 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Longitudinal Mammogram Alignment on Breast Cancer Risk Assessment
Nov 11, 2025Regular mammography screening is crucial for early breast cancer detection. By leveraging deep learning-based risk models, screening intervals can be personalized, especially for high-risk individuals. While recent methods increasingly incorporate longitudinal information from prior mammograms, accurate spatial alignment across time points remains a key challenge. Misalignment can obscure meaningful tissue changes and degrade model performance. In this study, we provide insights into various alignment strategies, image-based registration, feature-level (representation space) alignment with and without regularization, and implicit alignment methods, for their effectiveness in longitudinal deep learning-based risk modeling. Using two large-scale mammography datasets, we assess each method across key metrics, including predictive accuracy, precision, recall, and deformation field quality. Our results show that image-based registration consistently outperforms the more recently favored feature-based and implicit approaches across all metrics, enabling more accurate, temporally consistent predictions and generating smooth, anatomically plausible deformation fields. Although regularizing the deformation field improves deformation quality, it reduces the risk prediction performance of feature-level alignment. Applying image-based deformation fields within the feature space yields the best risk prediction performance. These findings underscore the importance of image-based deformation fields for spatial alignment in longitudinal risk modeling, offering improved prediction accuracy and robustness. This approach has strong potential to enhance personalized screening and enable earlier interventions for high-risk individuals. The code is available at https://github.com/sot176/Mammogram_Alignment_Study_Risk_Prediction.git, allowing full reproducibility of the results.
Reconsidering Explicit Longitudinal Mammography Alignment for Enhanced Breast Cancer Risk Prediction
Jun 24, 2025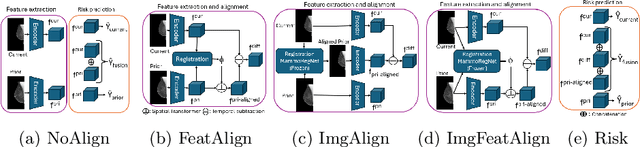
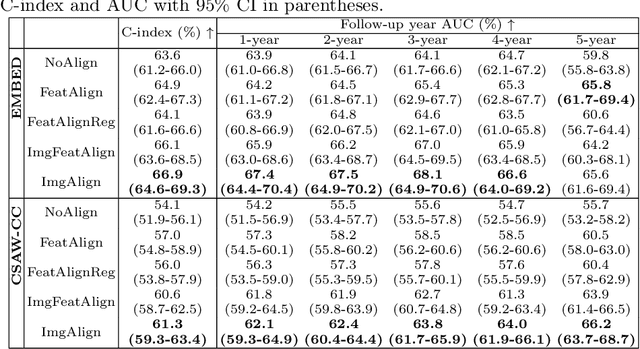
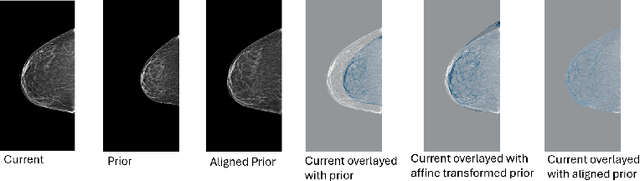

Regular mammography screening is essential for early breast cancer detection. Deep learning-based risk prediction methods have sparked interest to adjust screening intervals for high-risk groups. While early methods focused only on current mammograms, recent approaches leverage the temporal aspect of screenings to track breast tissue changes over time, requiring spatial alignment across different time points. Two main strategies for this have emerged: explicit feature alignment through deformable registration and implicit learned alignment using techniques like transformers, with the former providing more control. However, the optimal approach for explicit alignment in mammography remains underexplored. In this study, we provide insights into where explicit alignment should occur (input space vs. representation space) and if alignment and risk prediction should be jointly optimized. We demonstrate that jointly learning explicit alignment in representation space while optimizing risk estimation performance, as done in the current state-of-the-art approach, results in a trade-off between alignment quality and predictive performance and show that image-level alignment is superior to representation-level alignment, leading to better deformation field quality and enhanced risk prediction accuracy. The code is available at https://github.com/sot176/Longitudinal_Mammogram_Alignment.git.
Natural Language Processing for Electronic Health Records in Scandinavian Languages: Norwegian, Swedish, and Danish
Mar 24, 2025



Background: Clinical natural language processing (NLP) refers to the use of computational methods for extracting, processing, and analyzing unstructured clinical text data, and holds a huge potential to transform healthcare in various clinical tasks. Objective: The study aims to perform a systematic review to comprehensively assess and analyze the state-of-the-art NLP methods for the mainland Scandinavian clinical text. Method: A literature search was conducted in various online databases including PubMed, ScienceDirect, Google Scholar, ACM digital library, and IEEE Xplore between December 2022 and February 2024. Further, relevant references to the included articles were also used to solidify our search. The final pool includes articles that conducted clinical NLP in the mainland Scandinavian languages and were published in English between 2010 and 2024. Results: Out of the 113 articles, 18% (n=21) focus on Norwegian clinical text, 64% (n=72) on Swedish, 10% (n=11) on Danish, and 8% (n=9) focus on more than one language. Generally, the review identified positive developments across the region despite some observable gaps and disparities between the languages. There are substantial disparities in the level of adoption of transformer-based models. In essential tasks such as de-identification, there is significantly less research activity focusing on Norwegian and Danish compared to Swedish text. Further, the review identified a low level of sharing resources such as data, experimentation code, pre-trained models, and rate of adaptation and transfer learning in the region. Conclusion: The review presented a comprehensive assessment of the state-of-the-art Clinical NLP for electronic health records (EHR) text in mainland Scandinavian languages and, highlighted the potential barriers and challenges that hinder the rapid advancement of the field in the region.
Data-Centric Machine Learning for Geospatial Remote Sensing Data
Dec 08, 2023



Recent developments and research in modern machine learning have led to substantial improvements in the geospatial field. Although numerous deep learning models have been proposed, the majority of them have been developed on benchmark datasets that lack strong real-world relevance. Furthermore, the performance of many methods has already saturated on these datasets. We argue that shifting the focus towards a complementary data-centric perspective is necessary to achieve further improvements in accuracy, generalization ability, and real impact in end-user applications. This work presents a definition and precise categorization of automated data-centric learning approaches for geospatial data. It highlights the complementary role of data-centric learning with respect to model-centric in the larger machine learning deployment cycle. We review papers across the entire geospatial field and categorize them into different groups. A set of representative experiments shows concrete implementation examples. These examples provide concrete steps to act on geospatial data with data-centric machine learning approaches.
Self-Supervised Few-Shot Learning for Ischemic Stroke Lesion Segmentation
Mar 16, 2023Precise ischemic lesion segmentation plays an essential role in improving diagnosis and treatment planning for ischemic stroke, one of the prevalent diseases with the highest mortality rate. While numerous deep neural network approaches have recently been proposed to tackle this problem, these methods require large amounts of annotated regions during training, which can be impractical in the medical domain where annotated data is scarce. As a remedy, we present a prototypical few-shot segmentation approach for ischemic lesion segmentation using only one annotated sample during training. The proposed approach leverages a novel self-supervised training mechanism that is tailored to the task of ischemic stroke lesion segmentation by exploiting color-coded parametric maps generated from Computed Tomography Perfusion scans. We illustrate the benefits of our proposed training mechanism, leading to considerable improvements in performance in the few-shot setting. Given a single annotated patient, an average Dice score of 0.58 is achieved for the segmentation of ischemic lesions.
ProtoVAE: A Trustworthy Self-Explainable Prototypical Variational Model
Oct 15, 2022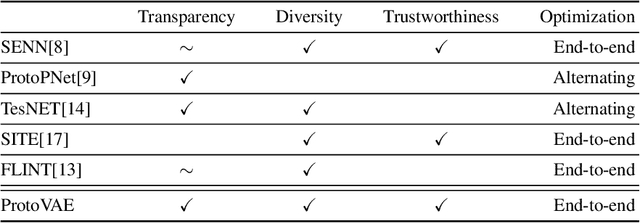
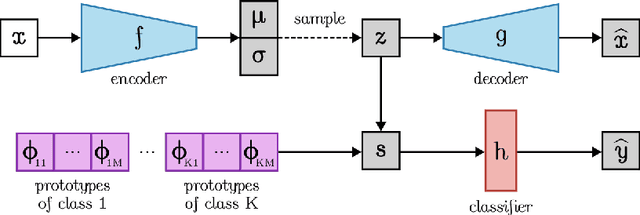
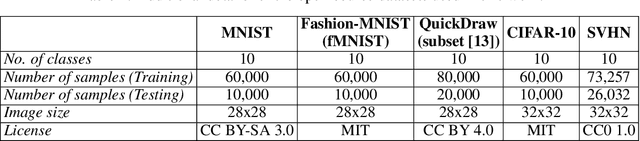
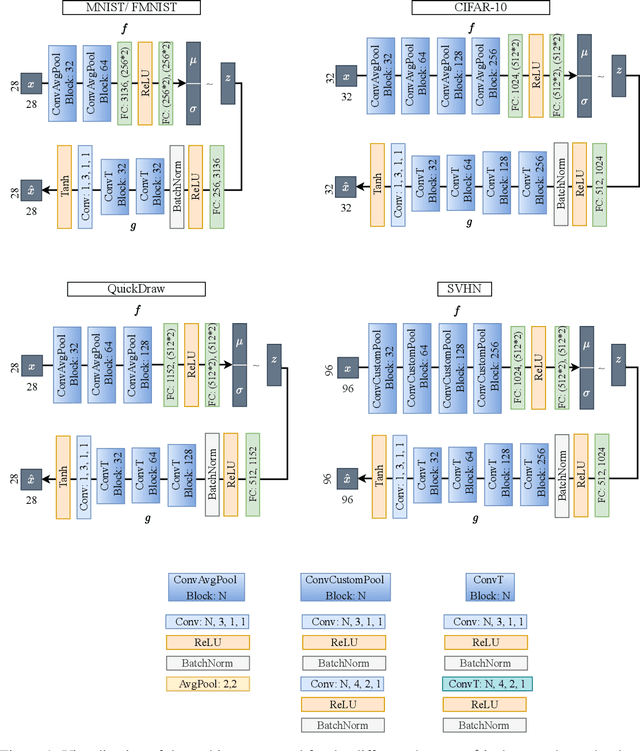
The need for interpretable models has fostered the development of self-explainable classifiers. Prior approaches are either based on multi-stage optimization schemes, impacting the predictive performance of the model, or produce explanations that are not transparent, trustworthy or do not capture the diversity of the data. To address these shortcomings, we propose ProtoVAE, a variational autoencoder-based framework that learns class-specific prototypes in an end-to-end manner and enforces trustworthiness and diversity by regularizing the representation space and introducing an orthonormality constraint. Finally, the model is designed to be transparent by directly incorporating the prototypes into the decision process. Extensive comparisons with previous self-explainable approaches demonstrate the superiority of ProtoVAE, highlighting its ability to generate trustworthy and diverse explanations, while not degrading predictive performance.
Anomaly Detection-Inspired Few-Shot Medical Image Segmentation Through Self-Supervision With Supervoxels
Mar 03, 2022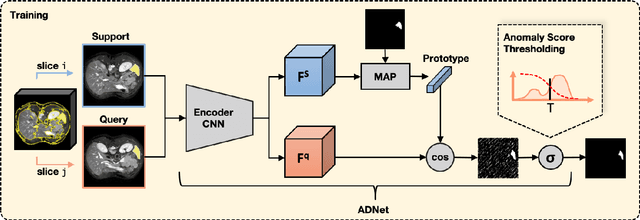

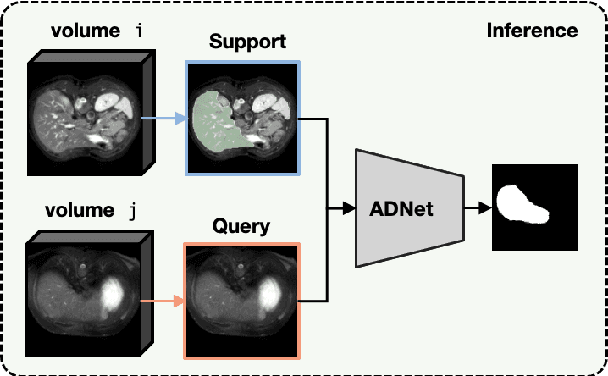

Recent work has shown that label-efficient few-shot learning through self-supervision can achieve promising medical image segmentation results. However, few-shot segmentation models typically rely on prototype representations of the semantic classes, resulting in a loss of local information that can degrade performance. This is particularly problematic for the typically large and highly heterogeneous background class in medical image segmentation problems. Previous works have attempted to address this issue by learning additional prototypes for each class, but since the prototypes are based on a limited number of slices, we argue that this ad-hoc solution is insufficient to capture the background properties. Motivated by this, and the observation that the foreground class (e.g., one organ) is relatively homogeneous, we propose a novel anomaly detection-inspired approach to few-shot medical image segmentation in which we refrain from modeling the background explicitly. Instead, we rely solely on a single foreground prototype to compute anomaly scores for all query pixels. The segmentation is then performed by thresholding these anomaly scores using a learned threshold. Assisted by a novel self-supervision task that exploits the 3D structure of medical images through supervoxels, our proposed anomaly detection-inspired few-shot medical image segmentation model outperforms previous state-of-the-art approaches on two representative MRI datasets for the tasks of abdominal organ segmentation and cardiac segmentation.
Demonstrating The Risk of Imbalanced Datasets in Chest X-ray Image-based Diagnostics by Prototypical Relevance Propagation
Jan 10, 2022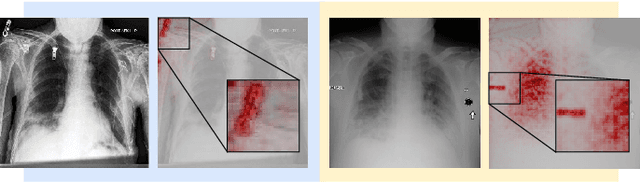

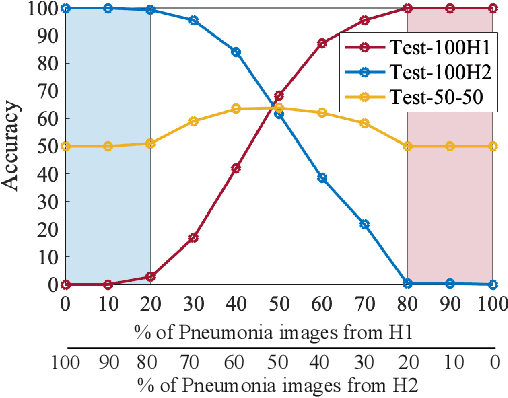

The recent trend of integrating multi-source Chest X-Ray datasets to improve automated diagnostics raises concerns that models learn to exploit source-specific correlations to improve performance by recognizing the source domain of an image rather than the medical pathology. We hypothesize that this effect is enforced by and leverages label-imbalance across the source domains, i.e, prevalence of a disease corresponding to a source. Therefore, in this work, we perform a thorough study of the effect of label-imbalance in multi-source training for the task of pneumonia detection on the widely used ChestX-ray14 and CheXpert datasets. The results highlight and stress the importance of using more faithful and transparent self-explaining models for automated diagnosis, thus enabling the inherent detection of spurious learning. They further illustrate that this undesirable effect of learning spurious correlations can be reduced considerably when ensuring label-balanced source domain datasets.
This looks more like that: Enhancing Self-Explaining Models by Prototypical Relevance Propagation
Aug 27, 2021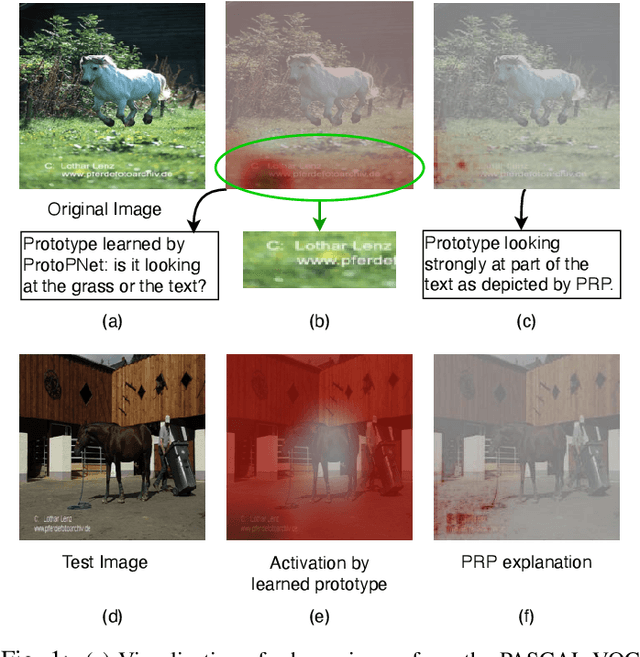
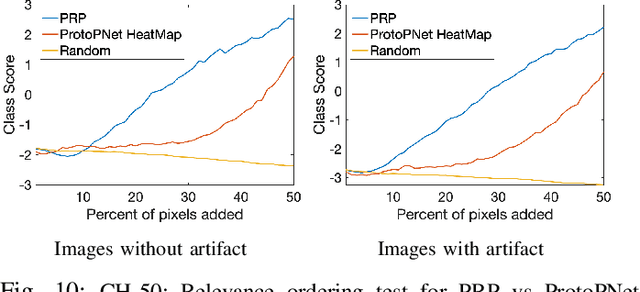

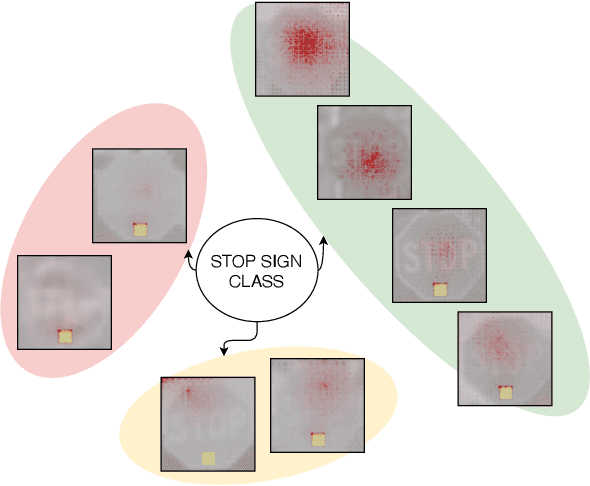
Current machine learning models have shown high efficiency in solving a wide variety of real-world problems. However, their black box character poses a major challenge for the understanding and traceability of the underlying decision-making strategies. As a remedy, many post-hoc explanation and self-explanatory methods have been developed to interpret the models' behavior. These methods, in addition, enable the identification of artifacts that can be learned by the model as class-relevant features. In this work, we provide a detailed case study of the self-explaining network, ProtoPNet, in the presence of a spectrum of artifacts. Accordingly, we identify the main drawbacks of ProtoPNet, especially, its coarse and spatially imprecise explanations. We address these limitations by introducing Prototypical Relevance Propagation (PRP), a novel method for generating more precise model-aware explanations. Furthermore, in order to obtain a clean dataset, we propose to use multi-view clustering strategies for segregating the artifact images using the PRP explanations, thereby suppressing the potential artifact learning in the models.