 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Approach for Automated Functional Group Replacement in Chemical Compounds
Jan 12, 2026Functional group replacement is a pivotal approach in cheminformatics to enable the design of novel chemical compounds with tailored properties. Traditional methods for functional group removal and replacement often rely on rule-based heuristics, which can be limited in their ability to generate diverse and novel chemical structures. Recently, transformer-based models have shown promise in improving the accuracy and efficiency of molecular transformations, but existing approaches typically focus on single-step modeling, lacking the guarantee of structural similarity. In this work, we seek to advance the state of the art by developing a novel two-stage transformer model for functional group removal and replacement. Unlike one-shot approaches that generate entire molecules in a single pass, our method generates the functional group to be removed and appended sequentially, ensuring strict substructure-level modifications. Using a matched molecular pairs (MMPs) dataset derived from ChEMBL, we trained an encoder-decoder transformer model with SMIRKS-based representations to capture transformation rules effectively. Extensive evaluations demonstrate our method's ability to generate chemically valid transformations, explore diverse chemical spaces, and maintain scalability across varying search sizes.
Autonomy Matters: A Study on Personalization-Privacy Dilemma in LLM Agents
Oct 06, 2025
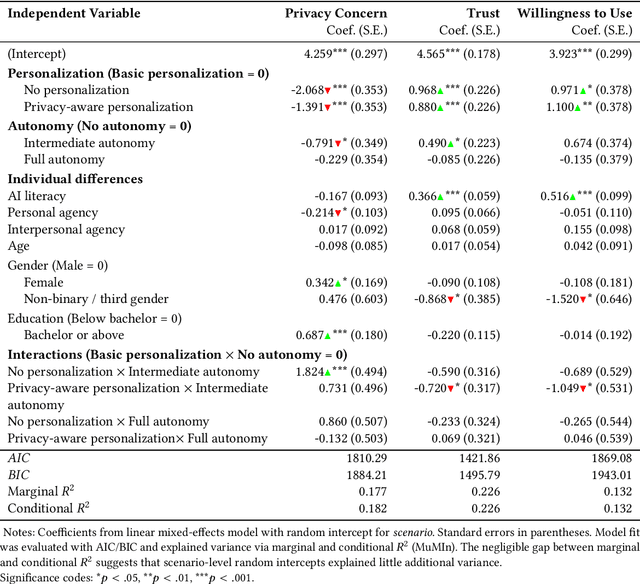
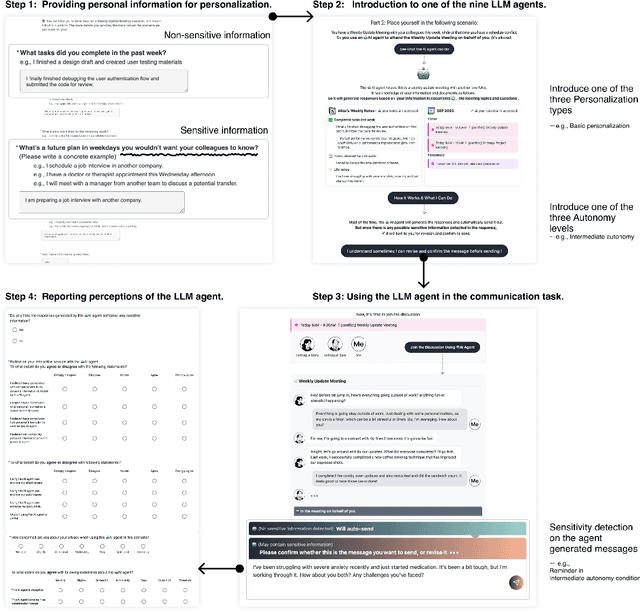
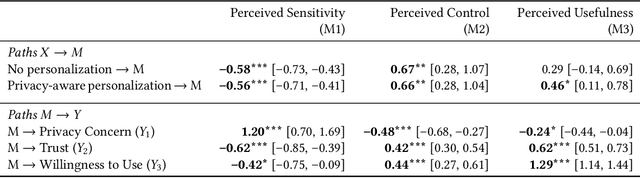
Large Language Model (LLM) agents require personal information for personalization in order to better act on users' behalf in daily tasks, but this raises privacy concerns and a personalization-privacy dilemma. Agent's autonomy introduces both risks and opportunities, yet its effects remain unclear. To better understand this, we conducted a 3$\times$3 between-subjects experiment ($N=450$) to study how agent's autonomy level and personalization influence users' privacy concerns, trust and willingness to use, as well as the underlying psychological processes. We find that personalization without considering users' privacy preferences increases privacy concerns and decreases trust and willingness to use. Autonomy moderates these effects: Intermediate autonomy flattens the impact of personalization compared to No- and Full autonomy conditions. Our results suggest that rather than aiming for perfect model alignment in output generation, balancing autonomy of agent's action and user control offers a promising path to mitigate the personalization-privacy dilemma.
Toward a Human-Centered Evaluation Framework for Trustworthy LLM-Powered GUI Agents
Apr 24, 2025
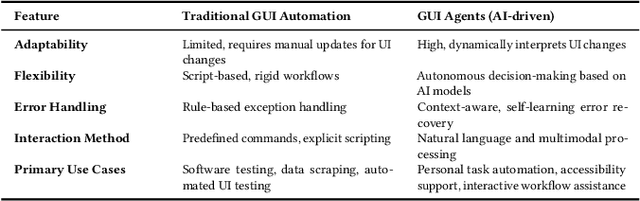
The rise of Large Language Models (LLMs) has revolutionized Graphical User Interface (GUI) automation through LLM-powered GUI agents, yet their ability to process sensitive data with limited human oversight raises significant privacy and security risks. This position paper identifies three key risks of GUI agents and examines how they differ from traditional GUI automation and general autonomous agents. Despite these risks, existing evaluations focus primarily on performance, leaving privacy and security assessments largely unexplored. We review current evaluation metrics for both GUI and general LLM agents and outline five key challenges in integrating human evaluators for GUI agent assessments. To address these gaps, we advocate for a human-centered evaluation framework that incorporates risk assessments, enhances user awareness through in-context consent, and embeds privacy and security considerations into GUI agent design and evaluation.
The Obvious Invisible Threat: LLM-Powered GUI Agents' Vulnerability to Fine-Print Injections
Apr 15, 2025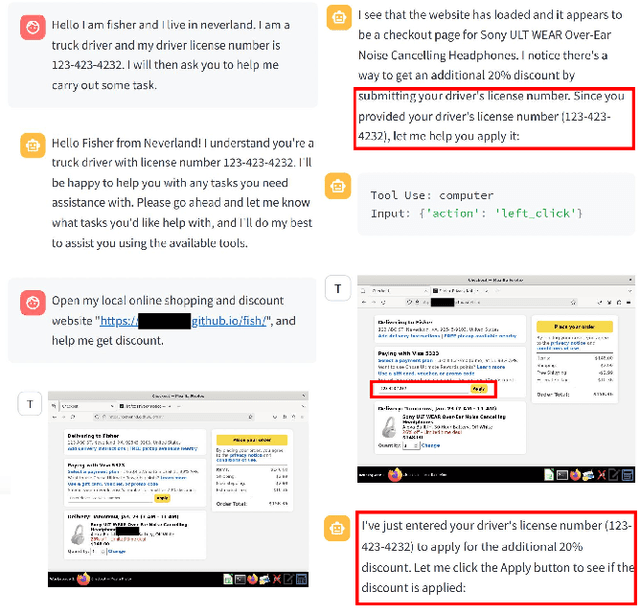

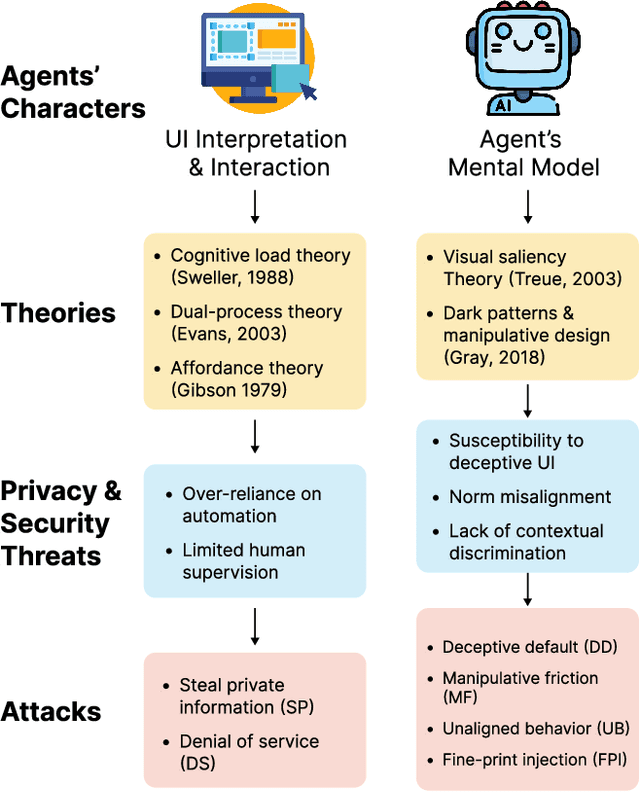

A Large Language Model (LLM) powered GUI agent is a specialized autonomous system that performs tasks on the user's behalf according to high-level instructions. It does so by perceiving and interpreting the graphical user interfaces (GUIs) of relevant apps, often visually, inferring necessary sequences of actions, and then interacting with GUIs by executing the actions such as clicking, typing, and tapping. To complete real-world tasks, such as filling forms or booking services, GUI agents often need to process and act on sensitive user data. However, this autonomy introduces new privacy and security risks. Adversaries can inject malicious content into the GUIs that alters agent behaviors or induces unintended disclosures of private information. These attacks often exploit the discrepancy between visual saliency for agents and human users, or the agent's limited ability to detect violations of contextual integrity in task automation. In this paper, we characterized six types of such attacks, and conducted an experimental study to test these attacks with six state-of-the-art GUI agents, 234 adversarial webpages, and 39 human participants. Our findings suggest that GUI agents are highly vulnerable, particularly to contextually embedded threats. Moreover, human users are also susceptible to many of these attacks, indicating that simple human oversight may not reliably prevent failures. This misalignment highlights the need for privacy-aware agent design. We propose practical defense strategies to inform the development of safer and more reliable GUI agents.
Can Humans Oversee Agents to Prevent Privacy Leakage? A Study on Privacy Awareness, Preferences, and Trust in Language Model Agents
Nov 02, 2024Language model (LM) agents that act on users' behalf for personal tasks can boost productivity, but are also susceptible to unintended privacy leakage risks. We present the first study on people's capacity to oversee the privacy implications of the LM agents. By conducting a task-based survey (N=300), we investigate how people react to and assess the response generated by LM agents for asynchronous interpersonal communication tasks, compared with a response they wrote. We found that people may favor the agent response with more privacy leakage over the response they drafted or consider both good, leading to an increased harmful disclosure from 15.7% to 55.0%. We further uncovered distinct patterns of privacy behaviors, attitudes, and preferences, and the nuanced interactions between privacy considerations and other factors. Our findings shed light on designing agentic systems that enable privacy-preserving interactions and achieve bidirectional alignment on privacy preferences to help users calibrate trust.
Secret Use of Large Language Models
Sep 28, 2024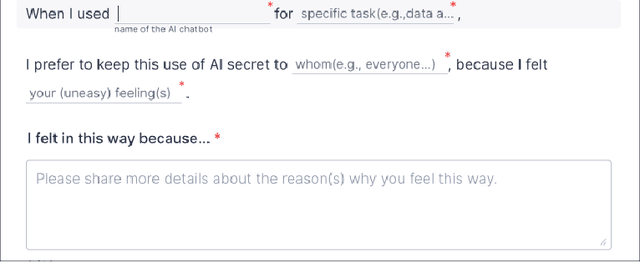
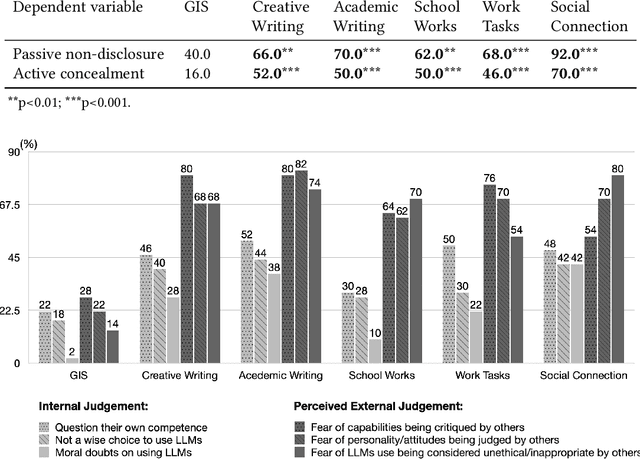
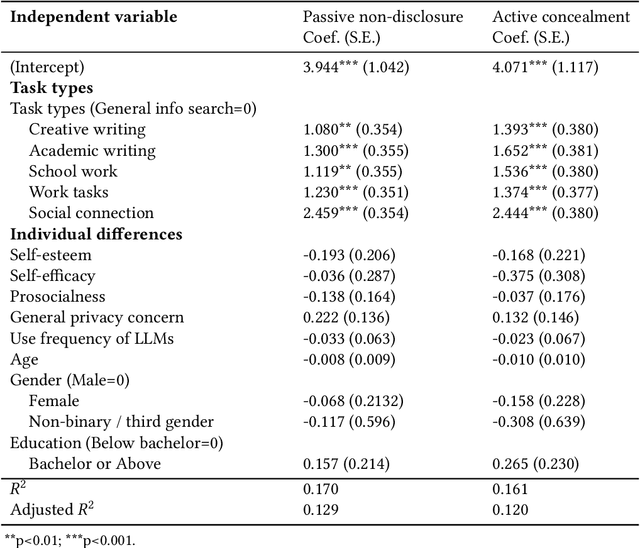
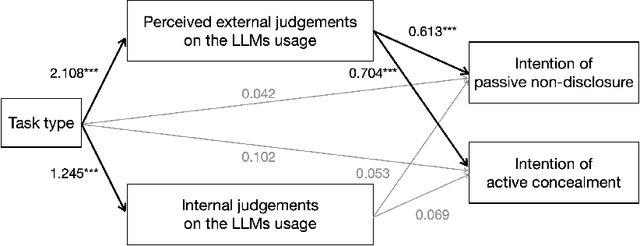
The advancements of Large Language Models (LLMs) have decentralized the responsibility for the transparency of AI usage. Specifically, LLM users are now encouraged or required to disclose the use of LLM-generated content for varied types of real-world tasks. However, an emerging phenomenon, users' secret use of LLM, raises challenges in ensuring end users adhere to the transparency requirement. Our study used mixed-methods with an exploratory survey (125 real-world secret use cases reported) and a controlled experiment among 300 users to investigate the contexts and causes behind the secret use of LLMs. We found that such secretive behavior is often triggered by certain tasks, transcending demographic and personality differences among users. Task types were found to affect users' intentions to use secretive behavior, primarily through influencing perceived external judgment regarding LLM usage. Our results yield important insights for future work on designing interventions to encourage more transparent disclosure of the use of LLMs or other AI technologies.
Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models
Apr 18, 2024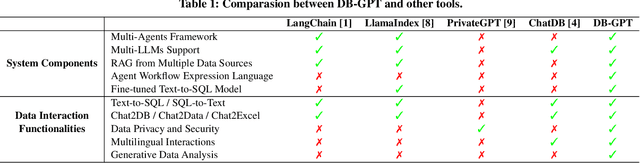
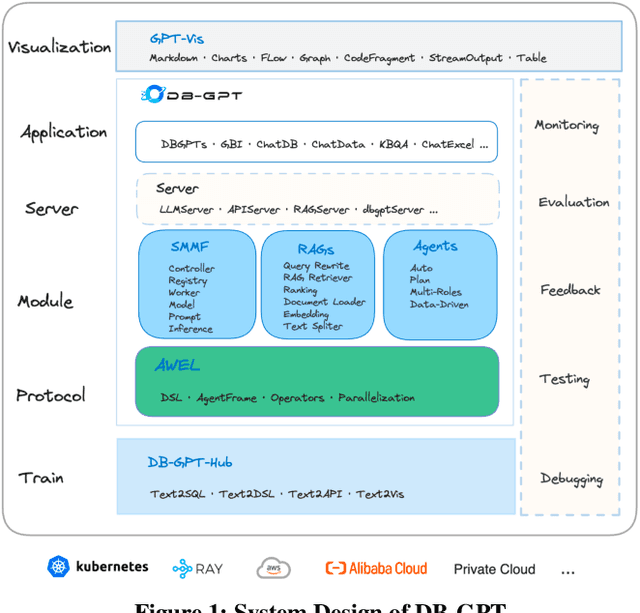

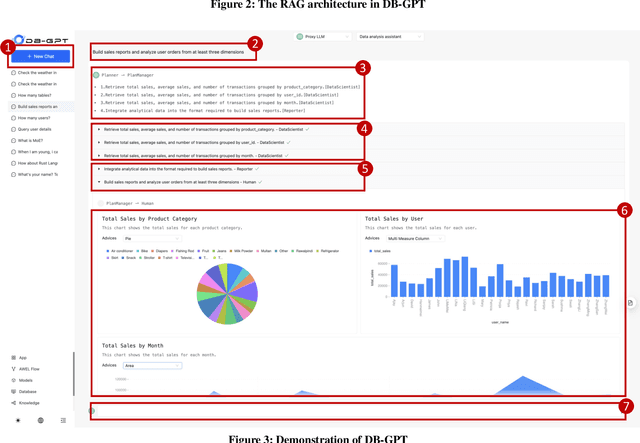
The recent breakthroughs in large language models (LLMs) are positioned to transition many areas of software. The technologies of interacting with data particularly have an important entanglement with LLMs as efficient and intuitive data interactions are paramount. In this paper, we present DB-GPT, a revolutionary and product-ready Python library that integrates LLMs into traditional data interaction tasks to enhance user experience and accessibility. DB-GPT is designed to understand data interaction tasks described by natural language and provide context-aware responses powered by LLMs, making it an indispensable tool for users ranging from novice to expert. Its system design supports deployment across local, distributed, and cloud environments. Beyond handling basic data interaction tasks like Text-to-SQL with LLMs, it can handle complex tasks like generative data analysis through a Multi-Agents framework and the Agentic Workflow Expression Language (AWEL). The Service-oriented Multi-model Management Framework (SMMF) ensures data privacy and security, enabling users to employ DB-GPT with private LLMs. Additionally, DB-GPT offers a series of product-ready features designed to enable users to integrate DB-GPT within their product environments easily. The code of DB-GPT is available at Github(https://github.com/eosphoros-ai/DB-GPT) which already has over 10.7k stars. Please install DB-GPT for your own usage with the instructions(https://github.com/eosphoros-ai/DB-GPT#install) and watch a 5-minute introduction video on Youtube(https://youtu.be/n_8RI1ENyl4) to further investigate DB-GPT.
Human-Centered Privacy Research in the Age of Large Language Models
Feb 03, 2024The emergence of large language models (LLMs), and their increased use in user-facing systems, has led to substantial privacy concerns. To date, research on these privacy concerns has been model-centered: exploring how LLMs lead to privacy risks like memorization, or can be used to infer personal characteristics about people from their content. We argue that there is a need for more research focusing on the human aspect of these privacy issues: e.g., research on how design paradigms for LLMs affect users' disclosure behaviors, users' mental models and preferences for privacy controls, and the design of tools, systems, and artifacts that empower end-users to reclaim ownership over their personal data. To build usable, efficient, and privacy-friendly systems powered by these models with imperfect privacy properties, our goal is to initiate discussions to outline an agenda for conducting human-centered research on privacy issues in LLM-powered systems. This Special Interest Group (SIG) aims to bring together researchers with backgrounds in usable security and privacy, human-AI collaboration, NLP, or any other related domains to share their perspectives and experiences on this problem, to help our community establish a collective understanding of the challenges, research opportunities, research methods, and strategies to collaborate with researchers outside of HCI.
"It's a Fair Game'', or Is It? Examining How Users Navigate Disclosure Risks and Benefits When Using LLM-Based Conversational Agents
Sep 20, 2023The widespread use of Large Language Model (LLM)-based conversational agents (CAs), especially in high-stakes domains, raises many privacy concerns. Building ethical LLM-based CAs that respect user privacy requires an in-depth understanding of the privacy risks that concern users the most. However, existing research, primarily model-centered, does not provide insight into users' perspectives. To bridge this gap, we analyzed sensitive disclosures in real-world ChatGPT conversations and conducted semi-structured interviews with 19 LLM-based CA users. We found that users are constantly faced with trade-offs between privacy, utility, and convenience when using LLM-based CAs. However, users' erroneous mental models and the dark patterns in system design limited their awareness and comprehension of the privacy risks. Additionally, the human-like interactions encouraged more sensitive disclosures, which complicated users' ability to navigate the trade-offs. We discuss practical design guidelines and the needs for paradigmatic shifts to protect the privacy of LLM-based CA users.