 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Covariance Trap: Unlocking Generalization in Same-Subject Knowledge Editing for Large Language Models
Mar 16, 2026While locate-then-edit knowledge editing efficiently updates knowledge encoded within Large Language Models (LLMs), a critical generalization failure mode emerges in the practical same-subject knowledge editing scenario: models fail to recall the updated knowledge when following user instructions, despite successfully recalling it in the original edited form. This paper identifies the geometric root of this generalization collapse as a fundamental conflict where the inner activation drifts induced by prompt variations exceed the model's geometric tolerance for generalization after editing. We attribute this instability to a dual pathology: (1) The joint optimization with orthogonal gradients collapses solutions into sharp minima with narrow stability, and (2) the standard covariance constraint paradoxically acts as a Covariance Trap that amplifies input perturbations. To resolve this, we introduce RoSE (Robust Same-subject Editing), which employs Isotropic Geometric Alignment to minimize representational deviation and Hierarchical Knowledge Integration to smooth the optimization landscape. Extensive experiments demonstrate that RoSE significantly improves instruction-following capabilities, laying the foundation for robust interactive parametric memory of LLM agents.
System 1&2 Synergy via Dynamic Model Interpolation
Jan 29, 2026Training a unified language model that adapts between intuitive System 1 and deliberative System 2 remains challenging due to interference between their cognitive modes. Recent studies have thus pursued making System 2 models more efficient. However, these approaches focused on output control, limiting what models produce. We argue that this paradigm is misaligned: output length is merely a symptom of the model's cognitive configuration, not the root cause. In this work, we shift the focus to capability control, which modulates \textit{how models think} rather than \textit{what they produce}. To realize this, we leverage existing Instruct and Thinking checkpoints through dynamic parameter interpolation, without additional training. Our pilot study establishes that linear interpolation yields a convex, monotonic Pareto frontier, underpinned by representation continuity and structural connectivity. Building on this, we propose \textbf{DAMI} (\textbf{D}yn\textbf{A}mic \textbf{M}odel \textbf{I}nterpolation), a framework that estimates a query-specific Reasoning Intensity $λ(q)$ to configure cognitive depth. For training-based estimation, we develop a preference learning method encoding accuracy and efficiency criteria. For zero-shot deployment, we introduce a confidence-based method leveraging inter-model cognitive discrepancy. Experiments on five mathematical reasoning benchmarks demonstrate that DAMI achieves higher accuracy than the Thinking model while remaining efficient, effectively combining the efficiency of System 1 with the reasoning depth of System 2.
Adapt Once, Thrive with Updates: Transferable Parameter-Efficient Fine-Tuning on Evolving Base Models
Jun 07, 2025Parameter-efficient fine-tuning (PEFT) has become a common method for fine-tuning large language models, where a base model can serve multiple users through PEFT module switching. To enhance user experience, base models require periodic updates. However, once updated, PEFT modules fine-tuned on previous versions often suffer substantial performance degradation on newer versions. Re-tuning these numerous modules to restore performance would incur significant computational costs. Through a comprehensive analysis of the changes that occur during base model updates, we uncover an interesting phenomenon: continual training primarily affects task-specific knowledge stored in Feed-Forward Networks (FFN), while having less impact on the task-specific pattern in the Attention mechanism. Based on these findings, we introduce Trans-PEFT, a novel approach that enhances the PEFT module by focusing on the task-specific pattern while reducing its dependence on certain knowledge in the base model. Further theoretical analysis supports our approach. Extensive experiments across 7 base models and 12 datasets demonstrate that Trans-PEFT trained modules can maintain performance on updated base models without re-tuning, significantly reducing maintenance overhead in real-world applications.
Unveiling and Eliminating the Shortcut Learning for Locate-Then-Edit Knowledge Editing via Both Subject and Relation Awareness
Jun 04, 2025Knowledge editing aims to alternate the target knowledge predicted by large language models while ensuring the least side effects on unrelated knowledge. An effective way to achieve knowledge editing is to identify pivotal parameters for predicting factual associations and modify them with an optimization process to update the predictions. However, these locate-then-edit methods are uncontrollable since they tend to modify most unrelated relations connected to the subject of target editing. We unveil that this failure of controllable editing is due to a shortcut learning issue during the optimization process. Specifically, we discover two crucial features that are the subject feature and the relation feature for models to learn during optimization, but the current optimization process tends to over-learning the subject feature while neglecting the relation feature. To eliminate this shortcut learning of the subject feature, we propose a novel two-stage optimization process that balances the learning of the subject feature and the relation feature. Experimental results demonstrate that our approach successfully prevents knowledge editing from shortcut learning and achieves the optimal overall performance, contributing to controllable knowledge editing.
BeamLoRA: Beam-Constraint Low-Rank Adaptation
Feb 19, 2025Due to the demand for efficient fine-tuning of large language models, Low-Rank Adaptation (LoRA) has been widely adopted as one of the most effective parameter-efficient fine-tuning methods. Nevertheless, while LoRA improves efficiency, there remains room for improvement in accuracy. Herein, we adopt a novel perspective to assess the characteristics of LoRA ranks. The results reveal that different ranks within the LoRA modules not only exhibit varying levels of importance but also evolve dynamically throughout the fine-tuning process, which may limit the performance of LoRA. Based on these findings, we propose BeamLoRA, which conceptualizes each LoRA module as a beam where each rank naturally corresponds to a potential sub-solution, and the fine-tuning process becomes a search for the optimal sub-solution combination. BeamLoRA dynamically eliminates underperforming sub-solutions while expanding the parameter space for promising ones, enhancing performance with a fixed rank. Extensive experiments across three base models and 12 datasets spanning math reasoning, code generation, and commonsense reasoning demonstrate that BeamLoRA consistently enhances the performance of LoRA, surpassing the other baseline methods.
Relation Also Knows: Rethinking the Recall and Editing of Factual Associations in Auto-Regressive Transformer Language Models
Aug 27, 2024



The storage and recall of factual associations in auto-regressive transformer language models (LMs) have drawn a great deal of attention, inspiring knowledge editing by directly modifying the located model weights. Most editing works achieve knowledge editing under the guidance of existing interpretations of knowledge recall that mainly focus on subject knowledge. However, these interpretations are seriously flawed, neglecting relation information and leading to the over-generalizing problem for editing. In this work, we discover a novel relation-focused perspective to interpret the knowledge recall of transformer LMs during inference and apply it on knowledge editing to avoid over-generalizing. Experimental results on the dataset supplemented with a new R-Specificity criterion demonstrate that our editing approach significantly alleviates over-generalizing while remaining competitive on other criteria, breaking the domination of subject-focused editing for future research.
Federated Hypergraph Learning with Hyperedge Completion
Aug 09, 2024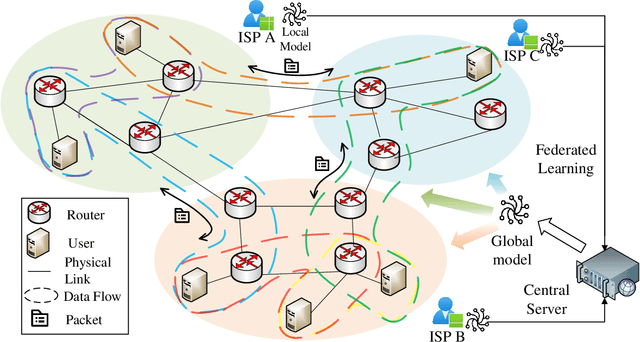
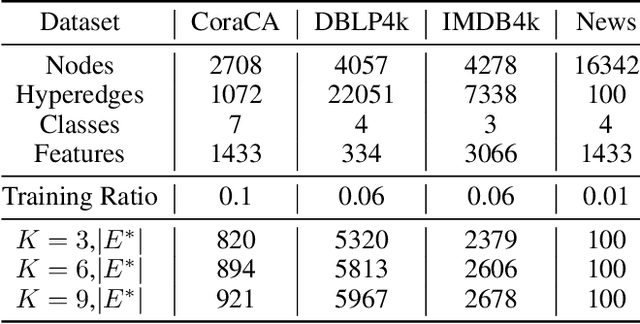
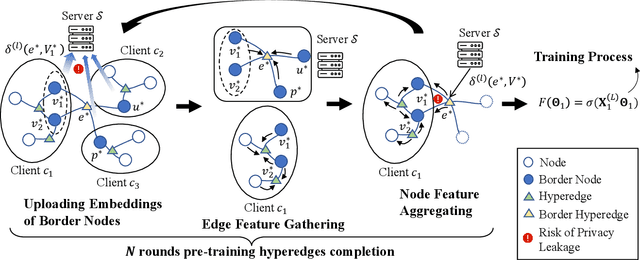
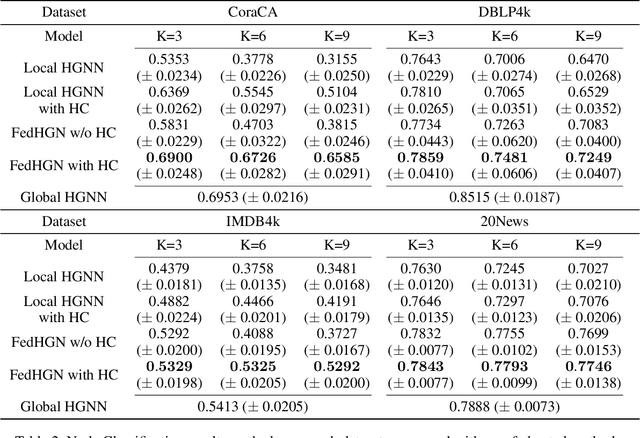
Hypergraph neural networks enhance conventional graph neural networks by capturing high-order relationships among nodes, which proves vital in data-rich environments where interactions are not merely pairwise. As data complexity and interconnectivity grow, it is common for graph-structured data to be split and stored in a distributed manner, underscoring the necessity of federated learning on subgraphs. In this work, we propose FedHGN, a novel algorithm for federated hypergraph learning. Our algorithm utilizes subgraphs of a hypergraph stored on distributed devices to train local HGNN models in a federated manner:by collaboratively developing an effective global HGNN model through sharing model parameters while preserving client privacy. Additionally, considering that hyperedges may span multiple clients, a pre-training step is employed before the training process in which cross-client hyperedge feature gathering is performed at the central server. In this way, the missing cross-client information can be supplemented from the central server during the node feature aggregation phase. Experimental results on seven real-world datasets confirm the effectiveness of our approach and demonstrate its performance advantages over traditional federated graph learning methods.
Light-PEFT: Lightening Parameter-Efficient Fine-Tuning via Early Pruning
Jun 06, 2024Parameter-efficient fine-tuning (PEFT) has emerged as the predominant technique for fine-tuning in the era of large language models. However, existing PEFT methods still have inadequate training efficiency. Firstly, the utilization of large-scale foundation models during the training process is excessively redundant for certain fine-tuning tasks. Secondly, as the model size increases, the growth in trainable parameters of empirically added PEFT modules becomes non-negligible and redundant, leading to inefficiency. To achieve task-specific efficient fine-tuning, we propose the Light-PEFT framework, which includes two methods: Masked Early Pruning of the Foundation Model and Multi-Granularity Early Pruning of PEFT. The Light-PEFT framework allows for the simultaneous estimation of redundant parameters in both the foundation model and PEFT modules during the early stage of training. These parameters can then be pruned for more efficient fine-tuning. We validate our approach on GLUE, SuperGLUE, QA tasks, and various models. With Light-PEFT, parameters of the foundation model can be pruned by up to over 40%, while still controlling trainable parameters to be only 25% of the original PEFT method. Compared to utilizing the PEFT method directly, Light-PEFT achieves training and inference speedup, reduces memory usage, and maintains comparable performance and the plug-and-play feature of PEFT.