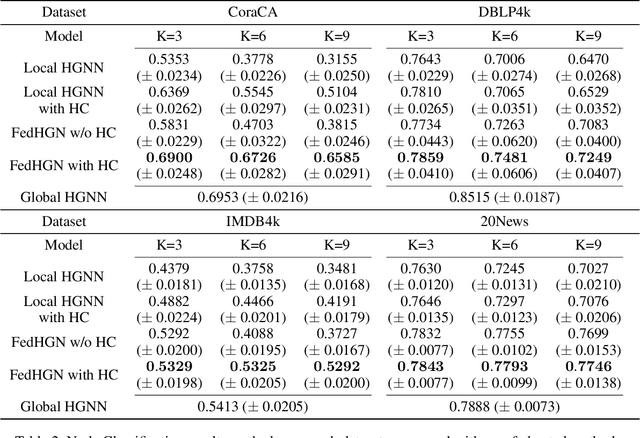
Hypergraph neural networks enhance conventional graph neural networks by capturing high-order relationships among nodes, which proves vital in data-rich environments where interactions are not merely pairwise. As data complexity and interconnectivity grow, it is common for graph-structured data to be split and stored in a distributed manner, underscoring the necessity of federated learning on subgraphs. In this work, we propose FedHGN, a novel algorithm for federated hypergraph learning. Our algorithm utilizes subgraphs of a hypergraph stored on distributed devices to train local HGNN models in a federated manner:by collaboratively developing an effective global HGNN model through sharing model parameters while preserving client privacy. Additionally, considering that hyperedges may span multiple clients, a pre-training step is employed before the training process in which cross-client hyperedge feature gathering is performed at the central server. In this way, the missing cross-client information can be supplemented from the central server during the node feature aggregation phase. Experimental results on seven real-world datasets confirm the effectiveness of our approach and demonstrate its performance advantages over traditional federated graph learning methods.
Provable Stochastic Optimization for Global Contrastive Learning: Small Batch Does Not Harm Performance
Feb 24, 2022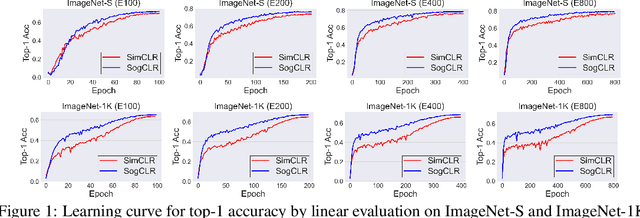
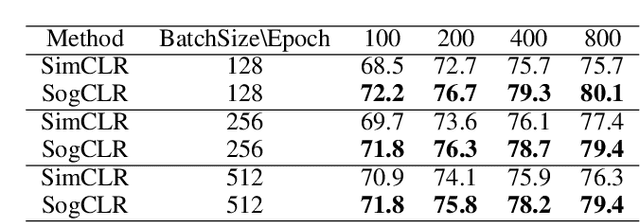
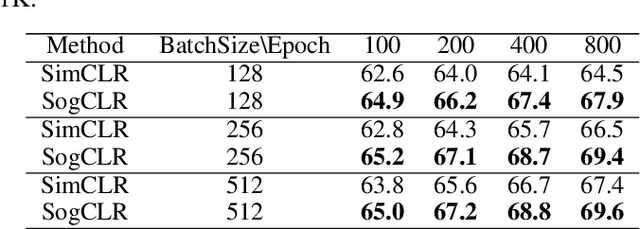
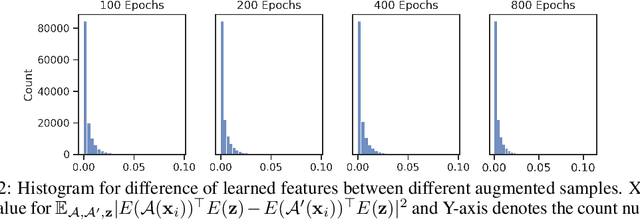
In this paper, we study contrastive learning from an optimization perspective, aiming to analyze and address a fundamental issue of existing contrastive learning methods that either rely on a large batch size or a large dictionary. We consider a global objective for contrastive learning, which contrasts each positive pair with all negative pairs for an anchor point. From the optimization perspective, we explain why existing methods such as SimCLR requires a large batch size in order to achieve a satisfactory result. In order to remove such requirement, we propose a memory-efficient Stochastic Optimization algorithm for solving the Global objective of Contrastive Learning of Representations, named SogCLR. We show that its optimization error is negligible under a reasonable condition after a sufficient number of iterations or is diminishing for a slightly different global contrastive objective. Empirically, we demonstrate that on ImageNet with a batch size 256, SogCLR achieves a performance of 69.4% for top-1 linear evaluation accuracy using ResNet-50, which is on par with SimCLR (69.3%) with a large batch size 8,192. We also attempt to show that the proposed optimization technique is generic and can be applied to solving other contrastive losses, e.g., two-way contrastive losses for bimodal contrastive learning.