 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSITA: A Framework for Structure-to-Instance Theorem Autoformalization
Nov 13, 2025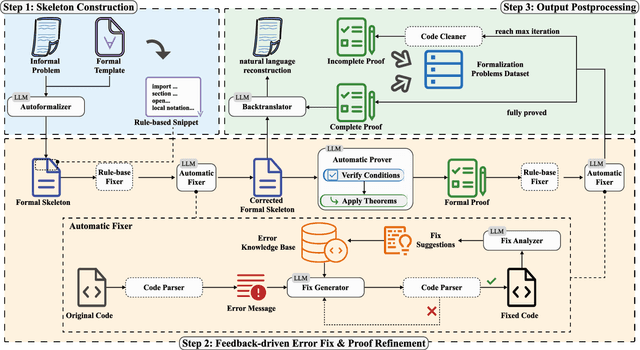
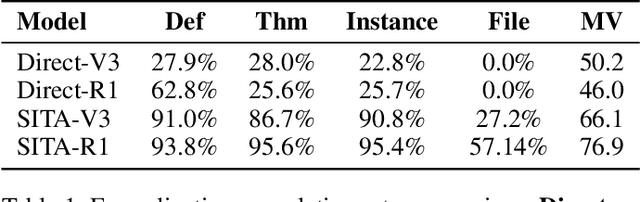
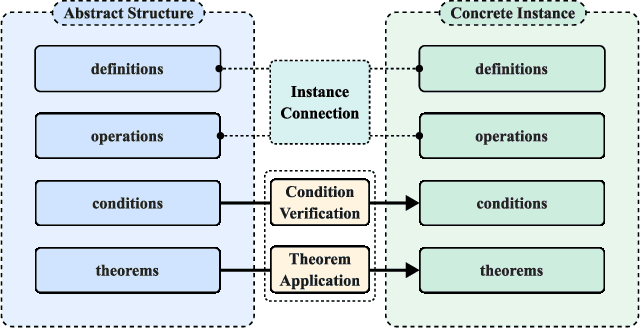
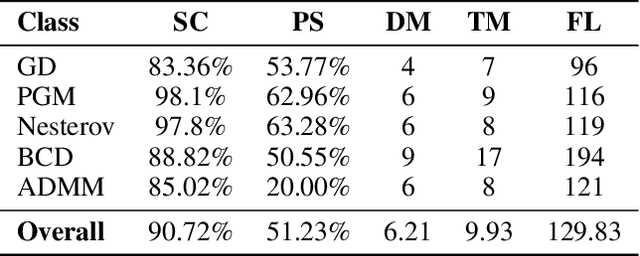
While large language models (LLMs) have shown progress in mathematical reasoning, they still face challenges in formalizing theorems that arise from instantiating abstract structures in concrete settings. With the goal of auto-formalizing mathematical results at the research level, we develop a framework for structure-to-instance theorem autoformalization (SITA), which systematically bridges the gap between abstract mathematical theories and their concrete applications in Lean proof assistant. Formalized abstract structures are treated as modular templates that contain definitions, assumptions, operations, and theorems. These templates serve as reusable guides for the formalization of concrete instances. Given a specific instantiation, we generate corresponding Lean definitions and instance declarations, integrate them using Lean's typeclass mechanism, and construct verified theorems by checking structural assumptions. We incorporate LLM-based generation with feedback-guided refinement to ensure both automation and formal correctness. Experiments on a dataset of optimization problems demonstrate that SITA effectively formalizes diverse instances grounded in abstract structures.
Core-Set Selection for Data-efficient Land Cover Segmentation
May 02, 2025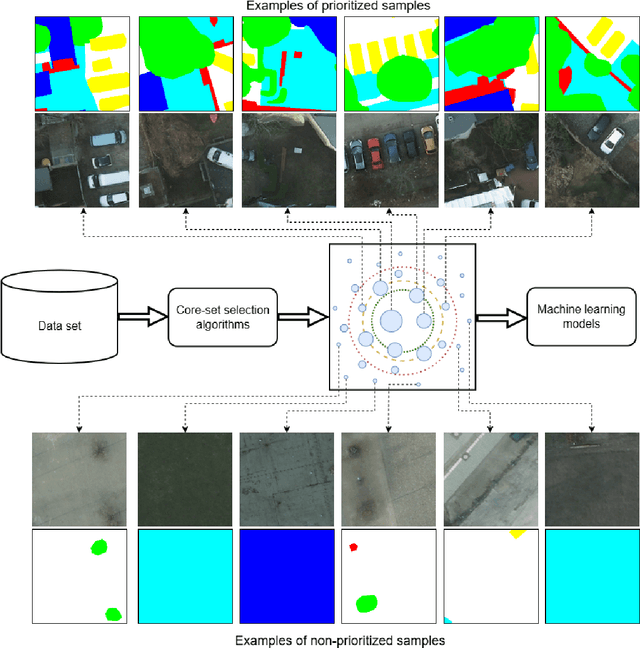


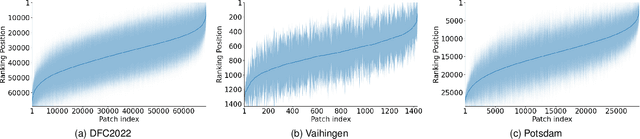
The increasing accessibility of remotely sensed data and the potential of such data to inform large-scale decision-making has driven the development of deep learning models for many Earth Observation tasks. Traditionally, such models must be trained on large datasets. However, the common assumption that broadly larger datasets lead to better outcomes tends to overlook the complexities of the data distribution, the potential for introducing biases and noise, and the computational resources required for processing and storing vast datasets. Therefore, effective solutions should consider both the quantity and quality of data. In this paper, we propose six novel core-set selection methods for selecting important subsets of samples from remote sensing image segmentation datasets that rely on imagery only, labels only, and a combination of each. We benchmark these approaches against a random-selection baseline on three commonly used land cover classification datasets: DFC2022, Vaihingen, and Potsdam. In each of the datasets, we demonstrate that training on a subset of samples outperforms the random baseline, and some approaches outperform training on all available data. This result shows the importance and potential of data-centric learning for the remote sensing domain. The code is available at https://github.com/keillernogueira/data-centric-rs-classification/.
Integrating Semi-Supervised and Active Learning for Semantic Segmentation
Jan 31, 2025



In this paper, we propose a novel active learning approach integrated with an improved semi-supervised learning framework to reduce the cost of manual annotation and enhance model performance. Our proposed approach effectively leverages both the labelled data selected through active learning and the unlabelled data excluded from the selection process. The proposed active learning approach pinpoints areas where the pseudo-labels are likely to be inaccurate. Then, an automatic and efficient pseudo-label auto-refinement (PLAR) module is proposed to correct pixels with potentially erroneous pseudo-labels by comparing their feature representations with those of labelled regions. This approach operates without increasing the labelling budget and is based on the cluster assumption, which states that pixels belonging to the same class should exhibit similar representations in feature space. Furthermore, manual labelling is only applied to the most difficult and uncertain areas in unlabelled data, where insufficient information prevents the PLAR module from making a decision. We evaluated the proposed hybrid semi-supervised active learning framework on two benchmark datasets, one from natural and the other from remote sensing imagery domains. In both cases, it outperformed state-of-the-art methods in the semantic segmentation task.
Patch-GAN Transfer Learning with Reconstructive Models for Cloud Removal
Jan 09, 2025Cloud removal plays a crucial role in enhancing remote sensing image analysis, yet accurately reconstructing cloud-obscured regions remains a significant challenge. Recent advancements in generative models have made the generation of realistic images increasingly accessible, offering new opportunities for this task. Given the conceptual alignment between image generation and cloud removal tasks, generative models present a promising approach for addressing cloud removal in remote sensing. In this work, we propose a deep transfer learning approach built on a generative adversarial network (GAN) framework to explore the potential of the novel masked autoencoder (MAE) image reconstruction model in cloud removal. Due to the complexity of remote sensing imagery, we further propose using a patch-wise discriminator to determine whether each patch of the image is real or not. The proposed reconstructive transfer learning approach demonstrates significant improvements in cloud removal performance compared to other GAN-based methods. Additionally, whilst direct comparisons with some of the state-of-the-art cloud removal techniques are limited due to unclear details regarding their train/test data splits, the proposed model achieves competitive results based on available benchmarks.
Relation Also Knows: Rethinking the Recall and Editing of Factual Associations in Auto-Regressive Transformer Language Models
Aug 27, 2024



The storage and recall of factual associations in auto-regressive transformer language models (LMs) have drawn a great deal of attention, inspiring knowledge editing by directly modifying the located model weights. Most editing works achieve knowledge editing under the guidance of existing interpretations of knowledge recall that mainly focus on subject knowledge. However, these interpretations are seriously flawed, neglecting relation information and leading to the over-generalizing problem for editing. In this work, we discover a novel relation-focused perspective to interpret the knowledge recall of transformer LMs during inference and apply it on knowledge editing to avoid over-generalizing. Experimental results on the dataset supplemented with a new R-Specificity criterion demonstrate that our editing approach significantly alleviates over-generalizing while remaining competitive on other criteria, breaking the domination of subject-focused editing for future research.
Understanding Auditory Evoked Brain Signal via Physics-informed Embedding Network with Multi-Task Transformer
Jun 04, 2024


In the fields of brain-computer interaction and cognitive neuroscience, effective decoding of auditory signals from task-based functional magnetic resonance imaging (fMRI) is key to understanding how the brain processes complex auditory information. Although existing methods have enhanced decoding capabilities, limitations remain in information utilization and model representation. To overcome these challenges, we propose an innovative multi-task learning model, Physics-informed Embedding Network with Multi-Task Transformer (PEMT-Net), which enhances decoding performance through physics-informed embedding and deep learning techniques. PEMT-Net consists of two principal components: feature augmentation and classification. For feature augmentation, we propose a novel approach by creating neural embedding graphs via node embedding, utilizing random walks to simulate the physical diffusion of neural information. This method captures both local and non-local information overflow and proposes a position encoding based on relative physical coordinates. In the classification segment, we propose adaptive embedding fusion to maximally capture linear and non-linear characteristics. Furthermore, we propose an innovative parameter-sharing mechanism to optimize the retention and learning of extracted features. Experiments on a specific dataset demonstrate PEMT-Net's significant performance in multi-task auditory signal decoding, surpassing existing methods and offering new insights into the brain's mechanisms for processing complex auditory information.
Knowledge Distillation for Road Detection based on cross-model Semi-Supervised Learning
Feb 07, 2024The advancement of knowledge distillation has played a crucial role in enabling the transfer of knowledge from larger teacher models to smaller and more efficient student models, and is particularly beneficial for online and resource-constrained applications. The effectiveness of the student model heavily relies on the quality of the distilled knowledge received from the teacher. Given the accessibility of unlabelled remote sensing data, semi-supervised learning has become a prevalent strategy for enhancing model performance. However, relying solely on semi-supervised learning with smaller models may be insufficient due to their limited capacity for feature extraction. This limitation restricts their ability to exploit training data. To address this issue, we propose an integrated approach that combines knowledge distillation and semi-supervised learning methods. This hybrid approach leverages the robust capabilities of large models to effectively utilise large unlabelled data whilst subsequently providing the small student model with rich and informative features for enhancement. The proposed semi-supervised learning-based knowledge distillation (SSLKD) approach demonstrates a notable improvement in the performance of the student model, in the application of road segmentation, surpassing the effectiveness of traditional semi-supervised learning methods.
DiverseNet: Decision Diversified Semi-supervised Semantic Segmentation Networks for Remote Sensing Imagery
Nov 22, 2023Semi-supervised learning is designed to help reduce the cost of the manual labelling process by exploiting the use of useful features from a large quantity of unlabelled data during training. Since pixel-level manual labelling in large-scale remote sensing imagery is expensive, semi-supervised learning becomes an appropriate solution to this. However, most of the existing semi-supervised learning methods still lack efficient perturbation methods to promote diversity of features and the precision of pseudo labels during training. In order to fill this gap, we propose DiverseNet architectures which explore multi-head and multi-model semi-supervised learning algorithms by simultaneously promoting precision and diversity during training. The two proposed methods of DiverseNet, namely the DiverseHead and DiverseModel, achieve the highest semantic segmentation performance in four widely utilised remote sensing imagery data sets compared to state-of-the-art semi-supervised learning methods. Meanwhile, the proposed DiverseHead architecture is relatively lightweight in terms of parameter space compared to the state-of-the-art methods whilst reaching high-performance results for all the tested data sets.
Confidence-Guided Semi-supervised Learning in Land Cover Classification
May 17, 2023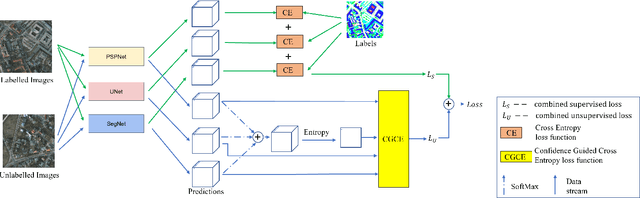



Semi-supervised learning has been well developed to help reduce the cost of manual labelling by exploiting a large quantity of unlabelled data. Especially in the application of land cover classification, pixel-level manual labelling in large-scale imagery is labour-intensive and expensive. However, the existing semi-supervised learning methods pay limited attention to the quality of pseudo-labels whilst supervising the network. That is, nevertheless, one of the critical factors determining network performance. In order to fill this gap, we develop a confidence-guided semi-supervised learning (CGSSL) approach to make use of high-confidence pseudo labels and reduce the negative effect of low-confidence ones on training the land cover classification network. Meanwhile, the proposed semi-supervised learning approach uses multiple network architectures to increase pseudo-label diversity. The proposed semi-supervised learning approach significantly improves the performance of land cover classification compared to the classical semi-supervised learning methods in computer vision and even outperforms fully supervised learning with a complete set of labelled imagery of the benchmark Potsdam land cover data set.
High-precision Density Mapping of Marine Debris and Floating Plastics via Satellite Imagery
Oct 11, 2022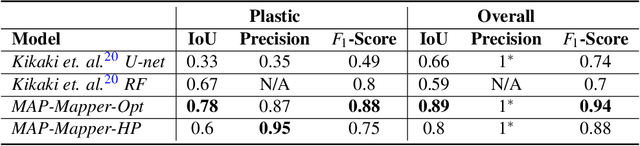
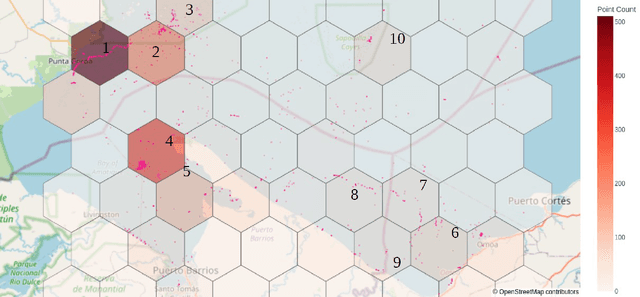
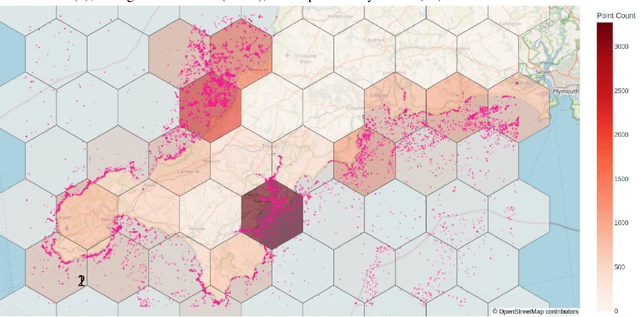
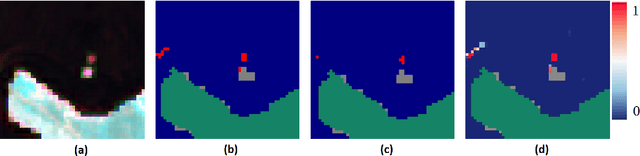
Combining multi-spectral satellite data and machine learning has been suggested as a method for monitoring plastic pollutants in the ocean environment. Recent studies have made theoretical progress regarding the identification of marine plastic via machine learning. However, no study has assessed the application of these methods for mapping and monitoring marine-plastic density. As such, this paper comprised of three main components: (1) the development of a machine learning model, (2) the construction of the MAP-Mapper, an automated tool for mapping marine-plastic density, and finally (3) an evaluation of the whole system for out-of-distribution test locations. The findings from this paper leverage the fact that machine learning models need to be high-precision to reduce the impact of false positives on results. The developed MAP-Mapper architectures provide users choices to reach high-precision ($\textit{abbv.}$ -HP) or optimum precision-recall ($\textit{abbv.}$ -Opt) values in terms of the training/test data set. Our MAP-Mapper-HP model greatly increased the precision of plastic detection to 95\%, whilst MAP-Mapper-Opt reaches precision-recall pair of 87\%-88\%. The MAP-Mapper contributes to the literature with the first tool to exploit advanced deep/machine learning and multi-spectral imagery to map marine-plastic density in automated software. The proposed data pipeline has taken a novel approach to map plastic density in ocean regions. As such, this enables an initial assessment of the challenges and opportunities of this method to help guide future work and scientific study.