 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Consciousness Theory from Computational Perspective
Sep 18, 2023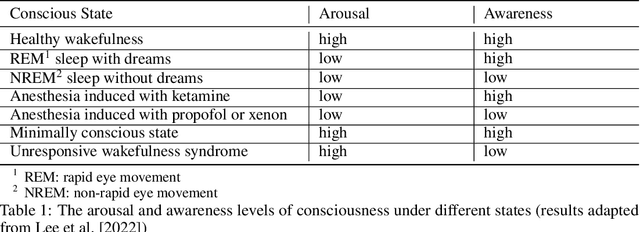
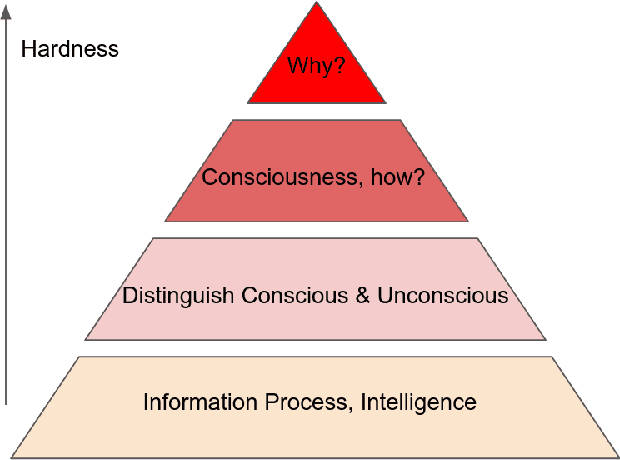
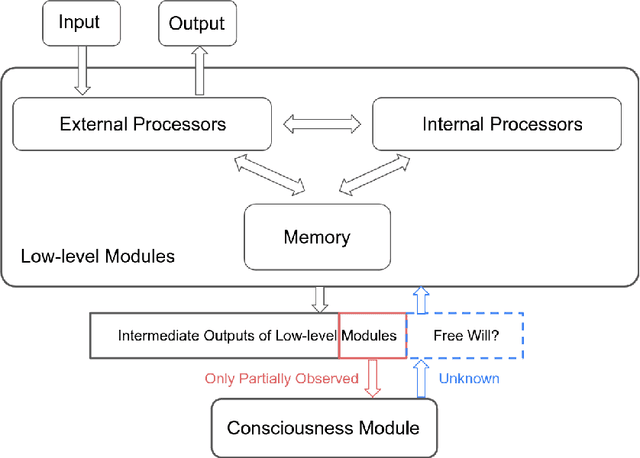
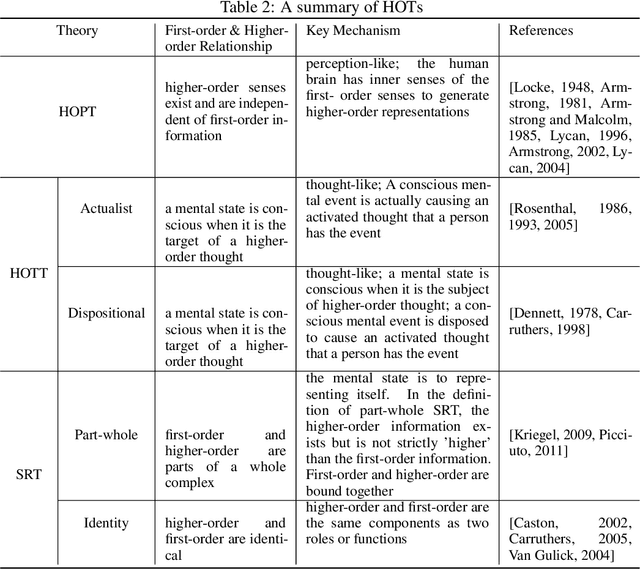
Human consciousness has been a long-lasting mystery for centuries, while machine intelligence and consciousness is an arduous pursuit. Researchers have developed diverse theories for interpreting the consciousness phenomenon in human brains from different perspectives and levels. This paper surveys several main branches of consciousness theories originating from different subjects including information theory, quantum physics, cognitive psychology, physiology and computer science, with the aim of bridging these theories from a computational perspective. It also discusses the existing evaluation metrics of consciousness and possibility for current computational models to be conscious. Breaking the mystery of consciousness can be an essential step in building general artificial intelligence with computing machines.
GP-NAS-ensemble: a model for NAS Performance Prediction
Jan 23, 2023
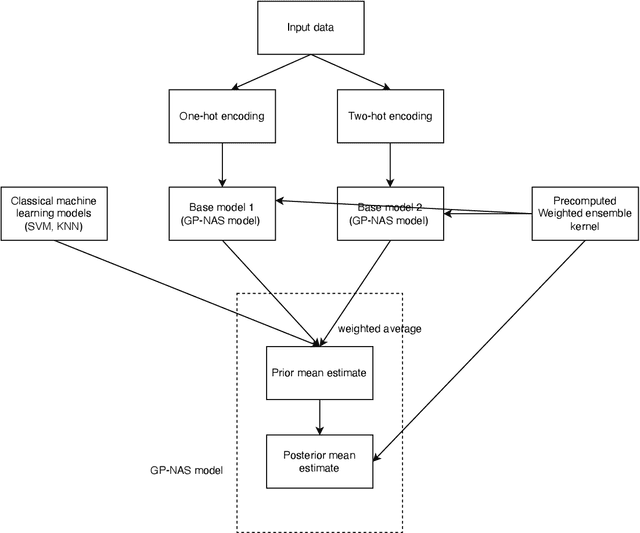
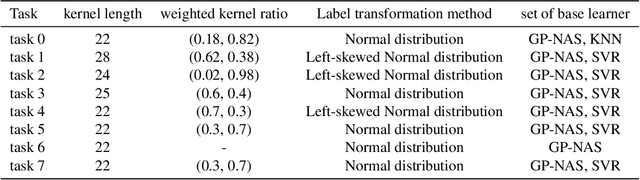
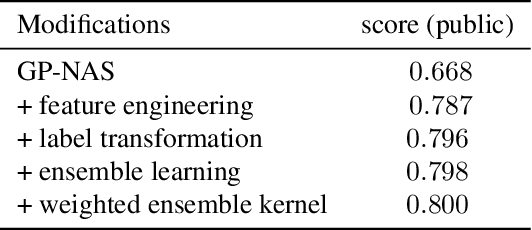
It is of great significance to estimate the performance of a given model architecture without training in the application of Neural Architecture Search (NAS) as it may take a lot of time to evaluate the performance of an architecture. In this paper, a novel NAS framework called GP-NAS-ensemble is proposed to predict the performance of a neural network architecture with a small training dataset. We make several improvements on the GP-NAS model to make it share the advantage of ensemble learning methods. Our method ranks second in the CVPR2022 second lightweight NAS challenge performance prediction track.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 25, 2021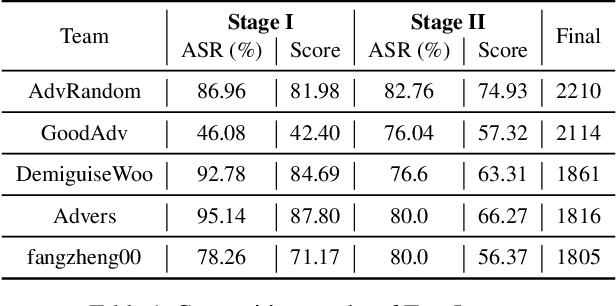
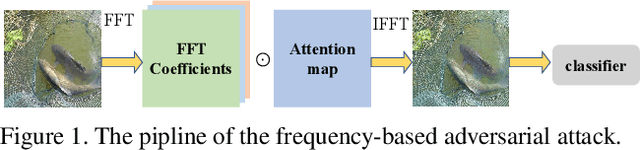
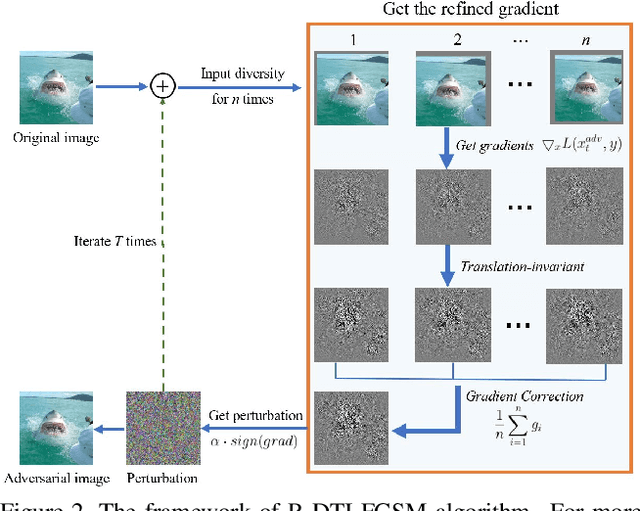
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
Encoding spatiotemporal priors with VAEs for small-area estimation
Oct 20, 2021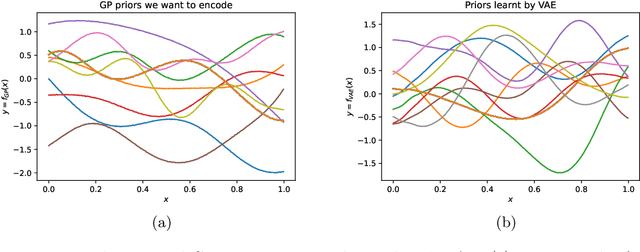
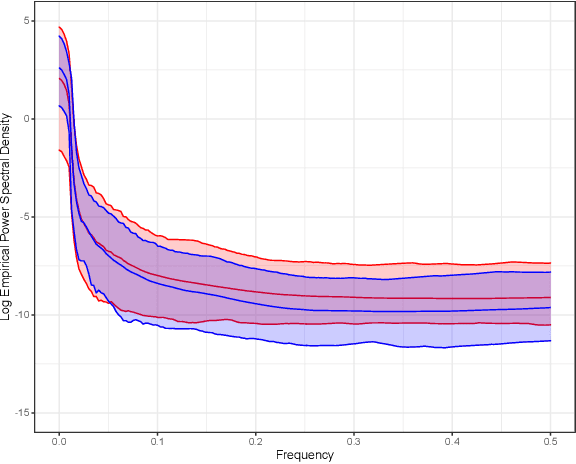
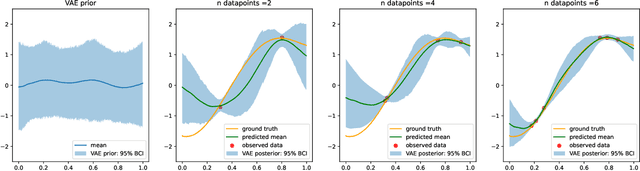
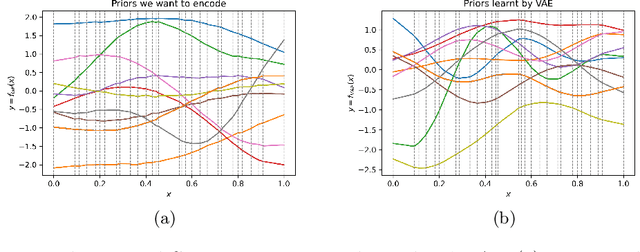
Gaussian processes (GPs), implemented through multivariate Gaussian distributions for a finite collection of data, are the most popular approach in small-area spatiotemporal statistical modelling. In this context they are used to encode correlation structures over space and time and can generalise well in interpolation tasks. Despite their flexibility, off-the-shelf GPs present serious computational challenges which limit their scalability and practical usefulness in applied settings. Here, we propose a novel, deep generative modelling approach to tackle this challenge: for a particular spatiotemporal setting, we approximate a class of GP priors through prior sampling and subsequent fitting of a variational autoencoder (VAE). Given a trained VAE, the resultant decoder allows spatiotemporal inference to become incredibly efficient due to the low dimensional, independently distributed latent Gaussian space representation of the VAE. Once trained, inference using the VAE decoder replaces the GP within a Bayesian sampling framework. This approach provides tractable and easy-to-implement means of approximately encoding spatiotemporal priors and facilitates efficient statistical inference. We demonstrate the utility of our VAE two stage approach on Bayesian, small-area estimation tasks.
Transfer Learning of Graph Neural Networks with Ego-graph Information Maximization
Sep 11, 2020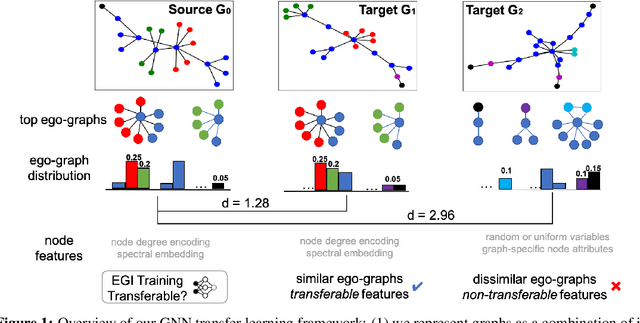
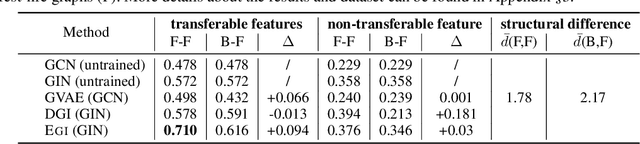
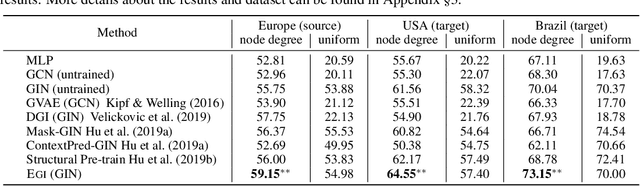
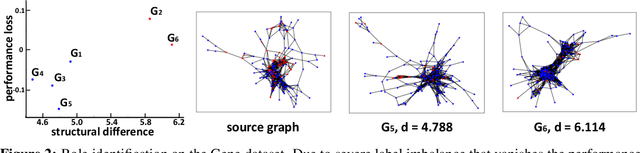
Graph neural networks (GNNs) have been shown with superior performance in various applications, but training dedicated GNNs can be costly for large-scale graphs. Some recent work started to study the pre-training of GNNs. However, none of them provide theoretical insights into the design of their frameworks, or clear requirements and guarantees towards the transferability of GNNs. In this work, we establish a theoretically grounded and practically useful framework for the transfer learning of GNNs. Firstly, we propose a novel view towards the essential graph information and advocate the capturing of it as the goal of transferable GNN training, which motivates the design of Ours, a novel GNN framework based on ego-graph information maximization to analytically achieve this goal. Secondly, we specify the requirement of structure-respecting node features as the GNN input, and derive a rigorous bound of GNN transferability based on the difference between the local graph Laplacians of the source and target graphs. Finally, we conduct controlled synthetic experiments to directly justify our theoretical conclusions. Extensive experiments on real-world networks towards role identification show consistent results in the rigorously analyzed setting of direct-transfering, while those towards large-scale relation prediction show promising results in the more generalized and practical setting of transfering with fine-tuning.