 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Humans Oversee Agents to Prevent Privacy Leakage? A Study on Privacy Awareness, Preferences, and Trust in Language Model Agents
Paper and Code
Nov 02, 2024

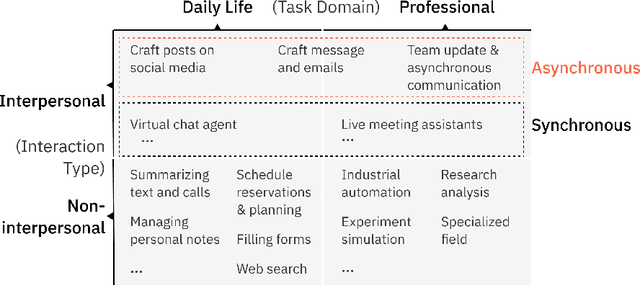

Language model (LM) agents that act on users' behalf for personal tasks can boost productivity, but are also susceptible to unintended privacy leakage risks. We present the first study on people's capacity to oversee the privacy implications of the LM agents. By conducting a task-based survey (N=300), we investigate how people react to and assess the response generated by LM agents for asynchronous interpersonal communication tasks, compared with a response they wrote. We found that people may favor the agent response with more privacy leakage over the response they drafted or consider both good, leading to an increased harmful disclosure from 15.7% to 55.0%. We further uncovered distinct patterns of privacy behaviors, attitudes, and preferences, and the nuanced interactions between privacy considerations and other factors. Our findings shed light on designing agentic systems that enable privacy-preserving interactions and achieve bidirectional alignment on privacy preferences to help users calibrate trust.