 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyJR: Preserving Diversity in Reinforcement Learning with Verifiable Rewards via Dynamic Jensen-Shannon Replay
Mar 17, 2026While Reinforcement Learning (RL) enhances Large Language Model reasoning, on-policy algorithms like GRPO are sample-inefficient as they discard past rollouts. Existing experience replay methods address this by reusing accurate samples for direct policy updates, but this often incurs high computational costs and causes mode collapse via overfitting. We argue that historical data should prioritize sustaining diversity rather than simply reinforcing accuracy. To this end, we propose Dynamic Jensen-Shannon Replay (DyJR), a simple yet effective regularization framework using a dynamic reference distribution from recent trajectories. DyJR introduces two innovations: (1) A Time-Sensitive Dynamic Buffer that uses FIFO and adaptive sizing to retain only temporally proximal samples, synchronizing with model evolution; and (2) Jensen-Shannon Divergence Regularization, which replaces direct gradient updates with a distributional constraint to prevent diversity collapse. Experiments on mathematical reasoning and Text-to-SQL benchmarks demonstrate that DyJR significantly outperforms GRPO as well as baselines such as RLEP and Ex-GRPO, while maintaining training efficiency comparable to the original GRPO. Furthermore, from the perspective of Rank-$k$ token probability evolution, we show that DyJR enhances diversity and mitigates over-reliance on Rank-1 tokens, elucidating how specific sub-modules of DyJR influence the training dynamics.
SQL-ASTRA: Alleviating Sparse Feedback in Agentic SQL via Column-Set Matching and Trajectory Aggregation
Mar 17, 2026Agentic Reinforcement Learning (RL) shows promise for complex tasks, but Text-to-SQL remains mostly restricted to single-turn paradigms. A primary bottleneck is the credit assignment problem. In traditional paradigms, rewards are determined solely by the final-turn feedback, which ignores the intermediate process and leads to ambiguous credit evaluation. To address this, we propose Agentic SQL, a framework featuring a universal two-tiered reward mechanism designed to provide effective trajectory-level evaluation and dense step-level signals. First, we introduce Aggregated Trajectory Reward (ATR) to resolve multi-turn credit assignment. Using an asymmetric transition matrix, ATR aggregates process-oriented scores to incentivize continuous improvement. Leveraging Lyapunov stability theory, we prove ATR acts as an energy dissipation operator, guaranteeing a cycle-free policy and monotonic convergence. Second, Column-Set Matching Reward (CSMR) provides immediate step-level rewards to mitigate sparsity. By executing queries at each turn, CSMR converts binary (0/1) feedback into dense [0, 1] signals based on partial correctness. Evaluations on BIRD show a 5% gain over binary-reward GRPO. Notably, our approach outperforms SOTA Arctic-Text2SQL-R1-7B on BIRD and Spider 2.0 using identical models, propelling Text-to-SQL toward a robust multi-turn agent paradigm.
Structure-aware Semantic Discrepancy and Consistency for 3D Medical Image Self-supervised Learning
Jul 03, 20253D medical image self-supervised learning (mSSL) holds great promise for medical analysis. Effectively supporting broader applications requires considering anatomical structure variations in location, scale, and morphology, which are crucial for capturing meaningful distinctions. However, previous mSSL methods partition images with fixed-size patches, often ignoring the structure variations. In this work, we introduce a novel perspective on 3D medical images with the goal of learning structure-aware representations. We assume that patches within the same structure share the same semantics (semantic consistency) while those from different structures exhibit distinct semantics (semantic discrepancy). Based on this assumption, we propose an mSSL framework named $S^2DC$, achieving Structure-aware Semantic Discrepancy and Consistency in two steps. First, $S^2DC$ enforces distinct representations for different patches to increase semantic discrepancy by leveraging an optimal transport strategy. Second, $S^2DC$ advances semantic consistency at the structural level based on neighborhood similarity distribution. By bridging patch-level and structure-level representations, $S^2DC$ achieves structure-aware representations. Thoroughly evaluated across 10 datasets, 4 tasks, and 3 modalities, our proposed method consistently outperforms the state-of-the-art methods in mSSL.
Harnessing Negative Signals: Reinforcement Distillation from Teacher Data for LLM Reasoning
May 30, 2025Recent advances in model distillation demonstrate that data from advanced reasoning models (e.g., DeepSeek-R1, OpenAI's o1) can effectively transfer complex reasoning abilities to smaller, efficient student models. However, standard practices employ rejection sampling, discarding incorrect reasoning examples -- valuable, yet often underutilized data. This paper addresses the critical question: How can both positive and negative distilled reasoning traces be effectively leveraged to maximize LLM reasoning performance in an offline setting? To this end, We propose Reinforcement Distillation (REDI), a two-stage framework. Stage 1 learns from positive traces via Supervised Fine-Tuning (SFT). Stage 2 further refines the model using both positive and negative traces through our proposed REDI objective. This novel objective is a simple, reference-free loss function that outperforms established methods like DPO and SimPO in this distillation context. Our empirical evaluations demonstrate REDI's superiority over baseline Rejection Sampling SFT or SFT combined with DPO/SimPO on mathematical reasoning tasks. Notably, the Qwen-REDI-1.5B model, post-trained on just 131k positive and negative examples from the open Open-R1 dataset, achieves an 83.1% score on MATH-500 (pass@1). Its performance matches or surpasses that of DeepSeek-R1-Distill-Qwen-1.5B (a model post-trained on 800k proprietary data) across various mathematical reasoning benchmarks, establishing a new state-of-the-art for 1.5B models post-trained offline with openly available data.
Thought-Like-Pro: Enhancing Reasoning of Large Language Models through Self-Driven Prolog-based Chain-of-Though
Jul 18, 2024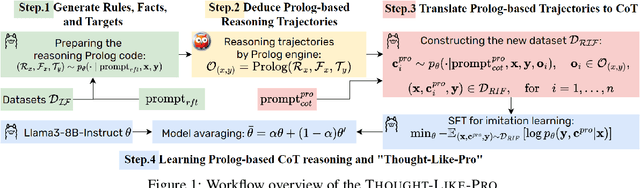
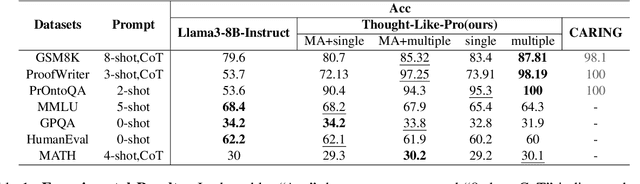
Large language models (LLMs) have shown exceptional performance as general-purpose assistants, excelling across a variety of reasoning tasks. This achievement represents a significant step toward achieving artificial general intelligence (AGI). Despite these advancements, the effectiveness of LLMs often hinges on the specific prompting strategies employed, and there remains a lack of a robust framework to facilitate learning and generalization across diverse reasoning tasks. To address these challenges, we introduce a novel learning framework, THOUGHT-LIKE-PRO In this framework, we utilize imitation learning to imitate the Chain-of-Thought (CoT) process which is verified and translated from reasoning trajectories generated by a symbolic Prolog logic engine. This framework proceeds in a self-driven manner, that enables LLMs to formulate rules and statements from given instructions and leverage the symbolic Prolog engine to derive results. Subsequently, LLMs convert Prolog-derived successive reasoning trajectories into natural language CoT for imitation learning. Our empirical findings indicate that our proposed approach substantially enhances the reasoning abilities of LLMs and demonstrates robust generalization across out-of-distribution reasoning tasks.
Denoising Time Cycle Modeling for Recommendation
Feb 05, 2024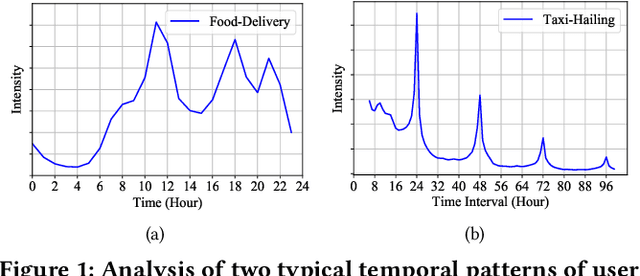
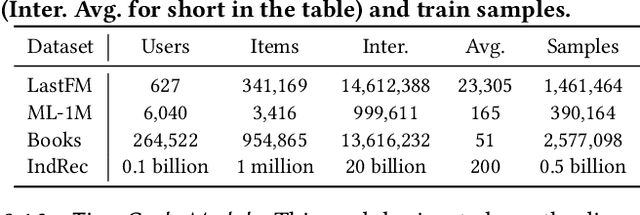
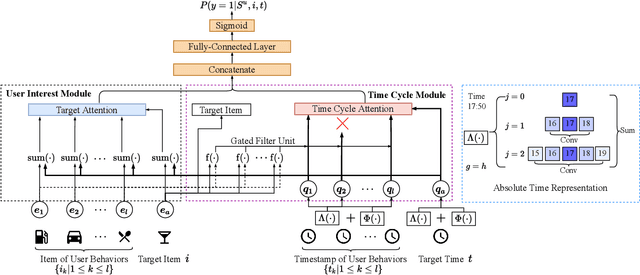
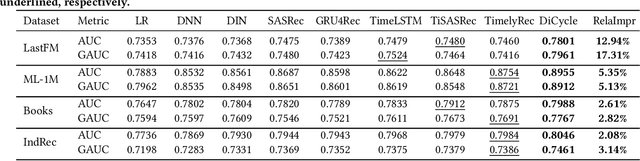
Recently, modeling temporal patterns of user-item interactions have attracted much attention in recommender systems. We argue that existing methods ignore the variety of temporal patterns of user behaviors. We define the subset of user behaviors that are irrelevant to the target item as noises, which limits the performance of target-related time cycle modeling and affect the recommendation performance. In this paper, we propose Denoising Time Cycle Modeling (DiCycle), a novel approach to denoise user behaviors and select the subset of user behaviors that are highly related to the target item. DiCycle is able to explicitly model diverse time cycle patterns for recommendation. Extensive experiments are conducted on both public benchmarks and a real-world dataset, demonstrating the superior performance of DiCycle over the state-of-the-art recommendation methods.
LogicMP: A Neuro-symbolic Approach for Encoding First-order Logic Constraints
Sep 29, 2023Integrating first-order logic constraints (FOLCs) with neural networks is a crucial but challenging problem since it involves modeling intricate correlations to satisfy the constraints. This paper proposes a novel neural layer, LogicMP, whose layers perform mean-field variational inference over an MLN. It can be plugged into any off-the-shelf neural network to encode FOLCs while retaining modularity and efficiency. By exploiting the structure and symmetries in MLNs, we theoretically demonstrate that our well-designed, efficient mean-field iterations effectively mitigate the difficulty of MLN inference, reducing the inference from sequential calculation to a series of parallel tensor operations. Empirical results in three kinds of tasks over graphs, images, and text show that LogicMP outperforms advanced competitors in both performance and efficiency.
Question Directed Graph Attention Network for Numerical Reasoning over Text
Sep 16, 2020
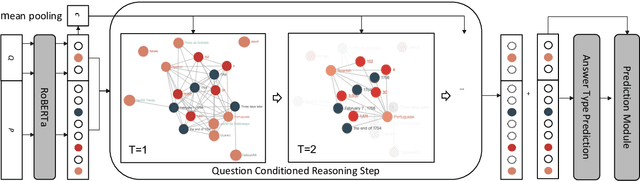
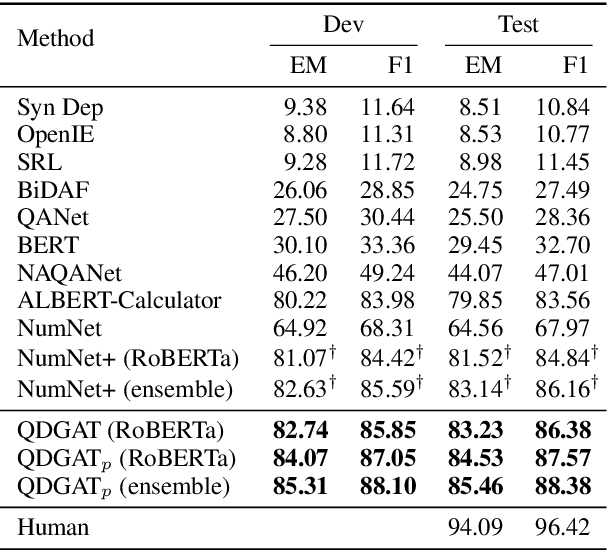
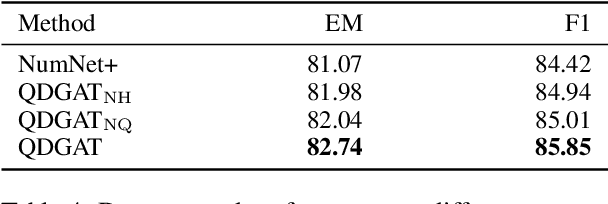
Numerical reasoning over texts, such as addition, subtraction, sorting and counting, is a challenging machine reading comprehension task, since it requires both natural language understanding and arithmetic computation. To address this challenge, we propose a heterogeneous graph representation for the context of the passage and question needed for such reasoning, and design a question directed graph attention network to drive multi-step numerical reasoning over this context graph.
SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
May 13, 2020
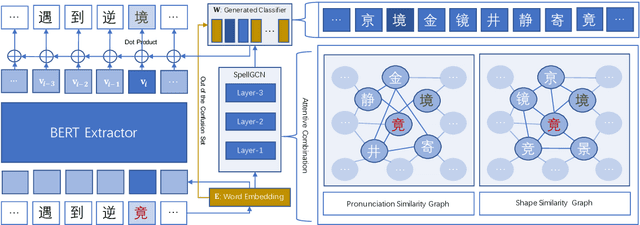
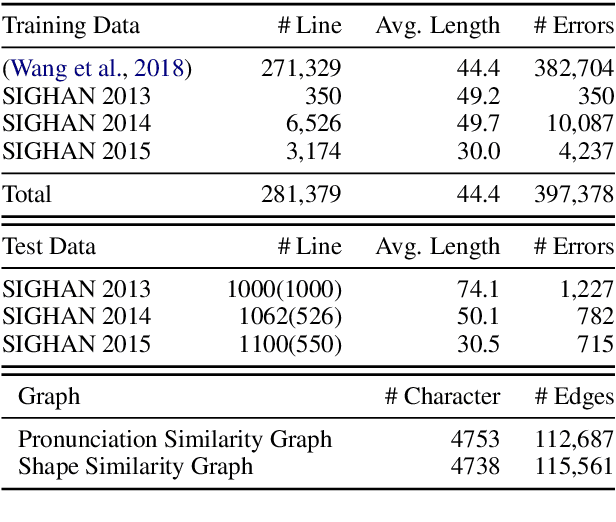
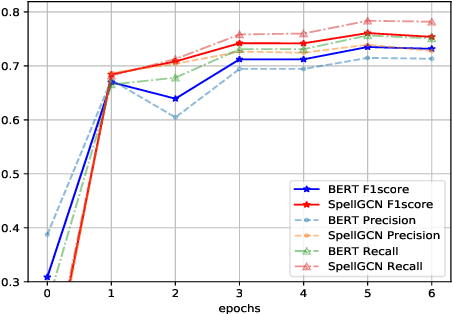
Chinese Spelling Check (CSC) is a task to detect and correct spelling errors in Chinese natural language. Existing methods have made attempts to incorporate the similarity knowledge between Chinese characters. However, they take the similarity knowledge as either an external input resource or just heuristic rules. This paper proposes to incorporate phonological and visual similarity knowledge into language models for CSC via a specialized graph convolutional network (SpellGCN). The model builds a graph over the characters, and SpellGCN is learned to map this graph into a set of inter-dependent character classifiers. These classifiers are applied to the representations extracted by another network, such as BERT, enabling the whole network to be end-to-end trainable. Experiments (The dataset and all code for this paper are available at https://github.com/ACL2020SpellGCN/SpellGCN) are conducted on three human-annotated datasets. Our method achieves superior performance against previous models by a large margin.
Symmetric Regularization based BERT for Pair-wise Semantic Reasoning
Sep 08, 2019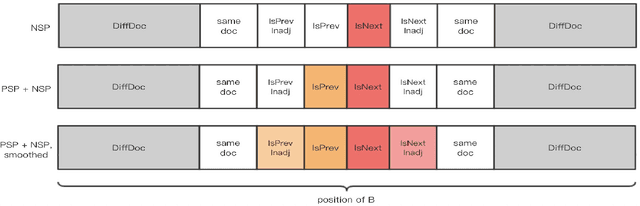
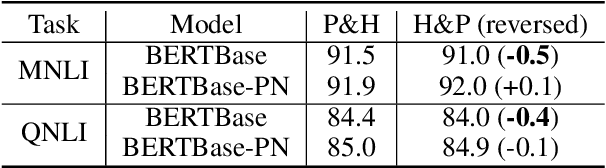
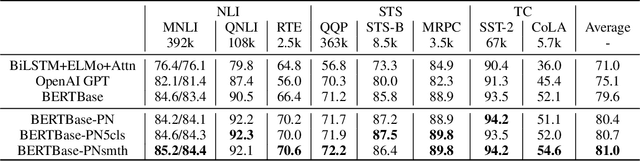
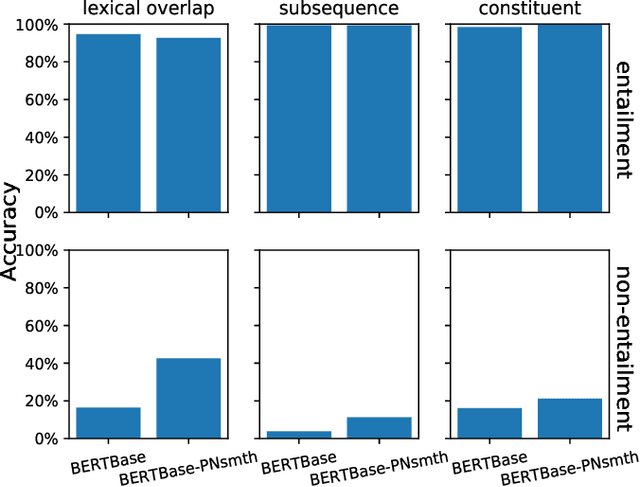
The ability of semantic reasoning over the sentence pair is essential for many natural language understanding tasks, e.g., natural language inference and machine reading comprehension. A recent significant improvement in these tasks comes from BERT. As reported, the next sentence prediction (NSP) in BERT, which learns the contextual relationship between two sentences, is of great significance for downstream problems with sentence-pair input. Despite the effectiveness of NSP, we suggest that NSP still lacks the essential signal to distinguish between entailment and shallow correlation. To remedy this, we propose to augment the NSP task to a 3-class categorization task, which includes a category for previous sentence prediction (PSP). The involvement of PSP encourages the model to focus on the informative semantics to determine the sentence order, thereby improves the ability of semantic understanding. This simple modification yields remarkable improvement against vanilla BERT. To further incorporate the document-level information, the scope of NSP and PSP is expanded into a broader range, i.e., NSP and PSP also include close but nonsuccessive sentences, the noise of which is mitigated by the label-smoothing technique. Both qualitative and quantitative experimental results demonstrate the effectiveness of the proposed method. Our method consistently improves the performance on the NLI and MRC benchmarks, including the challenging HANS dataset~\cite{hans}, suggesting that the document-level task is still promising for the pre-training.