 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment-Level Attribution for Selective Learning of Long Reasoning Traces
Jan 31, 2026Large Reasoning Models (LRMs) achieve strong reasoning performance by generating long chains of thought (CoTs), yet only a small fraction of these traces meaningfully contributes to answer prediction, while the majority contains repetitive or truncated content. Such output redundancy is further propagated after supervised finetuning (SFT), as models learn to imitate verbose but uninformative patterns, which can degrade performance. To this end, we incorporate integrated gradient attribution to quantify each token's influence on final answers and aggregate them into two segment-level metrics: (1) \textit{attribution strength} measures the overall attribution magnitude; and (2) \textit{direction consistency} captures whether tokens' attributions within a segment are uniformly positive or negative (high consistency), or a mixture of both (moderate consistency). Based on these two metrics, we propose a segment-level selective learning framework to identify important segments with high attribution strength but moderate consistency that indicate reflective rather than shallow reasoning. The framework then applies selective SFT on these important segments while masking loss for unimportant ones. Experiments across multiple models and datasets show that our approach improves accuracy and output efficiency, enabling more effective learning from long reasoning traces~\footnote{Code and data are available at https://github.com/SiyuanWangw/SegmentSelectiveSFT}.
HPCTransCompile: An AI Compiler Generated Dataset for High-Performance CUDA Transpilation and LLM Preliminary Exploration
Jun 12, 2025The rapid growth of deep learning has driven exponential increases in model parameters and computational demands. NVIDIA GPUs and their CUDA-based software ecosystem provide robust support for parallel computing, significantly alleviating computational bottlenecks. Meanwhile, due to the cultivation of user programming habits and the high performance of GPUs, the CUDA ecosystem has established a dominant position in the field of parallel software. This dominance requires other hardware platforms to support CUDA-based software with performance portability. However, translating CUDA code to other platforms poses significant challenges due to differences in parallel programming paradigms and hardware architectures. Existing approaches rely on language extensions, domain-specific languages (DSLs), or compilers but face limitations in workload coverage and generalizability. Moreover, these methods often incur substantial development costs. Recently, LLMs have demonstrated extraordinary potential in various vertical domains, especially in code-related tasks. However, the performance of existing LLMs in CUDA transpilation, particularly for high-performance code, remains suboptimal. The main reason for this limitation lies in the lack of high-quality training datasets. To address these challenges, we propose a novel framework for generating high-performance CUDA and corresponding platform code pairs, leveraging AI compiler and automatic optimization technology. We further enhance the framework with a graph-based data augmentation method and introduce HPCTransEval, a benchmark for evaluating LLM performance on CUDA transpilation. We conduct experiments using CUDA-to-CPU transpilation as a case study on leading LLMs. The result demonstrates that our framework significantly improves CUDA transpilation, highlighting the potential of LLMs to address compatibility challenges within the CUDA ecosystem.
MDHP-Net: Detecting Injection Attacks on In-vehicle Network using Multi-Dimensional Hawkes Process and Temporal Model
Nov 15, 2024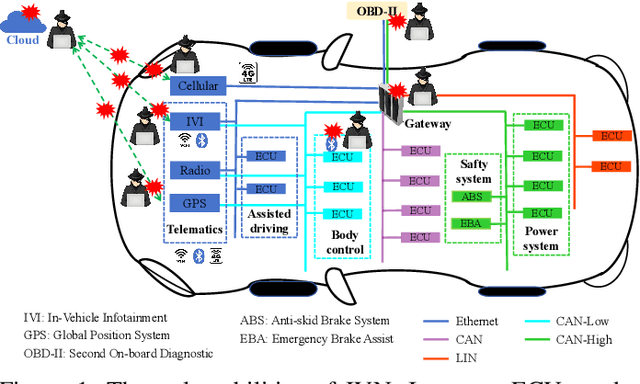

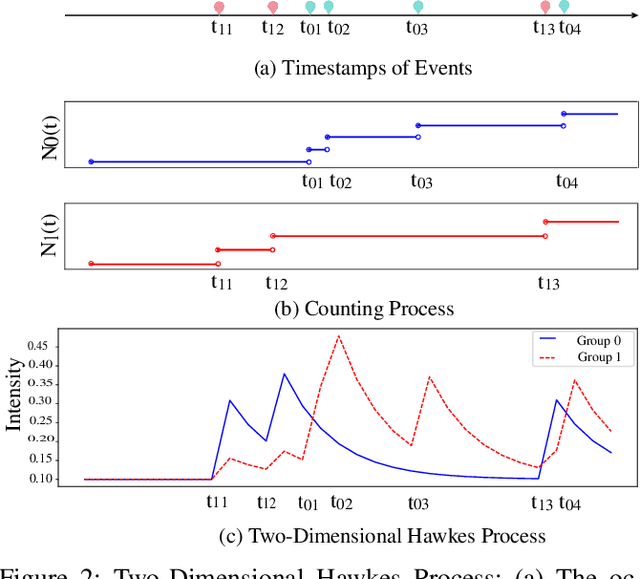
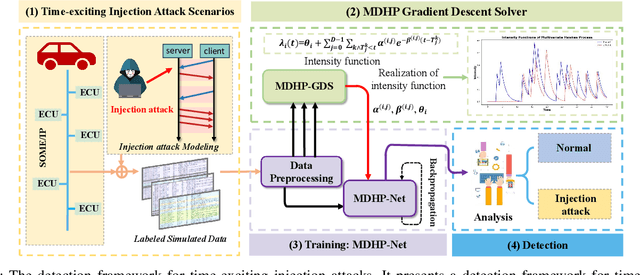
The integration of intelligent and connected technologies in modern vehicles, while offering enhanced functionalities through Electronic Control Unit and interfaces like OBD-II and telematics, also exposes the vehicle's in-vehicle network (IVN) to potential cyberattacks. In this paper, we consider a specific type of cyberattack known as the injection attack. As demonstrated by empirical data from real-world cybersecurity adversarial competitions(available at https://mimic2024.xctf.org.cn/race/qwmimic2024 ), these injection attacks have excitation effect over time, gradually manipulating network traffic and disrupting the vehicle's normal functioning, ultimately compromising both its stability and safety. To profile the abnormal behavior of attackers, we propose a novel injection attack detector to extract long-term features of attack behavior. Specifically, we first provide a theoretical analysis of modeling the time-excitation effects of the attack using Multi-Dimensional Hawkes Process (MDHP). A gradient descent solver specifically tailored for MDHP, MDHP-GDS, is developed to accurately estimate optimal MDHP parameters. We then propose an injection attack detector, MDHP-Net, which integrates optimal MDHP parameters with MDHP-LSTM blocks to enhance temporal feature extraction. By introducing MDHP parameters, MDHP-Net captures complex temporal features that standard Long Short-Term Memory (LSTM) cannot, enriching temporal dependencies within our customized structure. Extensive evaluations demonstrate the effectiveness of our proposed detection approach.
PrivacyLens: Evaluating Privacy Norm Awareness of Language Models in Action
Aug 29, 2024



As language models (LMs) are widely utilized in personalized communication scenarios (e.g., sending emails, writing social media posts) and endowed with a certain level of agency, ensuring they act in accordance with the contextual privacy norms becomes increasingly critical. However, quantifying the privacy norm awareness of LMs and the emerging privacy risk in LM-mediated communication is challenging due to (1) the contextual and long-tailed nature of privacy-sensitive cases, and (2) the lack of evaluation approaches that capture realistic application scenarios. To address these challenges, we propose PrivacyLens, a novel framework designed to extend privacy-sensitive seeds into expressive vignettes and further into agent trajectories, enabling multi-level evaluation of privacy leakage in LM agents' actions. We instantiate PrivacyLens with a collection of privacy norms grounded in privacy literature and crowdsourced seeds. Using this dataset, we reveal a discrepancy between LM performance in answering probing questions and their actual behavior when executing user instructions in an agent setup. State-of-the-art LMs, like GPT-4 and Llama-3-70B, leak sensitive information in 25.68% and 38.69% of cases, even when prompted with privacy-enhancing instructions. We also demonstrate the dynamic nature of PrivacyLens by extending each seed into multiple trajectories to red-team LM privacy leakage risk. Dataset and code are available at https://github.com/SALT-NLP/PrivacyLens.
AIRA: A Low-cost IR-based Approach Towards Autonomous Precision Drone Landing and NLOS Indoor Navigation
Jul 08, 2024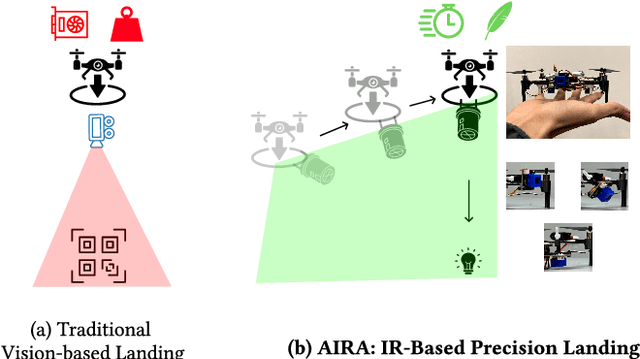
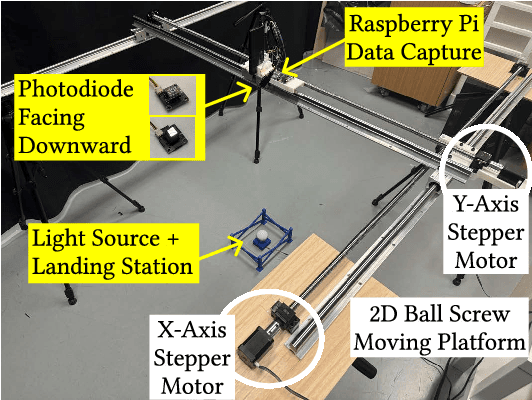
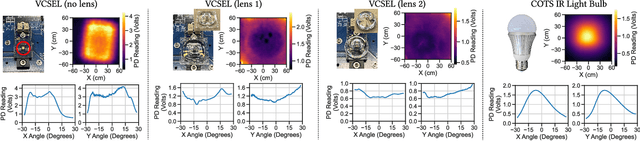
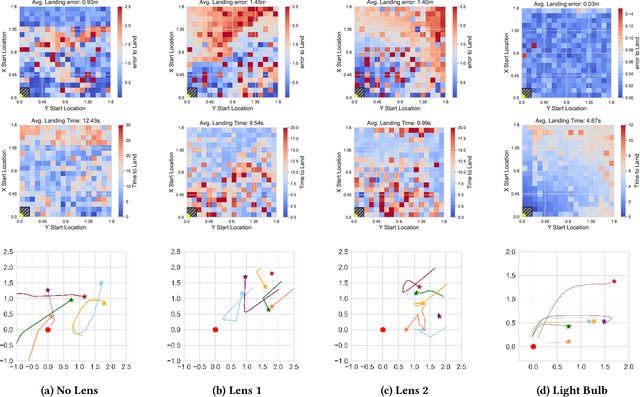
Automatic drone landing is an important step for achieving fully autonomous drones. Although there are many works that leverage GPS, video, wireless signals, and active acoustic sensing to perform precise landing, autonomous drone landing remains an unsolved challenge for palm-sized microdrones that may not be able to support the high computational requirements of vision, wireless, or active audio sensing. We propose AIRA, a low-cost infrared light-based platform that targets precise and efficient landing of low-resource microdrones. AIRA consists of an infrared light bulb at the landing station along with an energy efficient hardware photodiode (PD) sensing platform at the bottom of the drone. AIRA costs under 83 USD, while achieving comparable performance to existing vision-based methods at a fraction of the energy cost. AIRA requires only three PDs without any complex pattern recognition models to accurately land the drone, under $10$cm of error, from up to $11.1$ meters away, compared to camera-based methods that require recognizing complex markers using high resolution images with a range of only up to $1.2$ meters from the same height. Moreover, we demonstrate that AIRA can accurately guide drones in low light and partial non line of sight scenarios, which are difficult for traditional vision-based approaches.
StyleShot: A Snapshot on Any Style
Jul 01, 2024In this paper, we show that, a good style representation is crucial and sufficient for generalized style transfer without test-time tuning. We achieve this through constructing a style-aware encoder and a well-organized style dataset called StyleGallery. With dedicated design for style learning, this style-aware encoder is trained to extract expressive style representation with decoupling training strategy, and StyleGallery enables the generalization ability. We further employ a content-fusion encoder to enhance image-driven style transfer. We highlight that, our approach, named StyleShot, is simple yet effective in mimicking various desired styles, i.e., 3D, flat, abstract or even fine-grained styles, without test-time tuning. Rigorous experiments validate that, StyleShot achieves superior performance across a wide range of styles compared to existing state-of-the-art methods. The project page is available at: https://styleshot.github.io/.
AnyControl: Create Your Artwork with Versatile Control on Text-to-Image Generation
Jun 27, 2024The field of text-to-image (T2I) generation has made significant progress in recent years, largely driven by advancements in diffusion models. Linguistic control enables effective content creation, but struggles with fine-grained control over image generation. This challenge has been explored, to a great extent, by incorporating additional user-supplied spatial conditions, such as depth maps and edge maps, into pre-trained T2I models through extra encoding. However, multi-control image synthesis still faces several challenges. Specifically, current approaches are limited in handling free combinations of diverse input control signals, overlook the complex relationships among multiple spatial conditions, and often fail to maintain semantic alignment with provided textual prompts. This can lead to suboptimal user experiences. To address these challenges, we propose AnyControl, a multi-control image synthesis framework that supports arbitrary combinations of diverse control signals. AnyControl develops a novel Multi-Control Encoder that extracts a unified multi-modal embedding to guide the generation process. This approach enables a holistic understanding of user inputs, and produces high-quality, faithful results under versatile control signals, as demonstrated by extensive quantitative and qualitative evaluations. Our project page is available in \url{https://any-control.github.io}.
RASP: A Drone-based Reconfigurable Actuation and Sensing Platform Towards Ambient Intelligent Systems
Mar 19, 2024Realizing consumer-grade drones that are as useful as robot vacuums throughout our homes or personal smartphones in our daily lives requires drones to sense, actuate, and respond to general scenarios that may arise. Towards this vision, we propose RASP, a modular and reconfigurable sensing and actuation platform that allows drones to autonomously swap onboard sensors and actuators in only 25 seconds, allowing a single drone to quickly adapt to a diverse range of tasks. RASP consists of a mechanical layer to physically swap sensor modules, an electrical layer to maintain power and communication lines to the sensor/actuator, and a software layer to maintain a common interface between the drone and any sensor module in our platform. Leveraging recent advances in large language and visual language models, we further introduce the architecture, implementation, and real-world deployments of a personal assistant system utilizing RASP. We demonstrate that RASP can enable a diverse range of useful tasks in home, office, lab, and other indoor settings.
SISSA: Real-time Monitoring of Hardware Functional Safety and Cybersecurity with In-vehicle SOME/IP Ethernet Traffic
Feb 21, 2024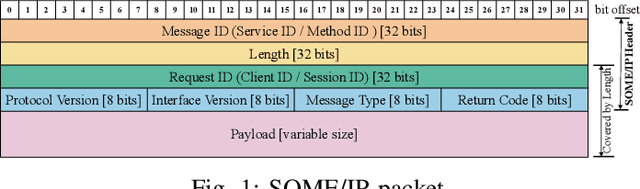
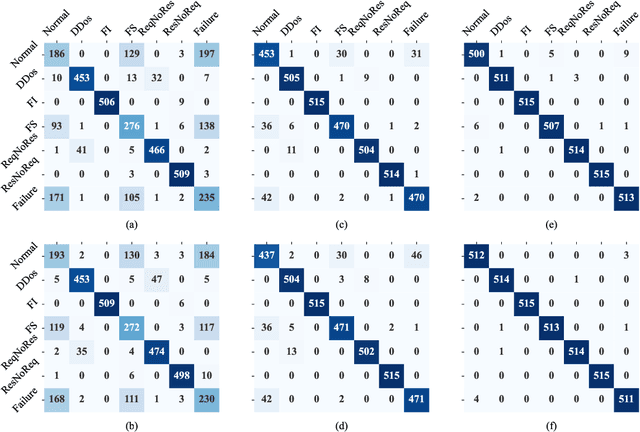
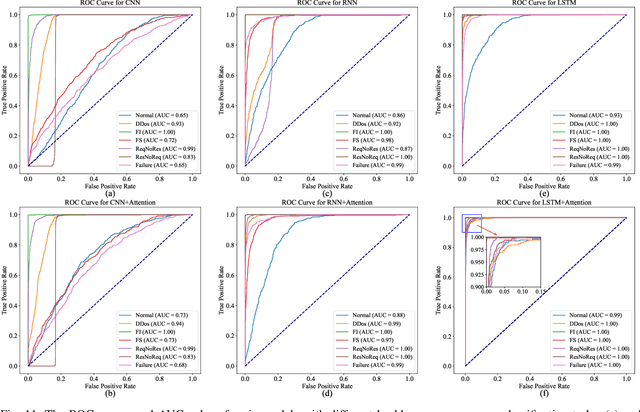
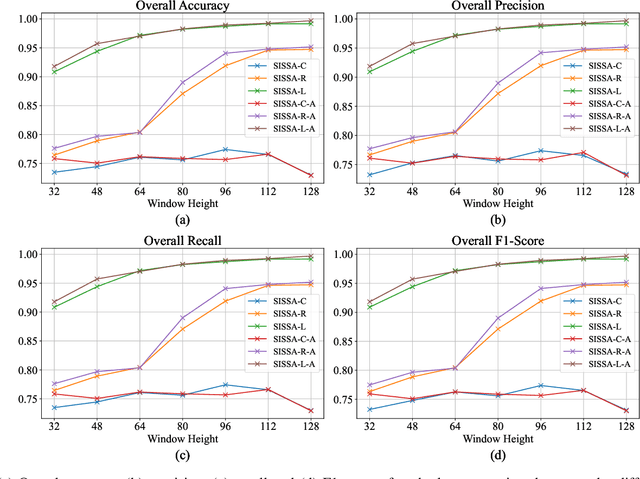
Scalable service-Oriented Middleware over IP (SOME/IP) is an Ethernet communication standard protocol in the Automotive Open System Architecture (AUTOSAR), promoting ECU-to-ECU communication over the IP stack. However, SOME/IP lacks a robust security architecture, making it susceptible to potential attacks. Besides, random hardware failure of ECU will disrupt SOME/IP communication. In this paper, we propose SISSA, a SOME/IP communication traffic-based approach for modeling and analyzing in-vehicle functional safety and cyber security. Specifically, SISSA models hardware failures with the Weibull distribution and addresses five potential attacks on SOME/IP communication, including Distributed Denial-of-Services, Man-in-the-Middle, and abnormal communication processes, assuming a malicious user accesses the in-vehicle network. Subsequently, SISSA designs a series of deep learning models with various backbones to extract features from SOME/IP sessions among ECUs. We adopt residual self-attention to accelerate the model's convergence and enhance detection accuracy, determining whether an ECU is under attack, facing functional failure, or operating normally. Additionally, we have created and annotated a dataset encompassing various classes, including indicators of attack, functionality, and normalcy. This contribution is noteworthy due to the scarcity of publicly accessible datasets with such characteristics.Extensive experimental results show the effectiveness and efficiency of SISSA.
From Scroll to Misbelief: Modeling the Unobservable Susceptibility to Misinformation on Social Media
Nov 16, 2023Susceptibility to misinformation describes the extent to believe unverifiable claims, which is hidden in people's mental process and infeasible to observe. Existing susceptibility studies heavily rely on the self-reported beliefs, making any downstream applications on susceptability hard to scale. To address these limitations, in this work, we propose a computational model to infer users' susceptibility levels given their activities. Since user's susceptibility is a key indicator for their reposting behavior, we utilize the supervision from the observable sharing behavior to infer the underlying susceptibility tendency. The evaluation shows that our model yields estimations that are highly aligned with human judgment on users' susceptibility level comparisons. Building upon such large-scale susceptibility labeling, we further conduct a comprehensive analysis of how different social factors relate to susceptibility. We find that political leanings and psychological factors are associated with susceptibility in varying degrees.