 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMergeMix: Optimizing Mid-Training Data Mixtures via Learnable Model Merging
Jan 25, 2026Optimizing data mixtures is essential for unlocking the full potential of large language models (LLMs), yet identifying the optimal composition remains computationally prohibitive due to reliance on heuristic trials or expensive proxy training. To address this, we introduce \textbf{MergeMix}, a novel approach that efficiently determines optimal data mixing ratios by repurposing model merging weights as a high-fidelity, low-cost performance proxy. By training domain-specific experts on minimal tokens and optimizing their merging weights against downstream benchmarks, MergeMix effectively optimizes the performance of data mixtures without incurring the cost of full-scale training. Extensive experiments on models with 8B and 16B parameters validate that MergeMix achieves performance comparable to or surpassing exhaustive manual tuning while drastically reducing search costs. Furthermore, MergeMix exhibits high rank consistency (Spearman $ρ> 0.9$) and strong cross-scale transferability, offering a scalable, automated solution for data mixture optimization.
Arrows of Math Reasoning Data Synthesis for Large Language Models: Diversity, Complexity and Correctness
Aug 26, 2025Enhancing the mathematical reasoning of large language models (LLMs) demands high-quality training data, yet conventional methods face critical challenges in scalability, cost, and data reliability. To address these limitations, we propose a novel program-assisted synthesis framework that systematically generates a high-quality mathematical corpus with guaranteed diversity, complexity, and correctness. This framework integrates mathematical knowledge systems and domain-specific tools to create executable programs. These programs are then translated into natural language problem-solution pairs and vetted by a bilateral validation mechanism that verifies solution correctness against program outputs and ensures program-problem consistency. We have generated 12.3 million such problem-solving triples. Experiments demonstrate that models fine-tuned on our data significantly improve their inference capabilities, achieving state-of-the-art performance on several benchmark datasets and showcasing the effectiveness of our synthesis approach.
Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models
Jul 24, 2025Mixture-of-Experts (MoE) has become a dominant architecture for scaling Large Language Models (LLMs) efficiently by decoupling total parameters from computational cost. However, this decoupling creates a critical challenge: predicting the model capacity of a given MoE configurations (e.g., expert activation ratio and granularity) remains an unresolved problem. To address this gap, we introduce Efficiency Leverage (EL), a metric quantifying the computational advantage of an MoE model over a dense equivalent. We conduct a large-scale empirical study, training over 300 models up to 28B parameters, to systematically investigate the relationship between MoE architectural configurations and EL. Our findings reveal that EL is primarily driven by the expert activation ratio and the total compute budget, both following predictable power laws, while expert granularity acts as a non-linear modulator with a clear optimal range. We integrate these discoveries into a unified scaling law that accurately predicts the EL of an MoE architecture based on its configuration. To validate our derived scaling laws, we designed and trained Ling-mini-beta, a pilot model for Ling-2.0 series with only 0.85B active parameters, alongside a 6.1B dense model for comparison. When trained on an identical 1T high-quality token dataset, Ling-mini-beta matched the performance of the 6.1B dense model while consuming over 7x fewer computational resources, thereby confirming the accuracy of our scaling laws. This work provides a principled and empirically-grounded foundation for the scaling of efficient MoE models.
WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training
Jul 23, 2025Recent advances in learning rate (LR) scheduling have demonstrated the effectiveness of decay-free approaches that eliminate the traditional decay phase while maintaining competitive performance. Model merging techniques have emerged as particularly promising solutions in this domain. We present Warmup-Stable and Merge (WSM), a general framework that establishes a formal connection between learning rate decay and model merging. WSM provides a unified theoretical foundation for emulating various decay strategies-including cosine decay, linear decay and inverse square root decay-as principled model averaging schemes, while remaining fully compatible with diverse optimization methods. Through extensive experiments, we identify merge duration-the training window for checkpoint aggregation-as the most critical factor influencing model performance, surpassing the importance of both checkpoint interval and merge quantity. Our framework consistently outperforms the widely-adopted Warmup-Stable-Decay (WSD) approach across multiple benchmarks, achieving significant improvements of +3.5% on MATH, +2.9% on HumanEval, and +5.5% on MMLU-Pro. The performance advantages extend to supervised fine-tuning scenarios, highlighting WSM's potential for long-term model refinement.
LLM-Powered Ensemble Learning for Paper Source Tracing: A GPU-Free Approach
Sep 17, 2024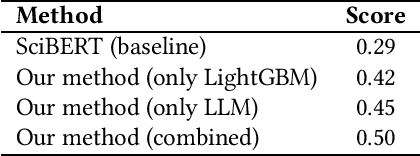

We participated in the KDD CUP 2024 paper source tracing competition and achieved the 3rd place. This competition tasked participants with identifying the reference sources (i.e., ref-sources, as referred to by the organizers of the competition) of given academic papers. Unlike most teams that addressed this challenge by fine-tuning pre-trained neural language models such as BERT or ChatGLM, our primary approach utilized closed-source large language models (LLMs). With recent advancements in LLM technology, closed-source LLMs have demonstrated the capability to tackle complex reasoning tasks in zero-shot or few-shot scenarios. Consequently, in the absence of GPUs, we employed closed-source LLMs to directly generate predicted reference sources from the provided papers. We further refined these predictions through ensemble learning. Notably, our method was the only one among the award-winning approaches that did not require the use of GPUs for model training. Code available at https://github.com/Cklwanfifa/KDDCUP2024-PST.
GP-NAS-ensemble: a model for NAS Performance Prediction
Jan 23, 2023
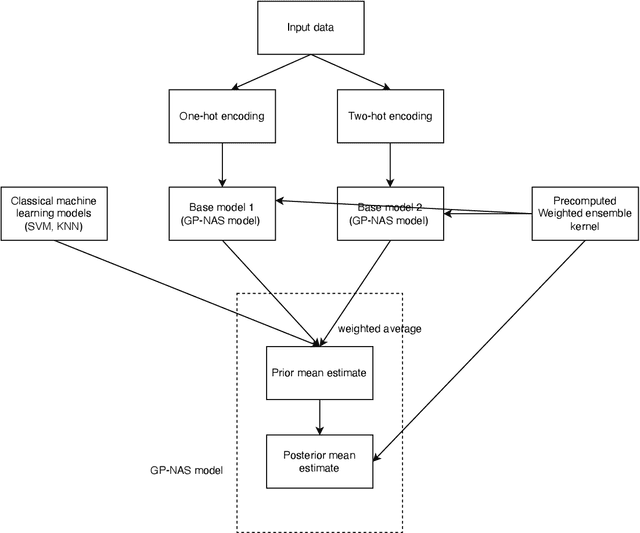
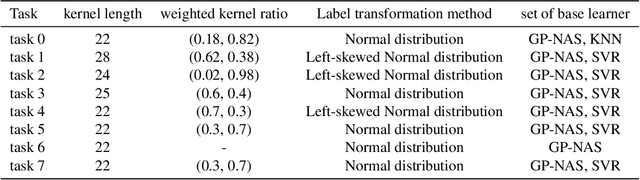
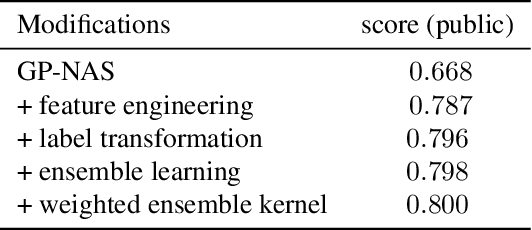
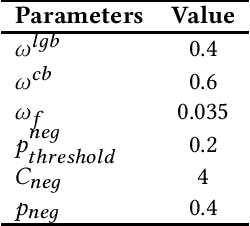
It is of great significance to estimate the performance of a given model architecture without training in the application of Neural Architecture Search (NAS) as it may take a lot of time to evaluate the performance of an architecture. In this paper, a novel NAS framework called GP-NAS-ensemble is proposed to predict the performance of a neural network architecture with a small training dataset. We make several improvements on the GP-NAS model to make it share the advantage of ensemble learning methods. Our method ranks second in the CVPR2022 second lightweight NAS challenge performance prediction track.
DQN Control Solution for KDD Cup 2021 City Brain Challenge
Aug 14, 2021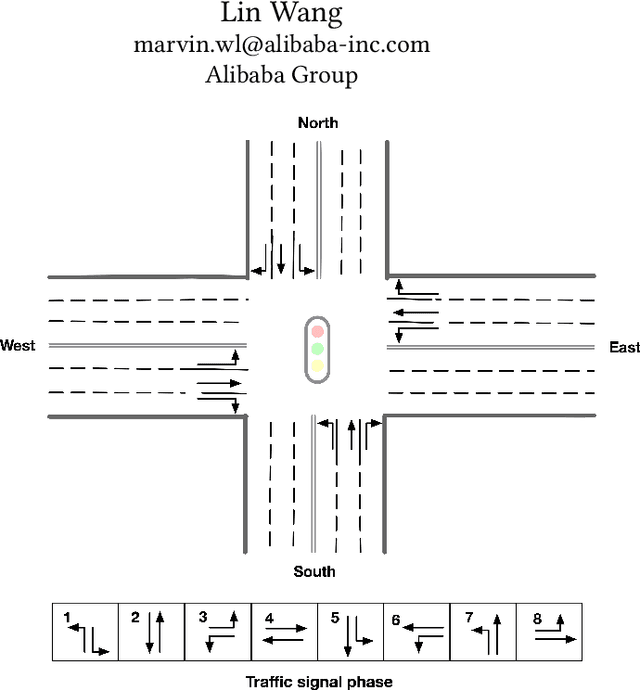

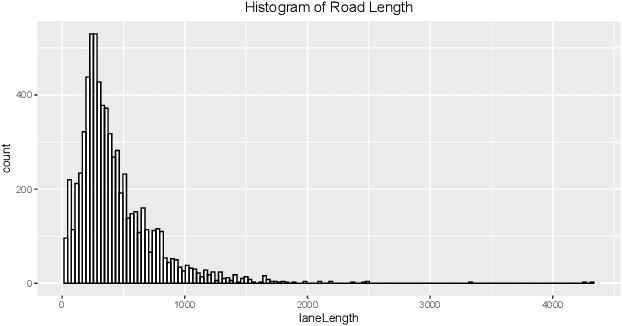
We took part in the city brain challenge competition and achieved the 8th place. In this competition, the players are provided with a real-world city-scale road network and its traffic demand derived from real traffic data. The players are asked to coordinate the traffic signals with a self-designed agent to maximize the number of vehicles served while maintaining an acceptable delay. In this abstract paper, we present an overall analysis and our detailed solution to this competition. Our approach is mainly based on the adaptation of the deep Q-network (DQN) for real-time traffic signal control. From our perspective, the major challenge of this competition is how to extend the classical DQN framework to traffic signals control in real-world complex road network and traffic flow situation. After trying and implementing several classical reward functions, we finally chose to apply our newly-designed reward in our agent. By applying our newly-proposed reward function and carefully tuning the control scheme, an agent based on a single DQN model can rank among the top 15 teams. We hope this paper could serve, to some extent, as a baseline solution to traffic signal control of real-world road network and inspire further attempts and researches.
Question Directed Graph Attention Network for Numerical Reasoning over Text
Sep 16, 2020
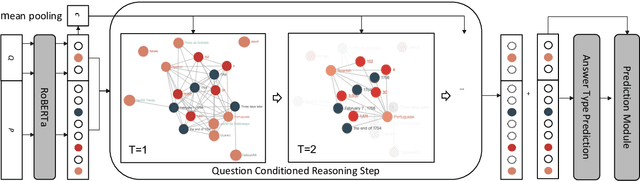
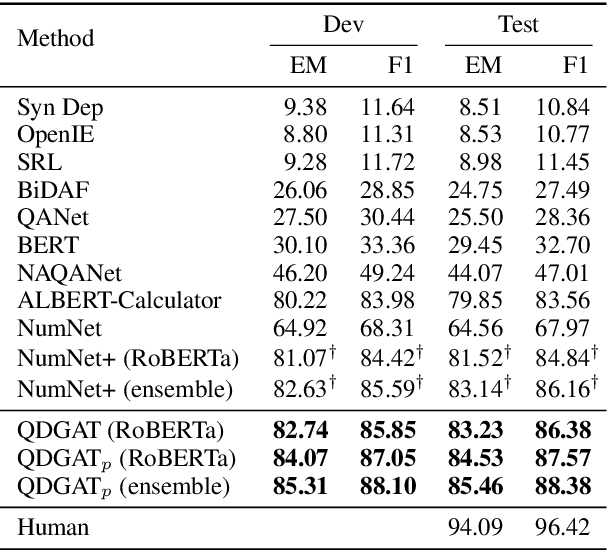
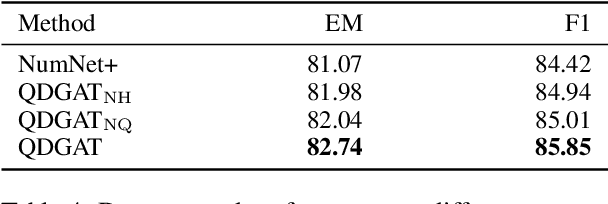
Numerical reasoning over texts, such as addition, subtraction, sorting and counting, is a challenging machine reading comprehension task, since it requires both natural language understanding and arithmetic computation. To address this challenge, we propose a heterogeneous graph representation for the context of the passage and question needed for such reasoning, and design a question directed graph attention network to drive multi-step numerical reasoning over this context graph.
SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
May 13, 2020
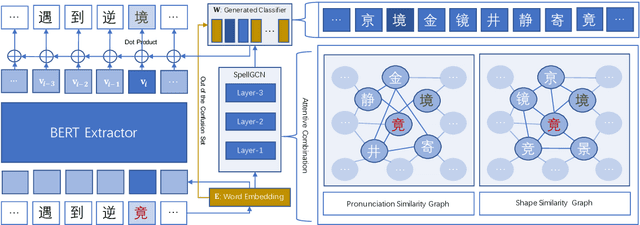
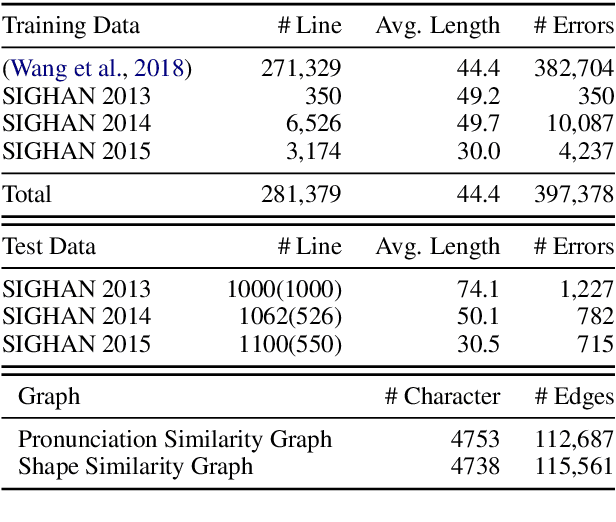
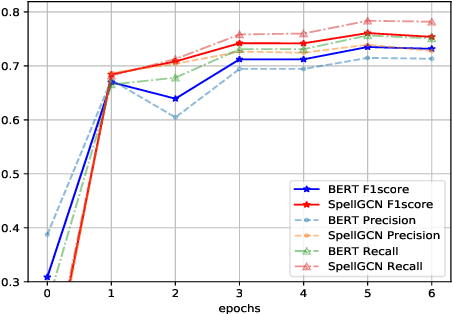
Chinese Spelling Check (CSC) is a task to detect and correct spelling errors in Chinese natural language. Existing methods have made attempts to incorporate the similarity knowledge between Chinese characters. However, they take the similarity knowledge as either an external input resource or just heuristic rules. This paper proposes to incorporate phonological and visual similarity knowledge into language models for CSC via a specialized graph convolutional network (SpellGCN). The model builds a graph over the characters, and SpellGCN is learned to map this graph into a set of inter-dependent character classifiers. These classifiers are applied to the representations extracted by another network, such as BERT, enabling the whole network to be end-to-end trainable. Experiments (The dataset and all code for this paper are available at https://github.com/ACL2020SpellGCN/SpellGCN) are conducted on three human-annotated datasets. Our method achieves superior performance against previous models by a large margin.
Symmetric Regularization based BERT for Pair-wise Semantic Reasoning
Sep 08, 2019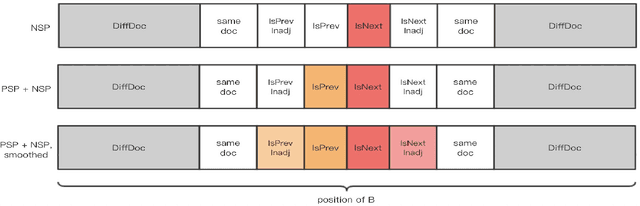
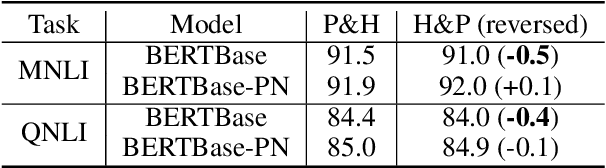
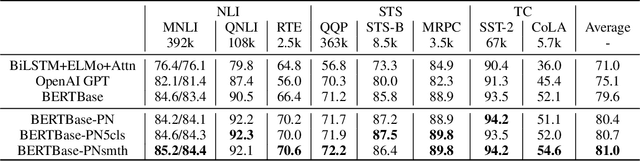
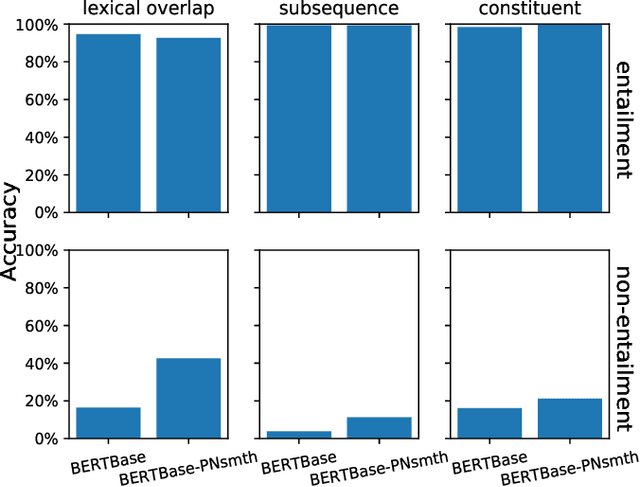
The ability of semantic reasoning over the sentence pair is essential for many natural language understanding tasks, e.g., natural language inference and machine reading comprehension. A recent significant improvement in these tasks comes from BERT. As reported, the next sentence prediction (NSP) in BERT, which learns the contextual relationship between two sentences, is of great significance for downstream problems with sentence-pair input. Despite the effectiveness of NSP, we suggest that NSP still lacks the essential signal to distinguish between entailment and shallow correlation. To remedy this, we propose to augment the NSP task to a 3-class categorization task, which includes a category for previous sentence prediction (PSP). The involvement of PSP encourages the model to focus on the informative semantics to determine the sentence order, thereby improves the ability of semantic understanding. This simple modification yields remarkable improvement against vanilla BERT. To further incorporate the document-level information, the scope of NSP and PSP is expanded into a broader range, i.e., NSP and PSP also include close but nonsuccessive sentences, the noise of which is mitigated by the label-smoothing technique. Both qualitative and quantitative experimental results demonstrate the effectiveness of the proposed method. Our method consistently improves the performance on the NLI and MRC benchmarks, including the challenging HANS dataset~\cite{hans}, suggesting that the document-level task is still promising for the pre-training.