 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Centric Benchmark for Label Noise Estimation and Ranking in Remote Sensing Image Segmentation
Feb 28, 2026High-quality pixel-level annotations are essential for the semantic segmentation of remote sensing imagery. However, such labels are expensive to obtain and often affected by noise due to the labor-intensive and time-consuming nature of pixel-wise annotation, which makes it challenging for human annotators to label every pixel accurately. Annotation errors can significantly degrade the performance and robustness of modern segmentation models, motivating the need for reliable mechanisms to identify and quantify noisy training samples. This paper introduces a novel Data-Centric benchmark, together with a novel, publicly available dataset and two techniques for identifying, quantifying, and ranking training samples according to their level of label noise in remote sensing semantic segmentation. Such proposed methods leverage complementary strategies based on model uncertainty, prediction consistency, and representation analysis, and consistently outperform established baselines across a range of experimental settings. The outcomes of this work are publicly available at https://github.com/keillernogueira/label_noise_segmentation.
Core-Set Selection for Data-efficient Land Cover Segmentation
May 02, 2025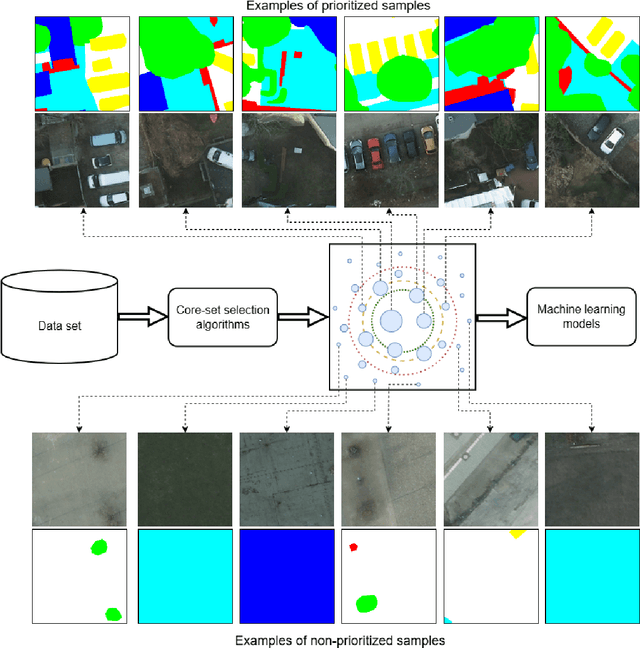


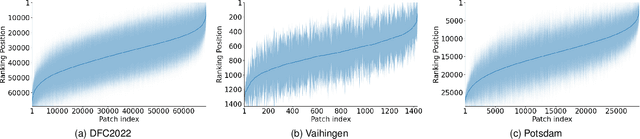
The increasing accessibility of remotely sensed data and the potential of such data to inform large-scale decision-making has driven the development of deep learning models for many Earth Observation tasks. Traditionally, such models must be trained on large datasets. However, the common assumption that broadly larger datasets lead to better outcomes tends to overlook the complexities of the data distribution, the potential for introducing biases and noise, and the computational resources required for processing and storing vast datasets. Therefore, effective solutions should consider both the quantity and quality of data. In this paper, we propose six novel core-set selection methods for selecting important subsets of samples from remote sensing image segmentation datasets that rely on imagery only, labels only, and a combination of each. We benchmark these approaches against a random-selection baseline on three commonly used land cover classification datasets: DFC2022, Vaihingen, and Potsdam. In each of the datasets, we demonstrate that training on a subset of samples outperforms the random baseline, and some approaches outperform training on all available data. This result shows the importance and potential of data-centric learning for the remote sensing domain. The code is available at https://github.com/keillernogueira/data-centric-rs-classification/.
Data-Centric Machine Learning for Geospatial Remote Sensing Data
Dec 08, 2023



Recent developments and research in modern machine learning have led to substantial improvements in the geospatial field. Although numerous deep learning models have been proposed, the majority of them have been developed on benchmark datasets that lack strong real-world relevance. Furthermore, the performance of many methods has already saturated on these datasets. We argue that shifting the focus towards a complementary data-centric perspective is necessary to achieve further improvements in accuracy, generalization ability, and real impact in end-user applications. This work presents a definition and precise categorization of automated data-centric learning approaches for geospatial data. It highlights the complementary role of data-centric learning with respect to model-centric in the larger machine learning deployment cycle. We review papers across the entire geospatial field and categorize them into different groups. A set of representative experiments shows concrete implementation examples. These examples provide concrete steps to act on geospatial data with data-centric machine learning approaches.
MTLSegFormer: Multi-task Learning with Transformers for Semantic Segmentation in Precision Agriculture
May 04, 2023



Multi-task learning has proven to be effective in improving the performance of correlated tasks. Most of the existing methods use a backbone to extract initial features with independent branches for each task, and the exchange of information between the branches usually occurs through the concatenation or sum of the feature maps of the branches. However, this type of information exchange does not directly consider the local characteristics of the image nor the level of importance or correlation between the tasks. In this paper, we propose a semantic segmentation method, MTLSegFormer, which combines multi-task learning and attention mechanisms. After the backbone feature extraction, two feature maps are learned for each task. The first map is proposed to learn features related to its task, while the second map is obtained by applying learned visual attention to locally re-weigh the feature maps of the other tasks. In this way, weights are assigned to local regions of the image of other tasks that have greater importance for the specific task. Finally, the two maps are combined and used to solve a task. We tested the performance in two challenging problems with correlated tasks and observed a significant improvement in accuracy, mainly in tasks with high dependence on the others.
GMM-IL: Image Classification using Incrementally Learnt, Independent Probabilistic Models for Small Sample Sizes
Dec 01, 2022



Current deep learning classifiers, carry out supervised learning and store class discriminatory information in a set of shared network weights. These weights cannot be easily altered to incrementally learn additional classes, since the classification weights all require retraining to prevent old class information from being lost and also require the previous training data to be present. We present a novel two stage architecture which couples visual feature learning with probabilistic models to represent each class in the form of a Gaussian Mixture Model. By using these independent class representations within our classifier, we outperform a benchmark of an equivalent network with a Softmax head, obtaining increased accuracy for sample sizes smaller than 12 and increased weighted F1 score for 3 imbalanced class profiles in that sample range. When learning new classes our classifier exhibits no catastrophic forgetting issues and only requires the new classes' training images to be present. This enables a database of growing classes over time which can be visually indexed and reasoned over.
Facing the Void: Overcoming Missing Data in Multi-View Imagery
May 21, 2022

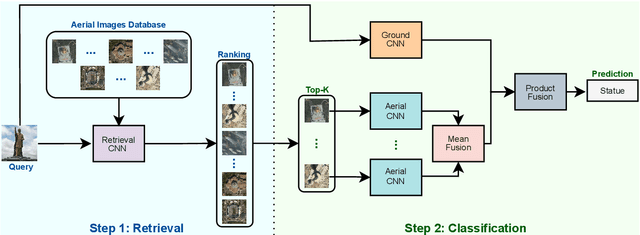

In some scenarios, a single input image may not be enough to allow the object classification. In those cases, it is crucial to explore the complementary information extracted from images presenting the same object from multiple perspectives (or views) in order to enhance the general scene understanding and, consequently, increase the performance. However, this task, commonly called multi-view image classification, has a major challenge: missing data. In this paper, we propose a novel technique for multi-view image classification robust to this problem. The proposed method, based on state-of-the-art deep learning-based approaches and metric learning, can be easily adapted and exploited in other applications and domains. A systematic evaluation of the proposed algorithm was conducted using two multi-view aerial-ground datasets with very distinct properties. Results show that the proposed algorithm provides improvements in multi-view image classification accuracy when compared to state-of-the-art methods. Code available at \url{https://github.com/Gabriellm2003/remote_sensing_missing_data}.
AiRound and CV-BrCT: Novel Multi-View Datasets for Scene Classification
Aug 03, 2020



It is undeniable that aerial/satellite images can provide useful information for a large variety of tasks. But, since these images are always looking from above, some applications can benefit from complementary information provided by other perspective views of the scene, such as ground-level images. Despite a large number of public repositories for both georeferenced photographs and aerial images, there is a lack of benchmark datasets that allow the development of approaches that exploit the benefits and complementarity of aerial/ground imagery. In this paper, we present two new publicly available datasets named \thedataset~and CV-BrCT. The first one contains triplets of images from the same geographic coordinate with different perspectives of view extracted from various places around the world. Each triplet is composed of an aerial RGB image, a ground-level perspective image, and a Sentinel-2 sample. The second dataset contains pairs of aerial and street-level images extracted from southeast Brazil. We design an extensive set of experiments concerning multi-view scene classification, using early and late fusion. Such experiments were conducted to show that image classification can be enhanced using multi-view data.
Fully Convolutional Open Set Segmentation
Jun 25, 2020
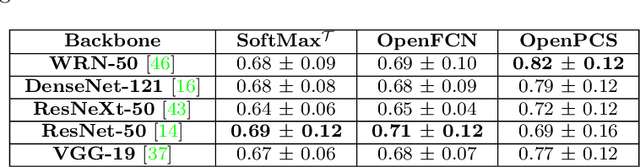


In semantic segmentation knowing about all existing classes is essential to yield effective results with the majority of existing approaches. However, these methods trained in a Closed Set of classes fail when new classes are found in the test phase. It means that they are not suitable for Open Set scenarios, which are very common in real-world computer vision and remote sensing applications. In this paper, we discuss the limitations of Closed Set segmentation and propose two fully convolutional approaches to effectively address Open Set semantic segmentation: OpenFCN and OpenPCS. OpenFCN is based on the well-known OpenMax algorithm, configuring a new application of this approach in segmentation settings. OpenPCS is a fully novel approach based on feature-space from DNN activations that serve as features for computing PCA and multi-variate gaussian likelihood in a lower dimensional space. Experiments were conducted on the well-known Vaihingen and Potsdam segmentation datasets. OpenFCN showed little-to-no improvement when compared to the simpler and much more time efficient SoftMax thresholding, while being between some orders of magnitude slower. OpenPCS achieved promising results in almost all experiments by overcoming both OpenFCN and SoftMax thresholding. OpenPCS is also a reasonable compromise between the runtime performances of the extremely fast SoftMax thresholding and the extremely slow OpenFCN, being close able to run close to real-time. Experiments also indicate that OpenPCS is effective, robust and suitable for Open Set segmentation, being able to improve the recognition of unknown class pixels without reducing the accuracy on the known class pixels.
Towards Open-Set Semantic Segmentation of Aerial Images
Jan 27, 2020


Classical and more recently deep computer vision methods are optimized for visible spectrum images, commonly encoded in grayscale or RGB colorspaces acquired from smartphones or cameras. A more uncommon source of images exploited in the remote sensing field are satellite and aerial images. However, the development of pattern recognition approaches for these data is relatively recent, mainly due to the limited availability of this type of images, as until recently they were used exclusively for military purposes. Access to aerial imagery, including spectral information, has been increasing mainly due to the low cost of drones, cheapening of imaging satellite launch costs, and novel public datasets. Usually remote sensing applications employ computer vision techniques strictly modeled for classification tasks in closed set scenarios. However, real-world tasks rarely fit into closed set contexts, frequently presenting previously unknown classes, characterizing them as open set scenarios. Focusing on this problem, this is the first paper to study and develop semantic segmentation techniques for open set scenarios applied to remote sensing images. The main contributions of this paper are: 1) a discussion of related works in open set semantic segmentation, showing evidence that these techniques can be adapted for open set remote sensing tasks; 2) the development and evaluation of a novel approach for open set semantic segmentation. Our method yielded competitive results when compared to closed set methods for the same dataset.
An Introduction to Deep Morphological Networks
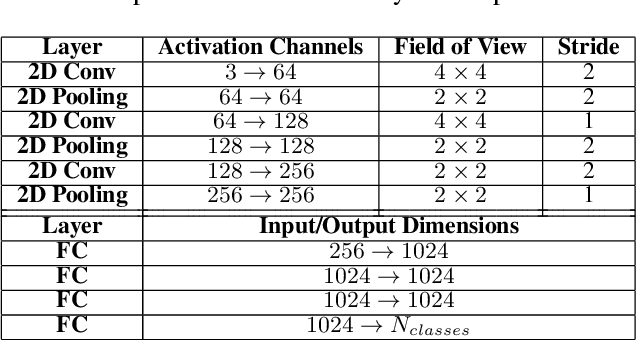
Jun 04, 2019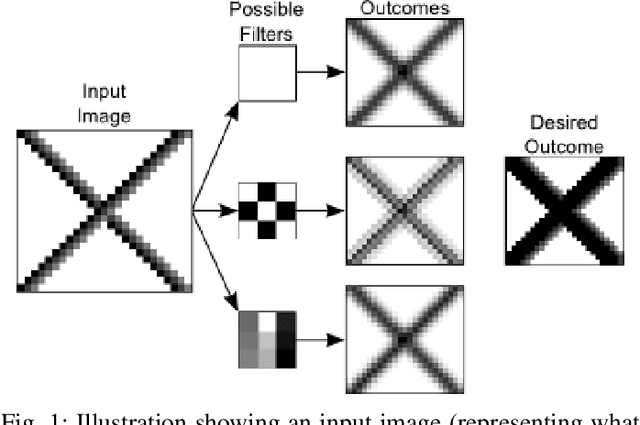
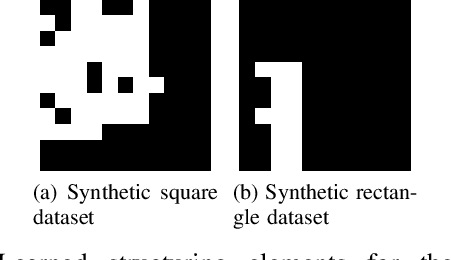

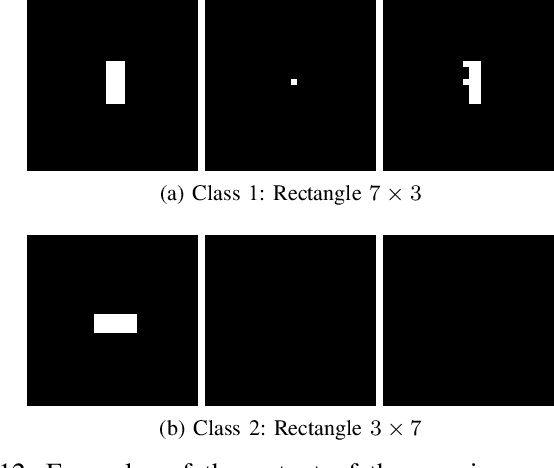
The recent impressive results of deep learning-based methods on computer vision applications brought fresh air to the research and industrial community. This success is mainly due to the process that allows those methods to learn data-driven features, generally based upon linear operations. However, in some scenarios, such operations do not have a good performance because of their inherited process that blurs edges, losing notions of corners, borders, and geometry of objects. Overcoming this, non-linear operations, such as morphological ones, may preserve such properties of the objects, being preferable and even state-of-the-art in some applications. Encouraged by this, in this work, we propose a novel network, called Deep Morphological Network (DeepMorphNet), capable of doing non-linear morphological operations while performing the feature learning process by optimizing the structuring elements. The DeepMorphNets can be trained and optimized end-to-end using traditional existing techniques commonly employed in the training of deep learning approaches. A systematic evaluation of the proposed algorithm is conducted using two synthetic and two traditional image classification datasets. Results show that the proposed DeepMorphNets is a promising technique that can learn distinct features when compared to the ones learned by current deep learning methods.