 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
LogicMP: A Neuro-symbolic Approach for Encoding First-order Logic Constraints
Sep 29, 2023Integrating first-order logic constraints (FOLCs) with neural networks is a crucial but challenging problem since it involves modeling intricate correlations to satisfy the constraints. This paper proposes a novel neural layer, LogicMP, whose layers perform mean-field variational inference over an MLN. It can be plugged into any off-the-shelf neural network to encode FOLCs while retaining modularity and efficiency. By exploiting the structure and symmetries in MLNs, we theoretically demonstrate that our well-designed, efficient mean-field iterations effectively mitigate the difficulty of MLN inference, reducing the inference from sequential calculation to a series of parallel tensor operations. Empirical results in three kinds of tasks over graphs, images, and text show that LogicMP outperforms advanced competitors in both performance and efficiency.
MatchVIE: Exploiting Match Relevancy between Entities for Visual Information Extraction
Jun 24, 2021


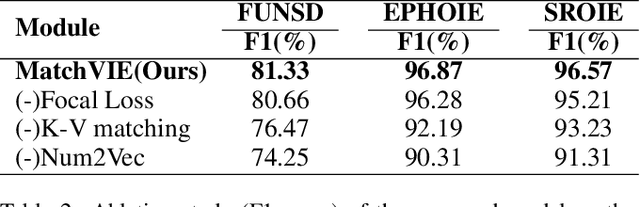
Visual Information Extraction (VIE) task aims to extract key information from multifarious document images (e.g., invoices and purchase receipts). Most previous methods treat the VIE task simply as a sequence labeling problem or classification problem, which requires models to carefully identify each kind of semantics by introducing multimodal features, such as font, color, layout. But simply introducing multimodal features couldn't work well when faced with numeric semantic categories or some ambiguous texts. To address this issue, in this paper we propose a novel key-value matching model based on a graph neural network for VIE (MatchVIE). Through key-value matching based on relevancy evaluation, the proposed MatchVIE can bypass the recognitions to various semantics, and simply focuses on the strong relevancy between entities. Besides, we introduce a simple but effective operation, Num2Vec, to tackle the instability of encoded values, which helps model converge more smoothly. Comprehensive experiments demonstrate that the proposed MatchVIE can significantly outperform previous methods. Notably, to the best of our knowledge, MatchVIE may be the first attempt to tackle the VIE task by modeling the relevancy between keys and values and it is a good complement to the existing methods.
Omnidirectional Scene Text Detection with Sequential-free Box Discretization
Jun 07, 2019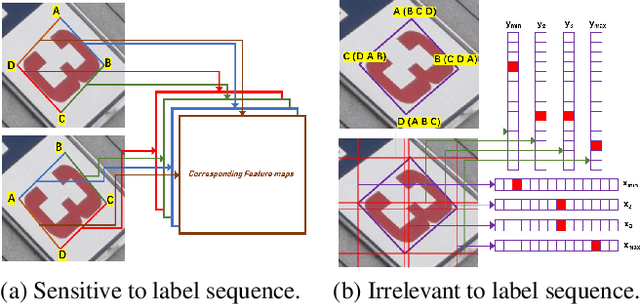



Scene text in the wild is commonly presented with high variant characteristics. Using quadrilateral bounding box to localize the text instance is nearly indispensable for detection methods. However, recent researches reveal that introducing quadrilateral bounding box for scene text detection will bring a label confusion issue which is easily overlooked, and this issue may significantly undermine the detection performance. To address this issue, in this paper, we propose a novel method called Sequential-free Box Discretization (SBD) by discretizing the bounding box into key edges (KE) which can further derive more effective methods to improve detection performance. Experiments showed that the proposed method can outperform state-of-the-art methods in many popular scene text benchmarks, including ICDAR 2015, MLT, and MSRA-TD500. Ablation study also showed that simply integrating the SBD into Mask R-CNN framework, the detection performance can be substantially improved. Furthermore, an experiment on the general object dataset HRSC2016 (multi-oriented ships) showed that our method can outperform recent state-of-the-art methods by a large margin, demonstrating its powerful generalization ability.
Aggregation Cross-Entropy for Sequence Recognition
Apr 18, 2019
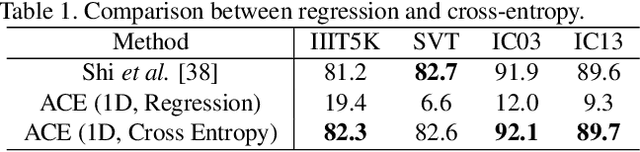

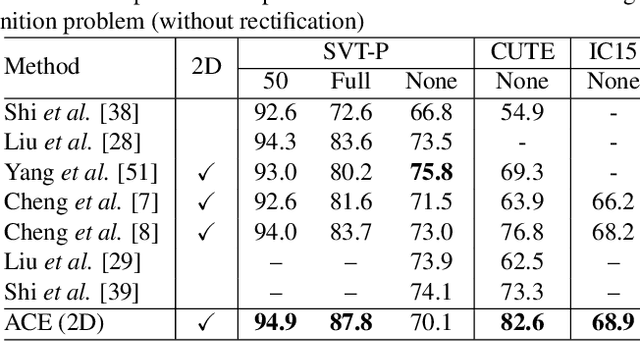
In this paper, we propose a novel method, aggregation cross-entropy (ACE), for sequence recognition from a brand new perspective. The ACE loss function exhibits competitive performance to CTC and the attention mechanism, with much quicker implementation (as it involves only four fundamental formulas), faster inference\back-propagation (approximately O(1) in parallel), less storage requirement (no parameter and negligible runtime memory), and convenient employment (by replacing CTC with ACE). Furthermore, the proposed ACE loss function exhibits two noteworthy properties: (1) it can be directly applied for 2D prediction by flattening the 2D prediction into 1D prediction as the input and (2) it requires only characters and their numbers in the sequence annotation for supervision, which allows it to advance beyond sequence recognition, e.g., counting problem. The code is publicly available at https://github.com/summerlvsong/Aggregation-Cross-Entropy.
Tightness-aware Evaluation Protocol for Scene Text Detection
Mar 27, 2019
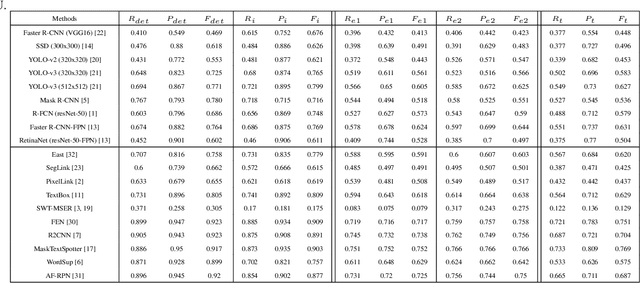

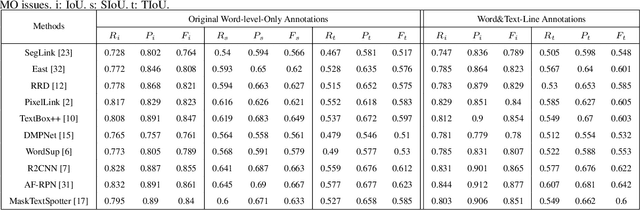
Evaluation protocols play key role in the developmental progress of text detection methods. There are strict requirements to ensure that the evaluation methods are fair, objective and reasonable. However, existing metrics exhibit some obvious drawbacks: 1) They are not goal-oriented; 2) they cannot recognize the tightness of detection methods; 3) existing one-to-many and many-to-one solutions involve inherent loopholes and deficiencies. Therefore, this paper proposes a novel evaluation protocol called Tightness-aware Intersect-over-Union (TIoU) metric that could quantify completeness of ground truth, compactness of detection, and tightness of matching degree. Specifically, instead of merely using the IoU value, two common detection behaviors are properly considered; meanwhile, directly using the score of TIoU to recognize the tightness. In addition, we further propose a straightforward method to address the annotation granularity issue, which can fairly evaluate word and text-line detections simultaneously. By adopting the detection results from published methods and general object detection frameworks, comprehensive experiments on ICDAR 2013 and ICDAR 2015 datasets are conducted to compare recent metrics and the proposed TIoU metric. The comparison demonstrated some promising new prospects, e.g., determining the methods and frameworks for which the detection is tighter and more beneficial to recognize. Our method is extremely simple; however, the novelty is none other than the proposed metric can utilize simplest but reasonable improvements to lead to many interesting and insightful prospects and solving most the issues of the previous metrics. The code is publicly available at https://github.com/Yuliang-Liu/TIoU-metric .
DeRPN: Taking a further step toward more general object detection
Nov 16, 2018



Most current detection methods have adopted anchor boxes as regression references. However, the detection performance is sensitive to the setting of the anchor boxes. A proper setting of anchor boxes may vary significantly across different datasets, which severely limits the universality of the detectors. To improve the adaptivity of the detectors, in this paper, we present a novel dimension-decomposition region proposal network (DeRPN) that can perfectly displace the traditional Region Proposal Network (RPN). DeRPN utilizes an anchor string mechanism to independently match object widths and heights, which is conducive to treating variant object shapes. In addition, a novel scale-sensitive loss is designed to address the imbalanced loss computations of different scaled objects, which can avoid the small objects being overwhelmed by larger ones. Comprehensive experiments conducted on both general object detection datasets (Pascal VOC 2007, 2012 and MS COCO) and scene text detection datasets (ICDAR 2013 and COCO-Text) all prove that our DeRPN can significantly outperform RPN. It is worth mentioning that the proposed DeRPN can be employed directly on different models, tasks, and datasets without any modifications of hyperparameters or specialized optimization, which further demonstrates its adaptivity. The code will be released at https://github.com/HCIILAB/DeRPN.
Detecting Heads using Feature Refine Net and Cascaded Multi-Scale Architecture
Oct 22, 2018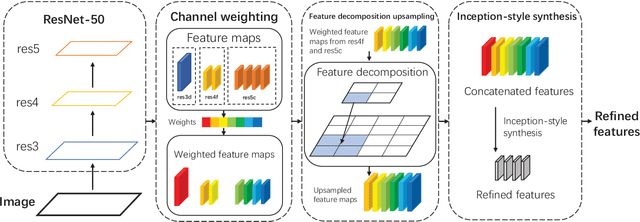
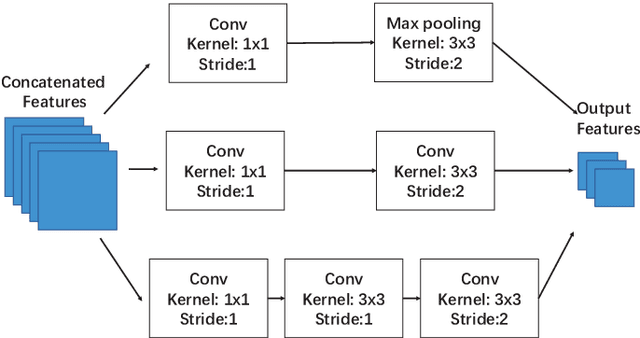
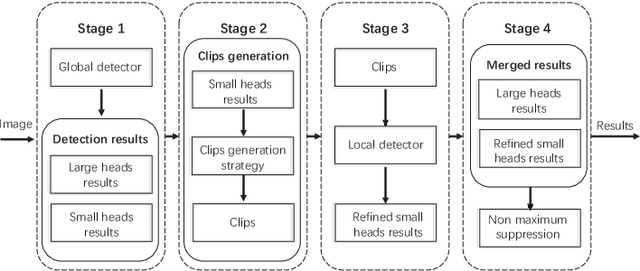
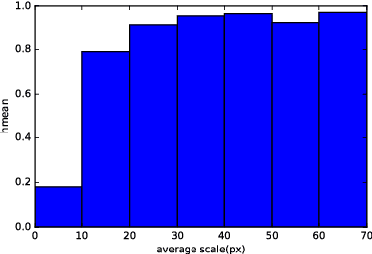
This paper presents a method that can accurately detect heads especially small heads under the indoor scene. To achieve this, we propose a novel method, Feature Refine Net (FRN), and a cascaded multi-scale architecture. FRN exploits the multi-scale hierarchical features created by deep convolutional neural networks. The proposed channel weighting method enables FRN to make use of features alternatively and effectively. To improve the performance of small head detection, we propose a cascaded multi-scale architecture which has two detectors. One called global detector is responsible for detecting large objects and acquiring the global distribution information. The other called local detector is designed for small objects detection and makes use of the information provided by global detector. Due to the lack of head detection datasets, we have collected and labeled a new large dataset named SCUT-HEAD which includes 4405 images with 111251 heads annotated. Experiments show that our method has achieved state-of-the-art performance on SCUT-HEAD.