Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Word Sense Embeddings from Word Sense Definitions
Paper and Code
Oct 24, 2016


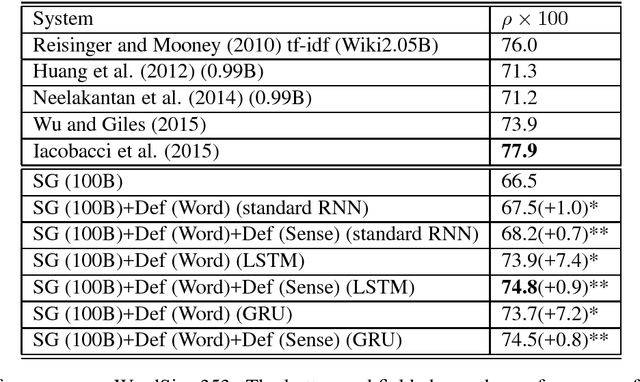
Word embeddings play a significant role in many modern NLP systems. Since learning one representation per word is problematic for polysemous words and homonymous words, researchers propose to use one embedding per word sense. Their approaches mainly train word sense embeddings on a corpus. In this paper, we propose to use word sense definitions to learn one embedding per word sense. Experimental results on word similarity tasks and a word sense disambiguation task show that word sense embeddings produced by our approach are of high quality.
* To appear at NLPCC-ICCPOL 2016
View paper on