 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
DRGCN: Dynamic Evolving Initial Residual for Deep Graph Convolutional Networks
Feb 10, 2023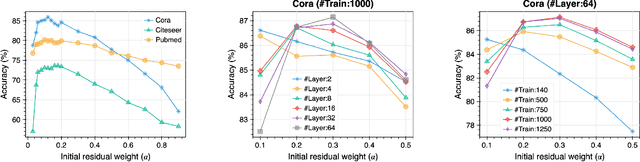



Graph convolutional networks (GCNs) have been proved to be very practical to handle various graph-related tasks. It has attracted considerable research interest to study deep GCNs, due to their potential superior performance compared with shallow ones. However, simply increasing network depth will, on the contrary, hurt the performance due to the over-smoothing problem. Adding residual connection is proved to be effective for learning deep convolutional neural networks (deep CNNs), it is not trivial when applied to deep GCNs. Recent works proposed an initial residual mechanism that did alleviate the over-smoothing problem in deep GCNs. However, according to our study, their algorithms are quite sensitive to different datasets. In their setting, the personalization (dynamic) and correlation (evolving) of how residual applies are ignored. To this end, we propose a novel model called Dynamic evolving initial Residual Graph Convolutional Network (DRGCN). Firstly, we use a dynamic block for each node to adaptively fetch information from the initial representation. Secondly, we use an evolving block to model the residual evolving pattern between layers. Our experimental results show that our model effectively relieves the problem of over-smoothing in deep GCNs and outperforms the state-of-the-art (SOTA) methods on various benchmark datasets. Moreover, we develop a mini-batch version of DRGCN which can be applied to large-scale data. Coupling with several fair training techniques, our model reaches new SOTA results on the large-scale ogbn-arxiv dataset of Open Graph Benchmark (OGB). Our reproducible code is available on GitHub.
Towards Understanding Distributional Reinforcement Learning: Regularization, Optimization, Acceleration and Sinkhorn Algorithm
Oct 07, 2021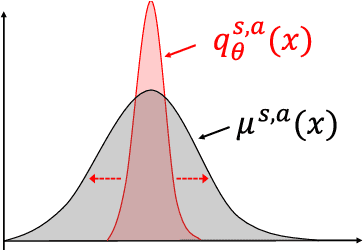
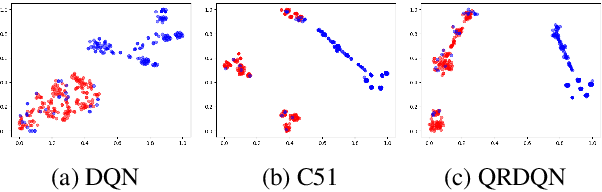
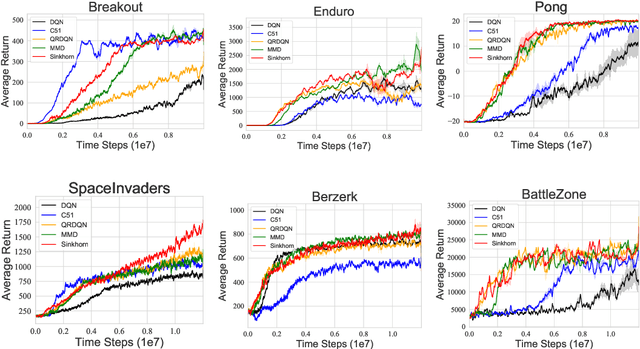
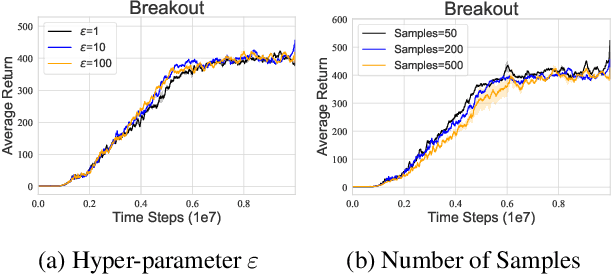
Distributional reinforcement learning~(RL) is a class of state-of-the-art algorithms that estimate the whole distribution of the total return rather than only its expectation. Despite the remarkable performance of distributional RL, a theoretical understanding of its advantages over expectation-based RL remains elusive. In this paper, we interpret distributional RL as entropy-regularized maximum likelihood estimation in the \textit{neural Z-fitted iteration} framework, and establish the connection of the resulting risk-aware regularization with maximum entropy RL. In addition, We shed light on the stability-promoting distributional loss with desirable smoothness properties in distributional RL, which can yield stable optimization and guaranteed generalization. We also analyze the acceleration behavior while optimizing distributional RL algorithms and show that an appropriate approximation to the true target distribution can speed up the convergence. From the perspective of representation, we find that distributional RL encourages state representation from the same action class classified by the policy in tighter clusters. Finally, we propose a class of \textit{Sinkhorn distributional RL} algorithm that interpolates between the Wasserstein distance and maximum mean discrepancy~(MMD). Experiments on a suite of Atari games reveal the competitive performance of our algorithm relative to existing state-of-the-art distributional RL algorithms.