 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models
Apr 18, 2024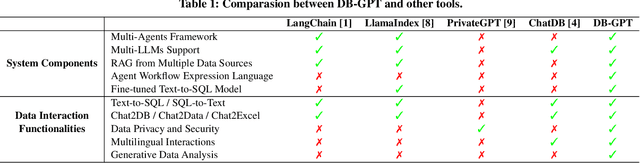
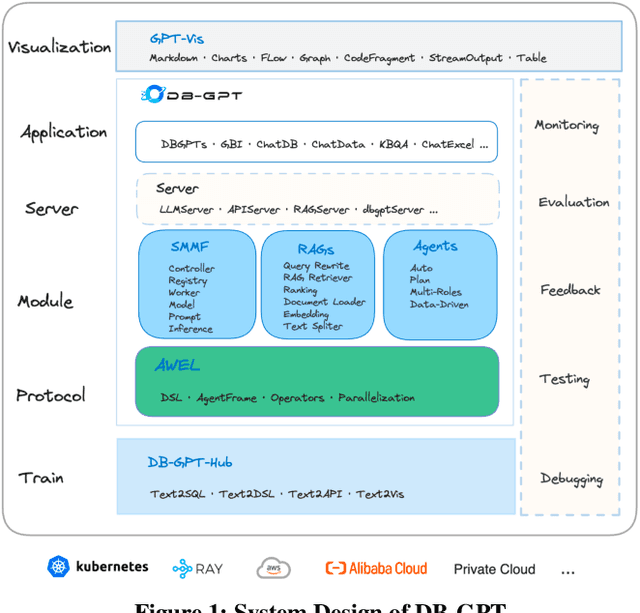

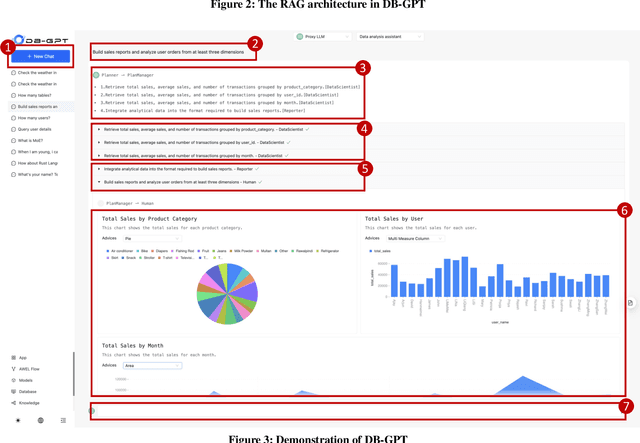
The recent breakthroughs in large language models (LLMs) are positioned to transition many areas of software. The technologies of interacting with data particularly have an important entanglement with LLMs as efficient and intuitive data interactions are paramount. In this paper, we present DB-GPT, a revolutionary and product-ready Python library that integrates LLMs into traditional data interaction tasks to enhance user experience and accessibility. DB-GPT is designed to understand data interaction tasks described by natural language and provide context-aware responses powered by LLMs, making it an indispensable tool for users ranging from novice to expert. Its system design supports deployment across local, distributed, and cloud environments. Beyond handling basic data interaction tasks like Text-to-SQL with LLMs, it can handle complex tasks like generative data analysis through a Multi-Agents framework and the Agentic Workflow Expression Language (AWEL). The Service-oriented Multi-model Management Framework (SMMF) ensures data privacy and security, enabling users to employ DB-GPT with private LLMs. Additionally, DB-GPT offers a series of product-ready features designed to enable users to integrate DB-GPT within their product environments easily. The code of DB-GPT is available at Github(https://github.com/eosphoros-ai/DB-GPT) which already has over 10.7k stars. Please install DB-GPT for your own usage with the instructions(https://github.com/eosphoros-ai/DB-GPT#install) and watch a 5-minute introduction video on Youtube(https://youtu.be/n_8RI1ENyl4) to further investigate DB-GPT.
LogicMP: A Neuro-symbolic Approach for Encoding First-order Logic Constraints
Sep 29, 2023Integrating first-order logic constraints (FOLCs) with neural networks is a crucial but challenging problem since it involves modeling intricate correlations to satisfy the constraints. This paper proposes a novel neural layer, LogicMP, whose layers perform mean-field variational inference over an MLN. It can be plugged into any off-the-shelf neural network to encode FOLCs while retaining modularity and efficiency. By exploiting the structure and symmetries in MLNs, we theoretically demonstrate that our well-designed, efficient mean-field iterations effectively mitigate the difficulty of MLN inference, reducing the inference from sequential calculation to a series of parallel tensor operations. Empirical results in three kinds of tasks over graphs, images, and text show that LogicMP outperforms advanced competitors in both performance and efficiency.
DRGCN: Dynamic Evolving Initial Residual for Deep Graph Convolutional Networks
Feb 10, 2023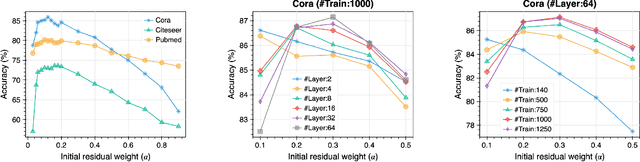



Graph convolutional networks (GCNs) have been proved to be very practical to handle various graph-related tasks. It has attracted considerable research interest to study deep GCNs, due to their potential superior performance compared with shallow ones. However, simply increasing network depth will, on the contrary, hurt the performance due to the over-smoothing problem. Adding residual connection is proved to be effective for learning deep convolutional neural networks (deep CNNs), it is not trivial when applied to deep GCNs. Recent works proposed an initial residual mechanism that did alleviate the over-smoothing problem in deep GCNs. However, according to our study, their algorithms are quite sensitive to different datasets. In their setting, the personalization (dynamic) and correlation (evolving) of how residual applies are ignored. To this end, we propose a novel model called Dynamic evolving initial Residual Graph Convolutional Network (DRGCN). Firstly, we use a dynamic block for each node to adaptively fetch information from the initial representation. Secondly, we use an evolving block to model the residual evolving pattern between layers. Our experimental results show that our model effectively relieves the problem of over-smoothing in deep GCNs and outperforms the state-of-the-art (SOTA) methods on various benchmark datasets. Moreover, we develop a mini-batch version of DRGCN which can be applied to large-scale data. Coupling with several fair training techniques, our model reaches new SOTA results on the large-scale ogbn-arxiv dataset of Open Graph Benchmark (OGB). Our reproducible code is available on GitHub.
PairRE: Knowledge Graph Embeddings via Paired Relation Vectors
Nov 07, 2020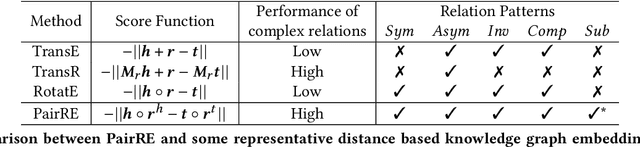
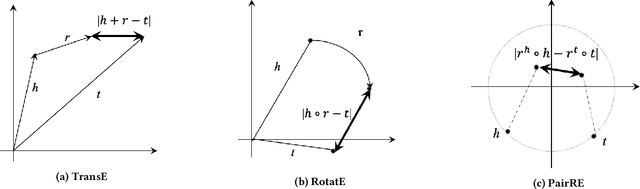

Distance based knowledge graph embedding methods show promising results on link prediction task, on which two topics have been widely studied: one is the ability to handle complex relations, such as N-to-1, 1-to-N and N-to-N, the other is to encode various relation patterns, such as symmetry/antisymmetry. However, the existing methods fail to solve these two problems at the same time, which leads to unsatisfactory results. To mitigate this problem, we propose PairRE, a model with improved expressiveness and low computational requirement. PairRE represents each relation with paired vectors, where these paired vectors project connected two entities to relation specific locations. Beyond its ability to solve the aforementioned two problems, PairRE is advantageous to represent subrelation as it can capture both the similarities and differences of subrelations effectively. Given simple constraints on relation representations, PairRE can be the first model that is capable of encoding symmetry/antisymmetry, inverse, composition and subrelation relations. Experiments on link prediction benchmarks show PairRE can achieve either state-of-the-art or highly competitive performances. In addition, PairRE has shown encouraging results for encoding subrelation.
A Policy Gradient Method with Variance Reduction for Uplift Modeling
Nov 26, 2018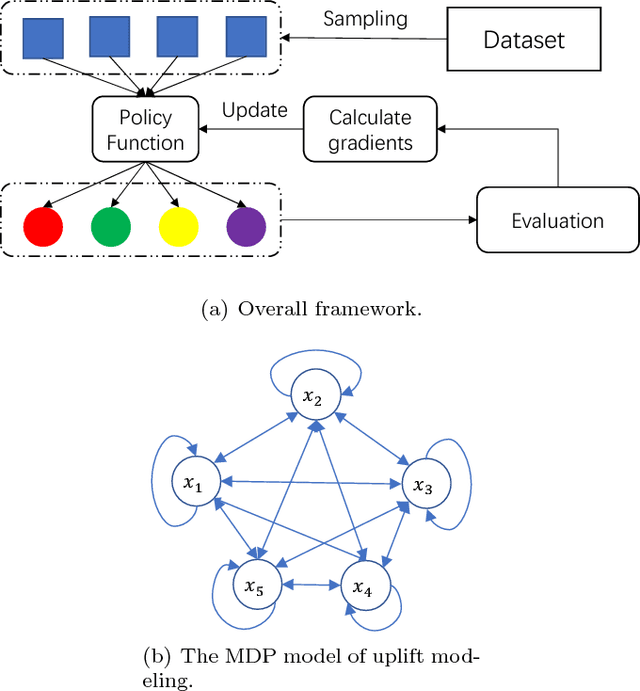

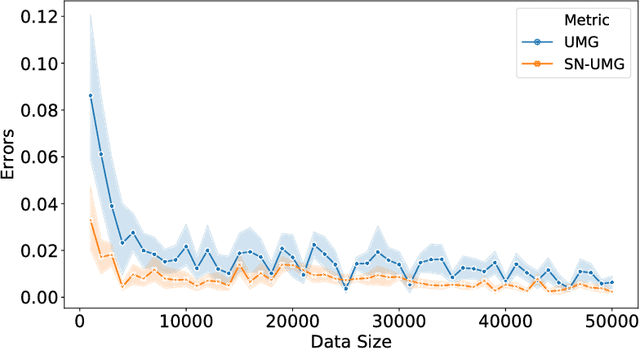
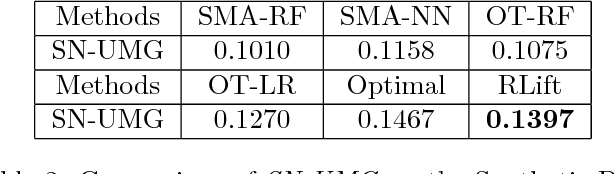
Uplift modeling aims to directly model the incremental impact of a treatment on an individual response. It has been widely and successfully used in healthcare analytics and business operations, where one tries to measure the net effect of a new medicine on patients or to understand the impact of a marketing campaign on company revenue. In this work, we address the problem from a new angle and reformulate it as a Markov Decision Process (MDP). This new formulation allows us to handle the lack of explicit labels, to deal with any number of actions (in comparison to the normal two action uplift modeling), and to apply it to applications with responses of general types, which is a challenging task for previous methods. Furthermore, we also design an unbiased metric for more accurate offline evaluation of uplift effects, set up a better reward function for the policy gradient method to solve the problem and adopt some action-based baselines to reduce variance. We conducted extensive experiments on both a synthetic dataset and real-world scenarios, and showed that our method can achieve significant improvement over previous methods.
Latent Dirichlet Allocation for Internet Price War
Aug 23, 2018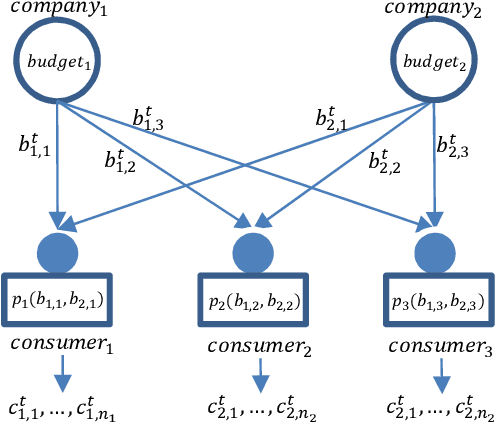
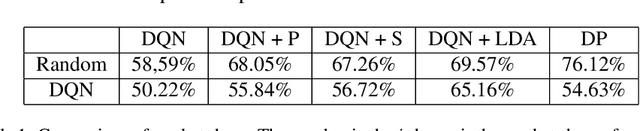
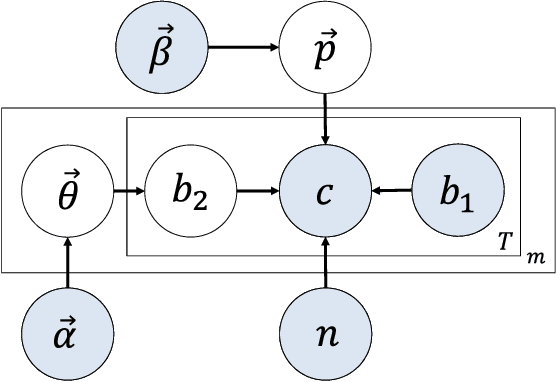

Internet market makers are always facing intense competitive environment, where personalized price reductions or discounted coupons are provided for attracting more customers. Participants in such a price war scenario have to invest a lot to catch up with other competitors. However, such a huge cost of money may not always lead to an improvement of market share. This is mainly due to a lack of information about others' strategies or customers' willingness when participants develop their strategies. In order to obtain this hidden information through observable data, we study the relationship between companies and customers in the Internet price war. Theoretically, we provide a formalization of the problem as a stochastic game with imperfect and incomplete information. Then we develop a variant of Latent Dirichlet Allocation (LDA) to infer latent variables under the current market environment, which represents the preferences of customers and strategies of competitors. To our best knowledge, it is the first time that LDA is applied to game scenario. We conduct simulated experiments where our LDA model exhibits a significant improvement on finding strategies in the Internet price war by including all available market information of the market maker's competitors. And the model is applied to an open dataset for real business. Through comparisons on the likelihood of prediction for users' behavior and distribution distance between inferred opponent's strategy and the real one, our model is shown to be able to provide a better understanding for the market environment. Our work marks a successful learning method to infer latent information in the environment of price war by the LDA modeling, and sets an example for related competitive applications to follow.