 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical Self-Explainable Models Without Re-training
Dec 13, 2023Explainable AI (XAI) has unfolded in two distinct research directions with, on the one hand, post-hoc methods that explain the predictions of a pre-trained black-box model and, on the other hand, self-explainable models (SEMs) which are trained directly to provide explanations alongside their predictions. While the latter is preferred in most safety-critical scenarios, post-hoc approaches have received the majority of attention until now, owing to their simplicity and ability to explain base models without retraining. Current SEMs instead, require complex architectures and heavily regularized loss functions, thus necessitating specific and costly training. To address this shortcoming and facilitate wider use of SEMs, we propose a simple yet efficient universal method called KMEx (K-Means Explainer), which can convert any existing pre-trained model into a prototypical SEM. The motivation behind KMEx is to push towards more transparent deep learning-based decision-making via class-prototype-based explanations that are guaranteed to be diverse and trustworthy without retraining the base model. We compare models obtained from KMEx to state-of-the-art SEMs using an extensive qualitative evaluation to highlight the strengths and weaknesses of each model, further paving the way toward a more reliable and objective evaluation of SEMs.
Investigating the Fairness of Large Language Models for Predictions on Tabular Data
Oct 23, 2023Recent literature has suggested the potential of using large language models (LLMs) to make predictions for tabular tasks. However, LLMs have been shown to exhibit harmful social biases that reflect the stereotypes and inequalities present in the society. To this end, as well as the widespread use of tabular data in many high-stake applications, it is imperative to explore the following questions: what sources of information do LLMs draw upon when making predictions for tabular tasks; whether and to what extent are LLM predictions for tabular tasks influenced by social biases and stereotypes; and what are the consequential implications for fairness? Through a series of experiments, we delve into these questions and show that LLMs tend to inherit social biases from their training data which significantly impact their fairness in tabular prediction tasks. Furthermore, our investigations show that in the context of bias mitigation, though in-context learning and fine-tuning have a moderate effect, the fairness metric gap between different subgroups is still larger than that in traditional machine learning models, such as Random Forest and shallow Neural Networks. This observation emphasizes that the social biases are inherent within the LLMs themselves and inherited from their pre-training corpus, not only from the downstream task datasets. Besides, we demonstrate that label-flipping of in-context examples can significantly reduce biases, further highlighting the presence of inherent bias within LLMs.
ProtoVAE: A Trustworthy Self-Explainable Prototypical Variational Model
Oct 15, 2022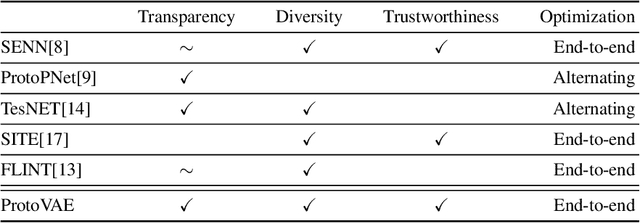
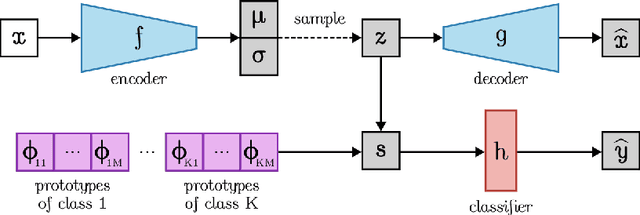
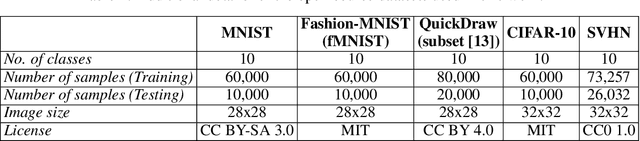
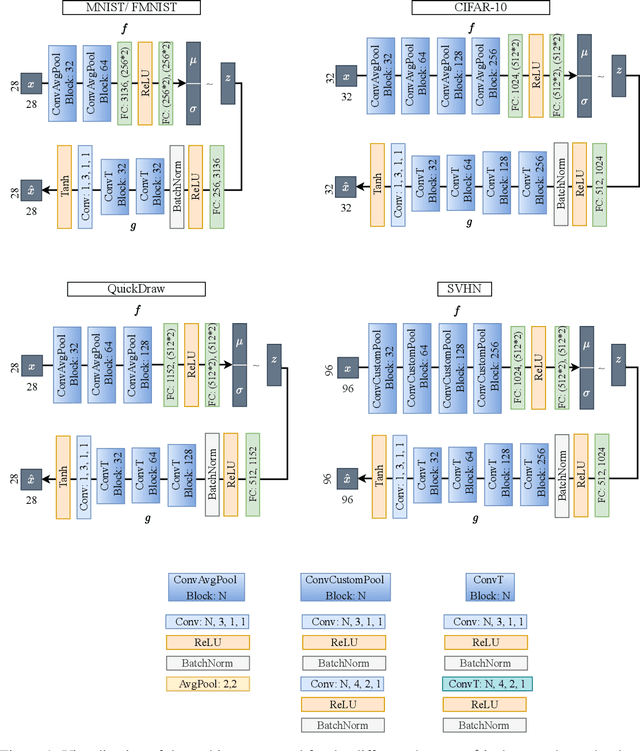
The need for interpretable models has fostered the development of self-explainable classifiers. Prior approaches are either based on multi-stage optimization schemes, impacting the predictive performance of the model, or produce explanations that are not transparent, trustworthy or do not capture the diversity of the data. To address these shortcomings, we propose ProtoVAE, a variational autoencoder-based framework that learns class-specific prototypes in an end-to-end manner and enforces trustworthiness and diversity by regularizing the representation space and introducing an orthonormality constraint. Finally, the model is designed to be transparent by directly incorporating the prototypes into the decision process. Extensive comparisons with previous self-explainable approaches demonstrate the superiority of ProtoVAE, highlighting its ability to generate trustworthy and diverse explanations, while not degrading predictive performance.
Anomaly Detection-Inspired Few-Shot Medical Image Segmentation Through Self-Supervision With Supervoxels
Mar 03, 2022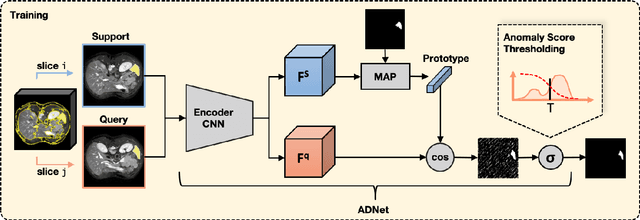

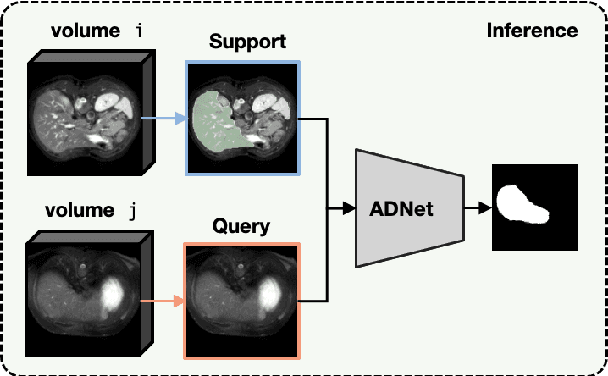

Recent work has shown that label-efficient few-shot learning through self-supervision can achieve promising medical image segmentation results. However, few-shot segmentation models typically rely on prototype representations of the semantic classes, resulting in a loss of local information that can degrade performance. This is particularly problematic for the typically large and highly heterogeneous background class in medical image segmentation problems. Previous works have attempted to address this issue by learning additional prototypes for each class, but since the prototypes are based on a limited number of slices, we argue that this ad-hoc solution is insufficient to capture the background properties. Motivated by this, and the observation that the foreground class (e.g., one organ) is relatively homogeneous, we propose a novel anomaly detection-inspired approach to few-shot medical image segmentation in which we refrain from modeling the background explicitly. Instead, we rely solely on a single foreground prototype to compute anomaly scores for all query pixels. The segmentation is then performed by thresholding these anomaly scores using a learned threshold. Assisted by a novel self-supervision task that exploits the 3D structure of medical images through supervoxels, our proposed anomaly detection-inspired few-shot medical image segmentation model outperforms previous state-of-the-art approaches on two representative MRI datasets for the tasks of abdominal organ segmentation and cardiac segmentation.
Demonstrating The Risk of Imbalanced Datasets in Chest X-ray Image-based Diagnostics by Prototypical Relevance Propagation
Jan 10, 2022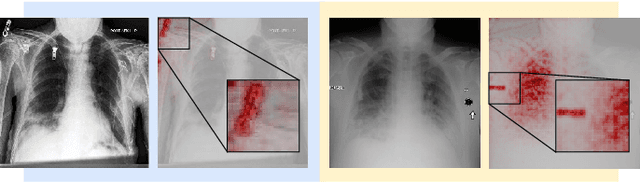

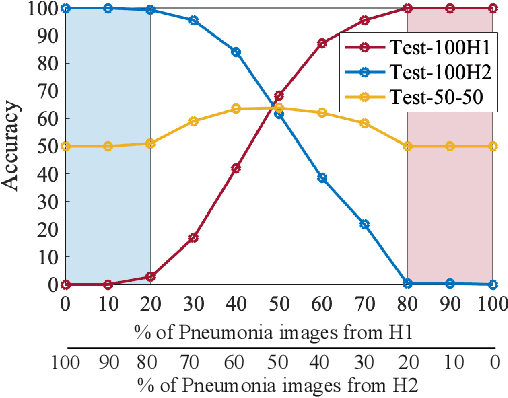

The recent trend of integrating multi-source Chest X-Ray datasets to improve automated diagnostics raises concerns that models learn to exploit source-specific correlations to improve performance by recognizing the source domain of an image rather than the medical pathology. We hypothesize that this effect is enforced by and leverages label-imbalance across the source domains, i.e, prevalence of a disease corresponding to a source. Therefore, in this work, we perform a thorough study of the effect of label-imbalance in multi-source training for the task of pneumonia detection on the widely used ChestX-ray14 and CheXpert datasets. The results highlight and stress the importance of using more faithful and transparent self-explaining models for automated diagnosis, thus enabling the inherent detection of spurious learning. They further illustrate that this undesirable effect of learning spurious correlations can be reduced considerably when ensuring label-balanced source domain datasets.
This looks more like that: Enhancing Self-Explaining Models by Prototypical Relevance Propagation
Aug 27, 2021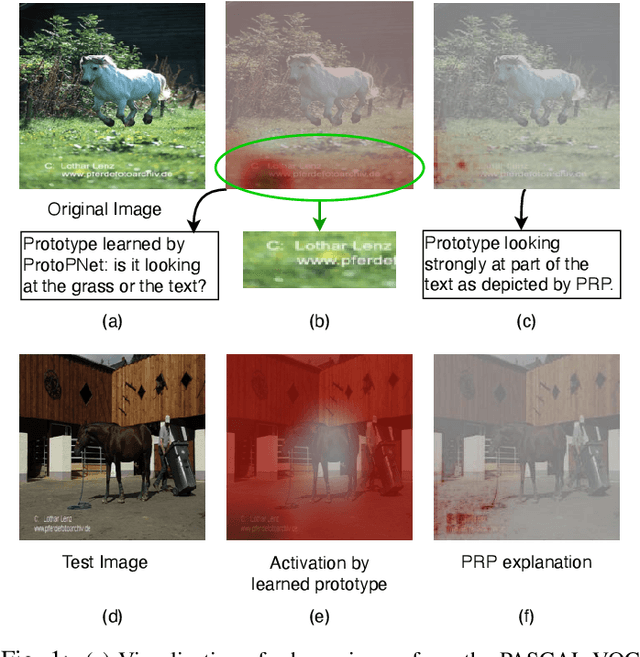
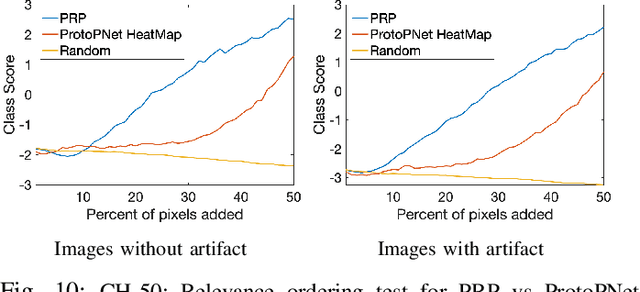

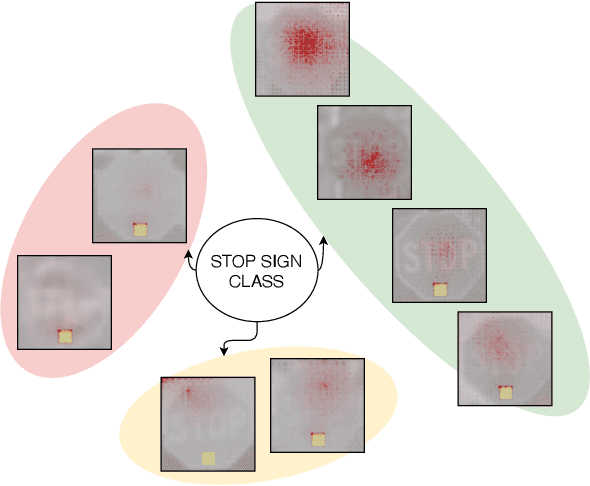
Current machine learning models have shown high efficiency in solving a wide variety of real-world problems. However, their black box character poses a major challenge for the understanding and traceability of the underlying decision-making strategies. As a remedy, many post-hoc explanation and self-explanatory methods have been developed to interpret the models' behavior. These methods, in addition, enable the identification of artifacts that can be learned by the model as class-relevant features. In this work, we provide a detailed case study of the self-explaining network, ProtoPNet, in the presence of a spectrum of artifacts. Accordingly, we identify the main drawbacks of ProtoPNet, especially, its coarse and spatially imprecise explanations. We address these limitations by introducing Prototypical Relevance Propagation (PRP), a novel method for generating more precise model-aware explanations. Furthermore, in order to obtain a clean dataset, we propose to use multi-view clustering strategies for segregating the artifact images using the PRP explanations, thereby suppressing the potential artifact learning in the models.
Considerations for a PAP Smear Image Analysis System with CNN Features
Jun 23, 2018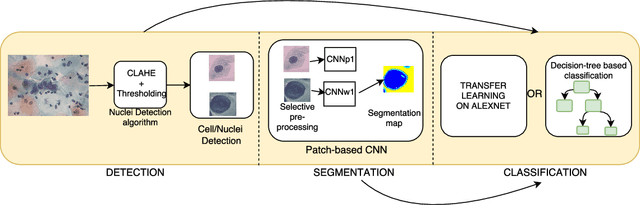

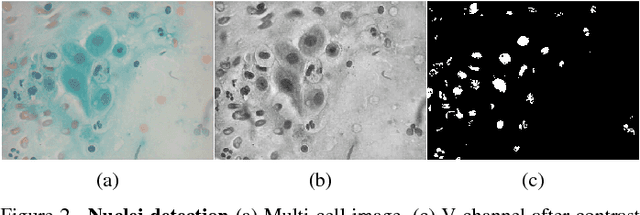
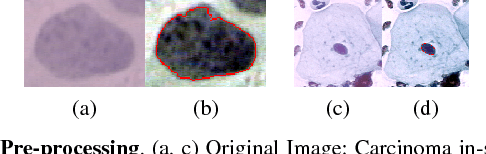
It has been shown that for automated PAP-smear image classification, nucleus features can be very informative. Therefore, the primary step for automated screening can be cell-nuclei detection followed by segmentation of nuclei in the resulting single cell PAP-smear images. We propose a patch based approach using CNN for segmentation of nuclei in single cell images. We then pose the question of ion of segmentation for classification using representation learning with CNN, and whether low-level CNN features may be useful for classification. We suggest a CNN-based feature level analysis and a transfer learning based approach for classification using both segmented as well full single cell images. We also propose a decision-tree based approach for classification. Experimental results demonstrate the effectiveness of the proposed algorithms individually (with low-level CNN features), and simultaneously proving the sufficiency of cell-nuclei detection (rather than accurate segmentation) for classification. Thus, we propose a system for analysis of multi-cell PAP-smear images consisting of a simple nuclei detection algorithm followed by classification using transfer learning.