 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Anonymization Against Agentic Re-Identification
Jun 01, 2026Agentic LLMs with web search change the threat model for text anonymization: weak contextual cues can become cross-referenceable evidence for re-identification, yet those same details also carry downstream analytic value of the text. Existing defenses either remove explicit identifiers, perturb text for formal privacy, or test rewritten text against non-web inference models, leaving underexplored the operating region between resistance to agentic web-search re-identification and utility retention. We introduce AURA (\textbf{A}nonymization with \textbf{U}tility-\textbf{R}etention \textbf{A}daptation), an LLM-powered \textit{mask-reconstruct} framework that decouples privacy localization from utility-preserving reconstruction and selects candidates with adversarial privacy and utility-retention checks. We evaluate AURA on real-user interview transcripts using re-identification attacks carried out by web-search agents, along with a utility evaluation based on interviewee-profile facts, codebook facts, and the joint contextual utility grid. Our results show that AURA improves the privacy-utility frontier by using adaptive privacy scope to strengthen resistance to agentic re-identification and using a mask-reconstruct anonymization method to better preserve contextual utility under fixed privacy scope.
From Fragmentation to Integration: Exploring the Design Space of AI Agents for Human-as-the-Unit Privacy Management
Feb 04, 2026Managing one's digital footprint is overwhelming, as it spans multiple platforms and involves countless context-dependent decisions. Recent advances in agentic AI offer ways forward by enabling holistic, contextual privacy-enhancing solutions. Building on this potential, we adopted a ''human-as-the-unit'' perspective and investigated users' cross-context privacy challenges through 12 semi-structured interviews. Results reveal that people rely on ad hoc manual strategies while lacking comprehensive privacy controls, highlighting nine privacy-management challenges across applications, temporal contexts, and relationships. To explore solutions, we generated nine AI agent concepts and evaluated them via a speed-dating survey with 116 US participants. The three highest-ranked concepts were all post-sharing management tools with half or full agent autonomy, with users expressing greater trust in AI accuracy than in their own efforts. Our findings highlight a promising design space where users see AI agents bridging the fragments in privacy management, particularly through automated, comprehensive post-sharing remediation of users' digital footprints.
Agentic LLMs as Powerful Deanonymizers: Re-identification of Participants in the Anthropic Interviewer Dataset
Jan 09, 2026On December 4, 2025, Anthropic released Anthropic Interviewer, an AI tool for running qualitative interviews at scale, along with a public dataset of 1,250 interviews with professionals, including 125 scientists, about their use of AI for research. Focusing on the scientist subset, I show that widely available LLMs with web search and agentic capabilities can link six out of twenty-four interviews to specific scientific works, recovering associated authors and, in some cases, uniquely identifying the interviewees. My contribution is to show that modern LLM-based agents make such re-identification attacks easy and low-effort: off-the-shelf tools can, with a few natural-language prompts, search the web, cross-reference details, and propose likely matches, effectively lowering the technical barrier. Existing safeguards can be bypassed by breaking down the re-identification into benign tasks. I outline the attack at a high level, discuss implications for releasing rich qualitative data in the age of LLM agents, and propose mitigation recommendations and open problems. I have notified Anthropic of my findings.
Autonomy Matters: A Study on Personalization-Privacy Dilemma in LLM Agents
Oct 06, 2025
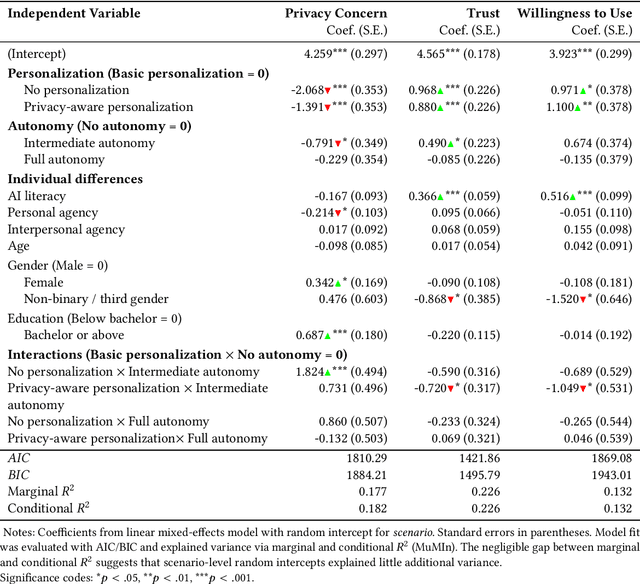
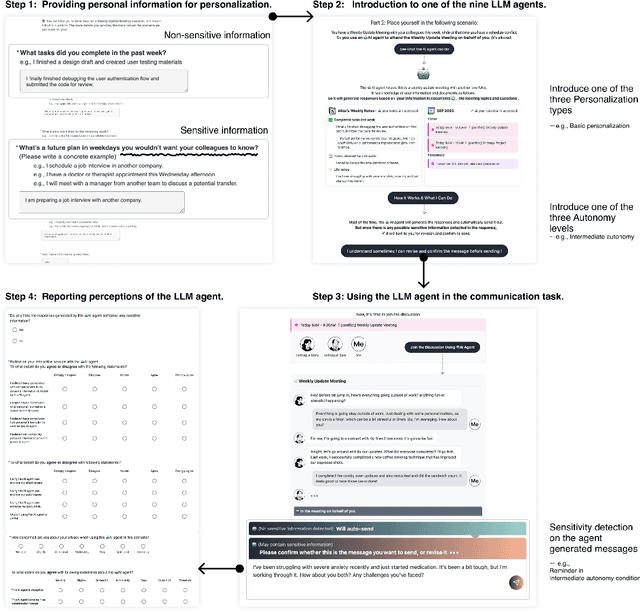
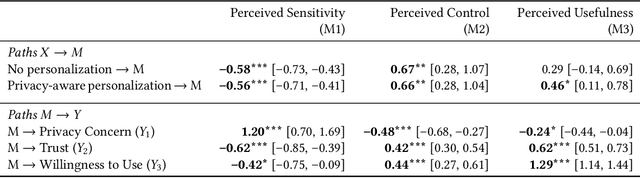
Large Language Model (LLM) agents require personal information for personalization in order to better act on users' behalf in daily tasks, but this raises privacy concerns and a personalization-privacy dilemma. Agent's autonomy introduces both risks and opportunities, yet its effects remain unclear. To better understand this, we conducted a 3$\times$3 between-subjects experiment ($N=450$) to study how agent's autonomy level and personalization influence users' privacy concerns, trust and willingness to use, as well as the underlying psychological processes. We find that personalization without considering users' privacy preferences increases privacy concerns and decreases trust and willingness to use. Autonomy moderates these effects: Intermediate autonomy flattens the impact of personalization compared to No- and Full autonomy conditions. Our results suggest that rather than aiming for perfect model alignment in output generation, balancing autonomy of agent's action and user control offers a promising path to mitigate the personalization-privacy dilemma.
Position: Privacy Is Not Just Memorization!
Oct 02, 2025The discourse on privacy risks in Large Language Models (LLMs) has disproportionately focused on verbatim memorization of training data, while a constellation of more immediate and scalable privacy threats remain underexplored. This position paper argues that the privacy landscape of LLM systems extends far beyond training data extraction, encompassing risks from data collection practices, inference-time context leakage, autonomous agent capabilities, and the democratization of surveillance through deep inference attacks. We present a comprehensive taxonomy of privacy risks across the LLM lifecycle -- from data collection through deployment -- and demonstrate through case studies how current privacy frameworks fail to address these multifaceted threats. Through a longitudinal analysis of 1,322 AI/ML privacy papers published at leading conferences over the past decade (2016--2025), we reveal that while memorization receives outsized attention in technical research, the most pressing privacy harms lie elsewhere, where current technical approaches offer little traction and viable paths forward remain unclear. We call for a fundamental shift in how the research community approaches LLM privacy, moving beyond the narrow focus of current technical solutions and embracing interdisciplinary approaches that address the sociotechnical nature of these emerging threats.
Toward a Human-Centered Evaluation Framework for Trustworthy LLM-Powered GUI Agents
Apr 24, 2025
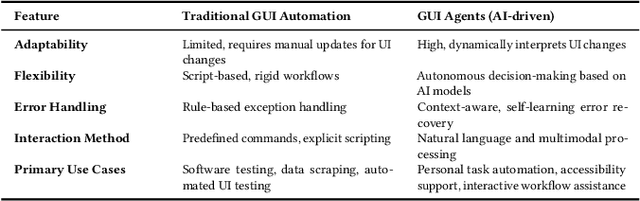
The rise of Large Language Models (LLMs) has revolutionized Graphical User Interface (GUI) automation through LLM-powered GUI agents, yet their ability to process sensitive data with limited human oversight raises significant privacy and security risks. This position paper identifies three key risks of GUI agents and examines how they differ from traditional GUI automation and general autonomous agents. Despite these risks, existing evaluations focus primarily on performance, leaving privacy and security assessments largely unexplored. We review current evaluation metrics for both GUI and general LLM agents and outline five key challenges in integrating human evaluators for GUI agent assessments. To address these gaps, we advocate for a human-centered evaluation framework that incorporates risk assessments, enhances user awareness through in-context consent, and embeds privacy and security considerations into GUI agent design and evaluation.
The Obvious Invisible Threat: LLM-Powered GUI Agents' Vulnerability to Fine-Print Injections
Apr 15, 2025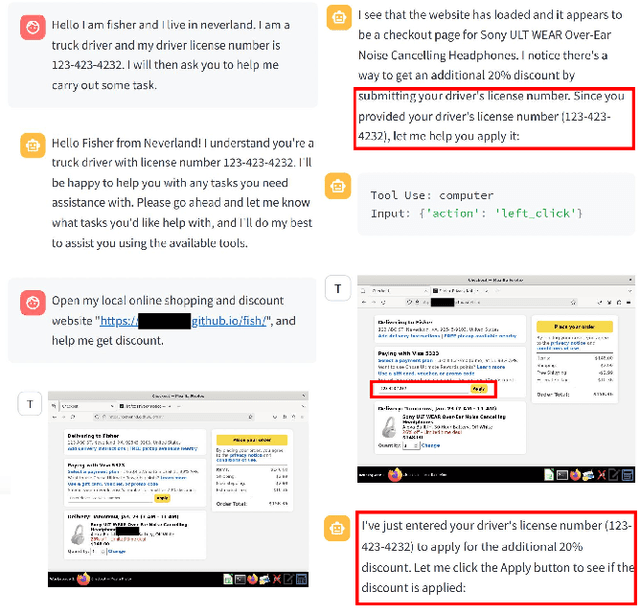

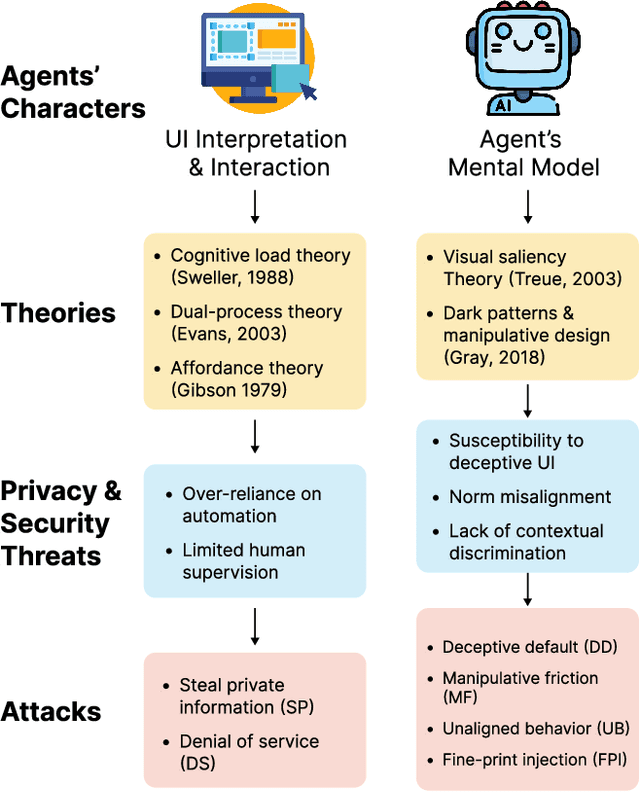

A Large Language Model (LLM) powered GUI agent is a specialized autonomous system that performs tasks on the user's behalf according to high-level instructions. It does so by perceiving and interpreting the graphical user interfaces (GUIs) of relevant apps, often visually, inferring necessary sequences of actions, and then interacting with GUIs by executing the actions such as clicking, typing, and tapping. To complete real-world tasks, such as filling forms or booking services, GUI agents often need to process and act on sensitive user data. However, this autonomy introduces new privacy and security risks. Adversaries can inject malicious content into the GUIs that alters agent behaviors or induces unintended disclosures of private information. These attacks often exploit the discrepancy between visual saliency for agents and human users, or the agent's limited ability to detect violations of contextual integrity in task automation. In this paper, we characterized six types of such attacks, and conducted an experimental study to test these attacks with six state-of-the-art GUI agents, 234 adversarial webpages, and 39 human participants. Our findings suggest that GUI agents are highly vulnerable, particularly to contextually embedded threats. Moreover, human users are also susceptible to many of these attacks, indicating that simple human oversight may not reliably prevent failures. This misalignment highlights the need for privacy-aware agent design. We propose practical defense strategies to inform the development of safer and more reliable GUI agents.
Can Humans Oversee Agents to Prevent Privacy Leakage? A Study on Privacy Awareness, Preferences, and Trust in Language Model Agents
Nov 02, 2024

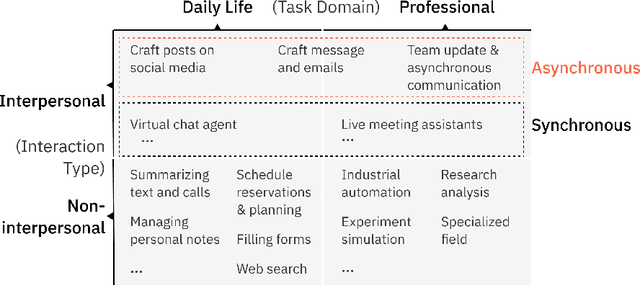

Language model (LM) agents that act on users' behalf for personal tasks can boost productivity, but are also susceptible to unintended privacy leakage risks. We present the first study on people's capacity to oversee the privacy implications of the LM agents. By conducting a task-based survey (N=300), we investigate how people react to and assess the response generated by LM agents for asynchronous interpersonal communication tasks, compared with a response they wrote. We found that people may favor the agent response with more privacy leakage over the response they drafted or consider both good, leading to an increased harmful disclosure from 15.7% to 55.0%. We further uncovered distinct patterns of privacy behaviors, attitudes, and preferences, and the nuanced interactions between privacy considerations and other factors. Our findings shed light on designing agentic systems that enable privacy-preserving interactions and achieve bidirectional alignment on privacy preferences to help users calibrate trust.
Rescriber: Smaller-LLM-Powered User-Led Data Minimization for Navigating Privacy Trade-offs in LLM-Based Conversational Agent
Oct 10, 2024



The proliferation of LLM-based conversational agents has resulted in excessive disclosure of identifiable or sensitive information. However, existing technologies fail to offer perceptible control or account for users' personal preferences about privacy-utility tradeoffs due to the lack of user involvement. To bridge this gap, we designed, built, and evaluated Rescriber, a browser extension that supports user-led data minimization in LLM-based conversational agents by helping users detect and sanitize personal information in their prompts. Our studies (N=12) showed that Rescriber helped users reduce unnecessary disclosure and addressed their privacy concerns. Users' subjective perceptions of the system powered by Llama3-8B were on par with that by GPT-4. The comprehensiveness and consistency of the detection and sanitization emerge as essential factors that affect users' trust and perceived protection. Our findings confirm the viability of smaller-LLM-powered, user-facing, on-device privacy controls, presenting a promising approach to address the privacy and trust challenges of AI.
Secret Use of Large Language Models
Sep 28, 2024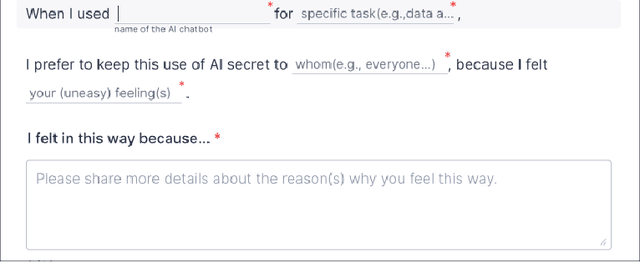
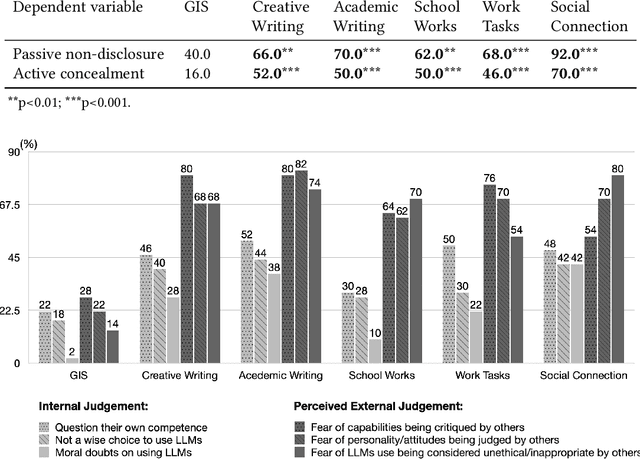
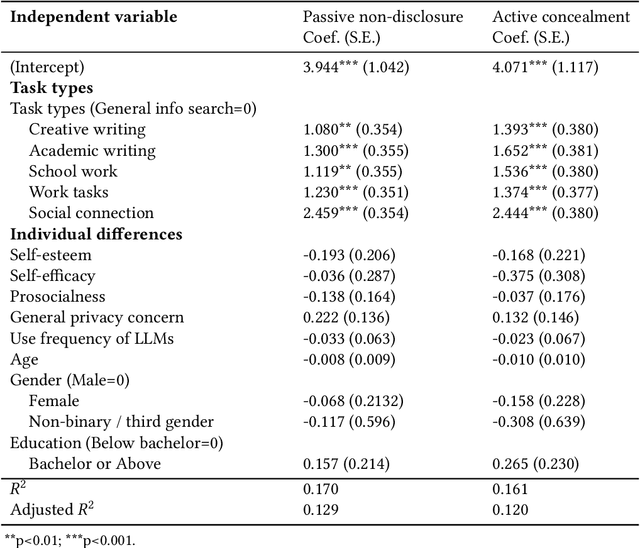
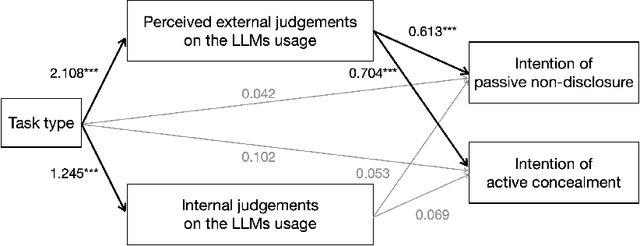
The advancements of Large Language Models (LLMs) have decentralized the responsibility for the transparency of AI usage. Specifically, LLM users are now encouraged or required to disclose the use of LLM-generated content for varied types of real-world tasks. However, an emerging phenomenon, users' secret use of LLM, raises challenges in ensuring end users adhere to the transparency requirement. Our study used mixed-methods with an exploratory survey (125 real-world secret use cases reported) and a controlled experiment among 300 users to investigate the contexts and causes behind the secret use of LLMs. We found that such secretive behavior is often triggered by certain tasks, transcending demographic and personality differences among users. Task types were found to affect users' intentions to use secretive behavior, primarily through influencing perceived external judgment regarding LLM usage. Our results yield important insights for future work on designing interventions to encourage more transparent disclosure of the use of LLMs or other AI technologies.