 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Semantics to Pixels: Coarse-to-Fine Masked Autoencoders for Hierarchical Visual Understanding
Mar 10, 2026Self-supervised visual pre-training methods face an inherent tension: contrastive learning (CL) captures global semantics but loses fine-grained detail, while masked image modeling (MIM) preserves local textures but suffers from "attention drift" due to semantically-agnostic random masking. We propose C2FMAE, a coarse-to-fine masked autoencoder that resolves this tension by explicitly learning hierarchical visual representations across three data granularities: semantic masks (scene-level), instance masks (object-level), and RGB images (pixel-level). Two synergistic innovations enforce a strict top-down learning principle. First, a cascaded decoder sequentially reconstructs from scene semantics to object instances to pixel details, establishing explicit cross-granularity dependencies that parallel decoders cannot capture. Second, a progressive masking curriculum dynamically shifts the training focus from semantic-guided to instance-guided and finally to random masking, creating a structured learning path from global context to local features. To support this framework, we construct a large-scale multi-granular dataset with high-quality pseudo-labels for all 1.28M ImageNet-1K images. Extensive experiments show that C2FMAE achieves significant performance gains on image classification, object detection, and semantic segmentation, validating the effectiveness of our hierarchical design in learning more robust and generalizable representations.
AEMIM: Adversarial Examples Meet Masked Image Modeling
Jul 16, 2024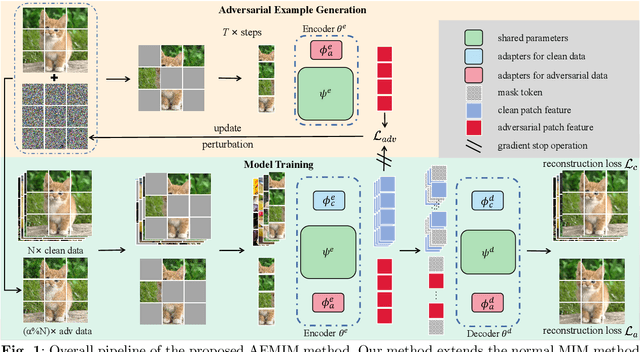


Masked image modeling (MIM) has gained significant traction for its remarkable prowess in representation learning. As an alternative to the traditional approach, the reconstruction from corrupted images has recently emerged as a promising pretext task. However, the regular corrupted images are generated using generic generators, often lacking relevance to the specific reconstruction task involved in pre-training. Hence, reconstruction from regular corrupted images cannot ensure the difficulty of the pretext task, potentially leading to a performance decline. Moreover, generating corrupted images might introduce an extra generator, resulting in a notable computational burden. To address these issues, we propose to incorporate adversarial examples into masked image modeling, as the new reconstruction targets. Adversarial examples, generated online using only the trained models, can directly aim to disrupt tasks associated with pre-training. Therefore, the incorporation not only elevates the level of challenge in reconstruction but also enhances efficiency, contributing to the acquisition of superior representations by the model. In particular, we introduce a novel auxiliary pretext task that reconstructs the adversarial examples corresponding to the original images. We also devise an innovative adversarial attack to craft more suitable adversarial examples for MIM pre-training. It is noted that our method is not restricted to specific model architectures and MIM strategies, rendering it an adaptable plug-in capable of enhancing all MIM methods. Experimental findings substantiate the remarkable capability of our approach in amplifying the generalization and robustness of existing MIM methods. Notably, our method surpasses the performance of baselines on various tasks, including ImageNet, its variants, and other downstream tasks.
Improving Model Generalization by On-manifold Adversarial Augmentation in the Frequency Domain
Feb 28, 2023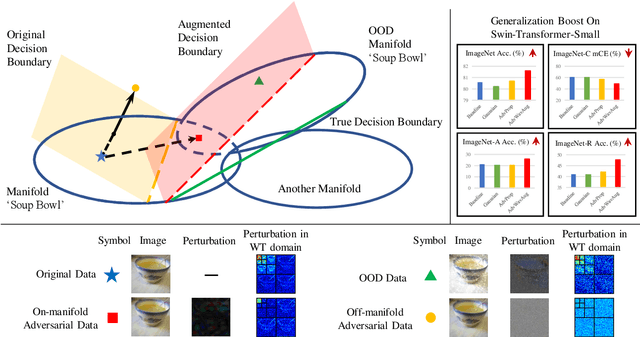

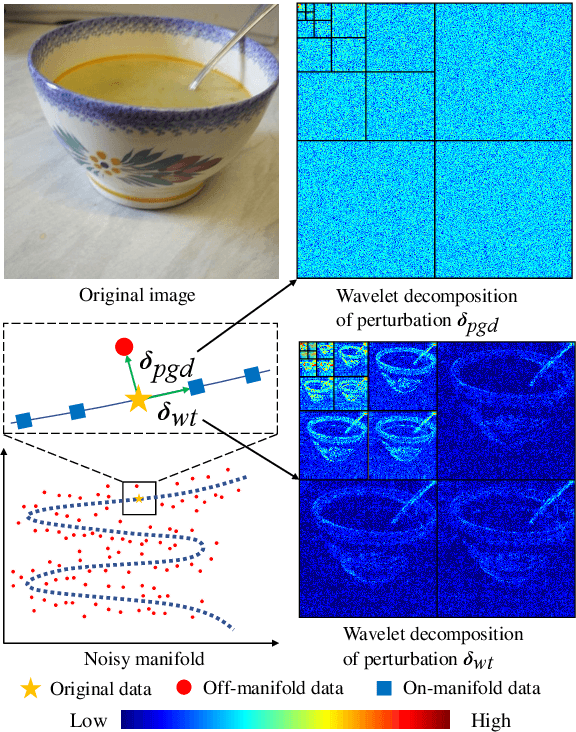
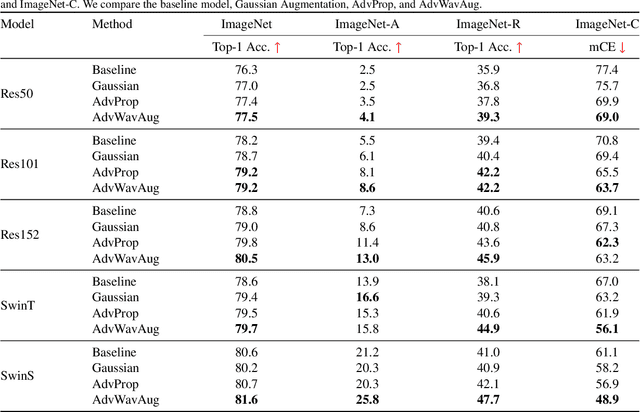
Deep neural networks (DNNs) may suffer from significantly degenerated performance when the training and test data are of different underlying distributions. Despite the importance of model generalization to out-of-distribution (OOD) data, the accuracy of state-of-the-art (SOTA) models on OOD data can plummet. Recent work has demonstrated that regular or off-manifold adversarial examples, as a special case of data augmentation, can be used to improve OOD generalization. Inspired by this, we theoretically prove that on-manifold adversarial examples can better benefit OOD generalization. Nevertheless, it is nontrivial to generate on-manifold adversarial examples because the real manifold is generally complex. To address this issue, we proposed a novel method of Augmenting data with Adversarial examples via a Wavelet module (AdvWavAug), an on-manifold adversarial data augmentation technique that is simple to implement. In particular, we project a benign image into a wavelet domain. With the assistance of the sparsity characteristic of wavelet transformation, we can modify an image on the estimated data manifold. We conduct adversarial augmentation based on AdvProp training framework. Extensive experiments on different models and different datasets, including ImageNet and its distorted versions, demonstrate that our method can improve model generalization, especially on OOD data. By integrating AdvWavAug into the training process, we have achieved SOTA results on some recent transformer-based models.
A Comprehensive Study on Robustness of Image Classification Models: Benchmarking and Rethinking
Feb 28, 2023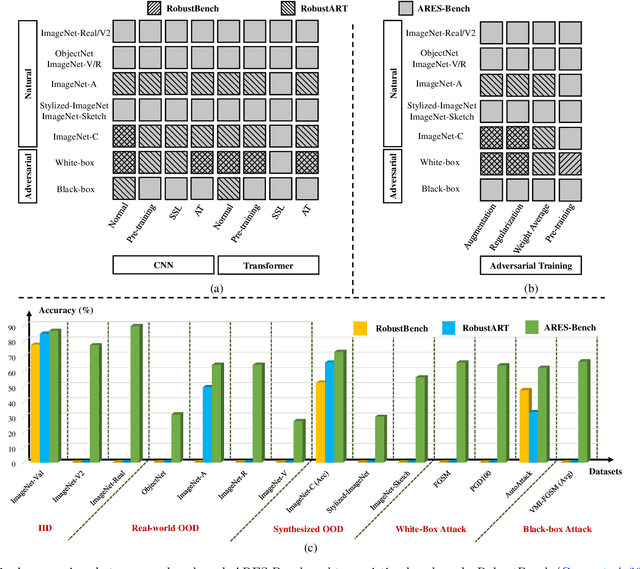

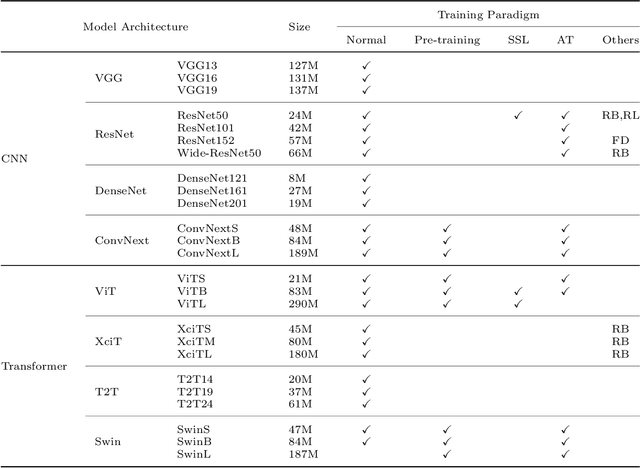
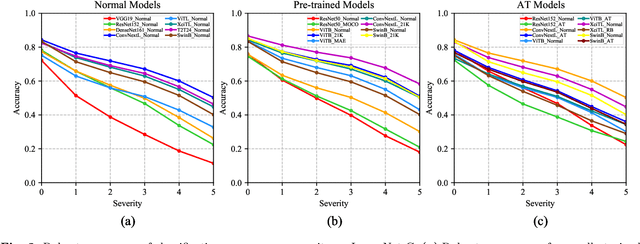
The robustness of deep neural networks is usually lacking under adversarial examples, common corruptions, and distribution shifts, which becomes an important research problem in the development of deep learning. Although new deep learning methods and robustness improvement techniques have been constantly proposed, the robustness evaluations of existing methods are often inadequate due to their rapid development, diverse noise patterns, and simple evaluation metrics. Without thorough robustness evaluations, it is hard to understand the advances in the field and identify the effective methods. In this paper, we establish a comprehensive robustness benchmark called \textbf{ARES-Bench} on the image classification task. In our benchmark, we evaluate the robustness of 55 typical deep learning models on ImageNet with diverse architectures (e.g., CNNs, Transformers) and learning algorithms (e.g., normal supervised training, pre-training, adversarial training) under numerous adversarial attacks and out-of-distribution (OOD) datasets. Using robustness curves as the major evaluation criteria, we conduct large-scale experiments and draw several important findings, including: 1) there is an inherent trade-off between adversarial and natural robustness for the same model architecture; 2) adversarial training effectively improves adversarial robustness, especially when performed on Transformer architectures; 3) pre-training significantly improves natural robustness based on more training data or self-supervised learning. Based on ARES-Bench, we further analyze the training tricks in large-scale adversarial training on ImageNet. By designing the training settings accordingly, we achieve the new state-of-the-art adversarial robustness. We have made the benchmarking results and code platform publicly available.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 25, 2021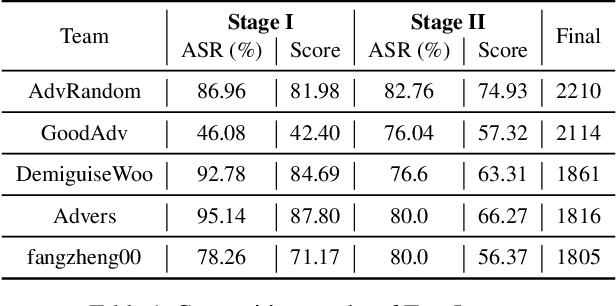
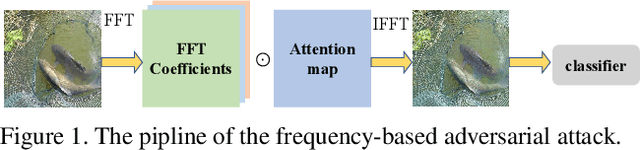
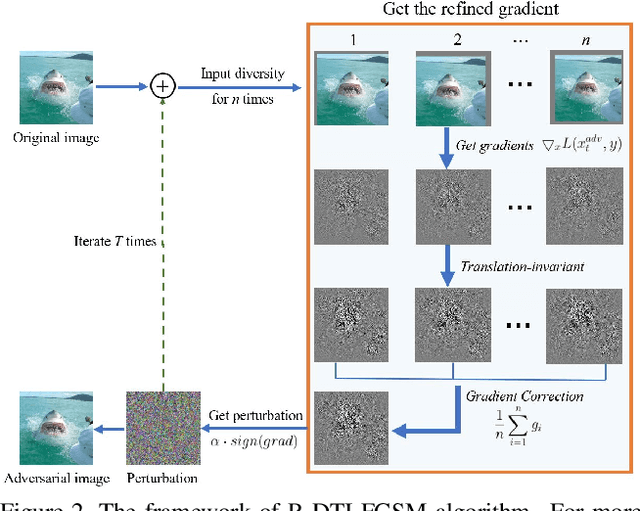
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
Adversarial Attacks on ML Defense Models Competition
Oct 15, 2021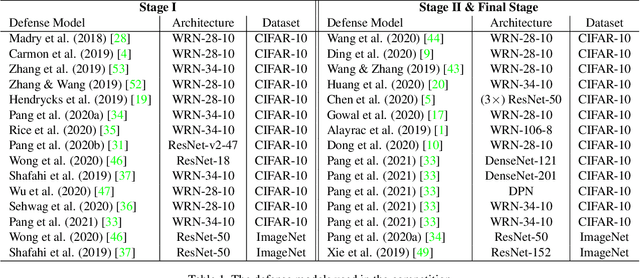
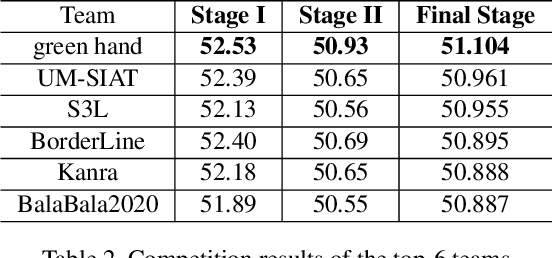
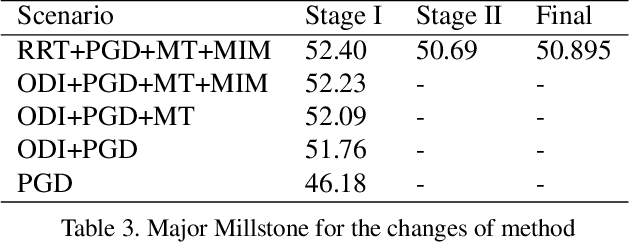
Due to the vulnerability of deep neural networks (DNNs) to adversarial examples, a large number of defense techniques have been proposed to alleviate this problem in recent years. However, the progress of building more robust models is usually hampered by the incomplete or incorrect robustness evaluation. To accelerate the research on reliable evaluation of adversarial robustness of the current defense models in image classification, the TSAIL group at Tsinghua University and the Alibaba Security group organized this competition along with a CVPR 2021 workshop on adversarial machine learning (https://aisecure-workshop.github.io/amlcvpr2021/). The purpose of this competition is to motivate novel attack algorithms to evaluate adversarial robustness more effectively and reliably. The participants were encouraged to develop stronger white-box attack algorithms to find the worst-case robustness of different defenses. This competition was conducted on an adversarial robustness evaluation platform -- ARES (https://github.com/thu-ml/ares), and is held on the TianChi platform (https://tianchi.aliyun.com/competition/entrance/531847/introduction) as one of the series of AI Security Challengers Program. After the competition, we summarized the results and established a new adversarial robustness benchmark at https://ml.cs.tsinghua.edu.cn/ares-bench/, which allows users to upload adversarial attack algorithms and defense models for evaluation.
Model-Agnostic Meta-Attack: Towards Reliable Evaluation of Adversarial Robustness
Oct 13, 2021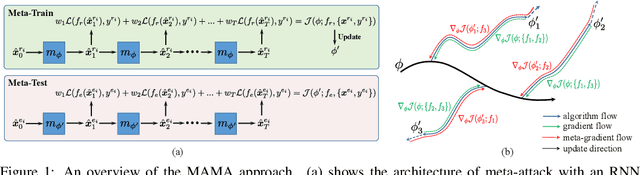

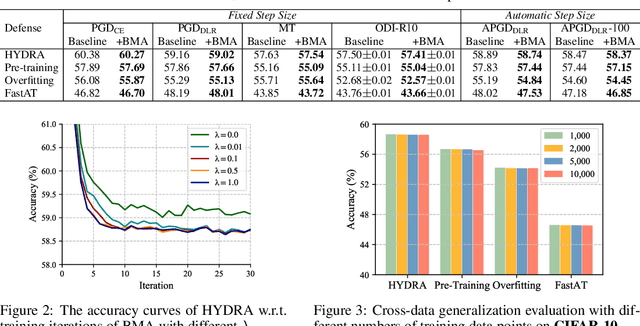
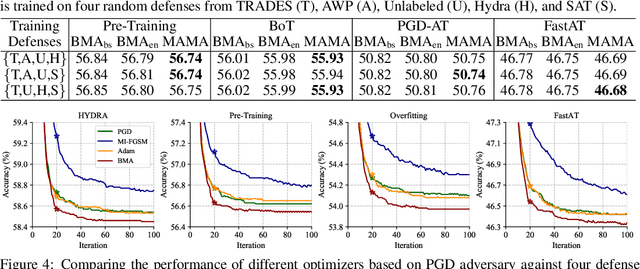
The vulnerability of deep neural networks to adversarial examples has motivated an increasing number of defense strategies for promoting model robustness. However, the progress is usually hampered by insufficient robustness evaluations. As the de facto standard to evaluate adversarial robustness, adversarial attacks typically solve an optimization problem of crafting adversarial examples with an iterative process. In this work, we propose a Model-Agnostic Meta-Attack (MAMA) approach to discover stronger attack algorithms automatically. Our method learns the optimizer in adversarial attacks parameterized by a recurrent neural network, which is trained over a class of data samples and defenses to produce effective update directions during adversarial example generation. Furthermore, we develop a model-agnostic training algorithm to improve the generalization ability of the learned optimizer when attacking unseen defenses. Our approach can be flexibly incorporated with various attacks and consistently improves the performance with little extra computational cost. Extensive experiments demonstrate the effectiveness of the learned attacks by MAMA compared to the state-of-the-art attacks on different defenses, leading to a more reliable evaluation of adversarial robustness.
You Cannot Easily Catch Me: A Low-Detectable Adversarial Patch for Object Detectors
Sep 30, 2021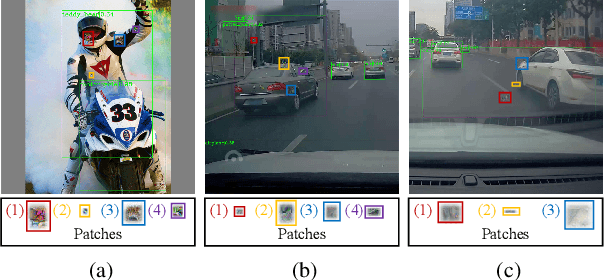
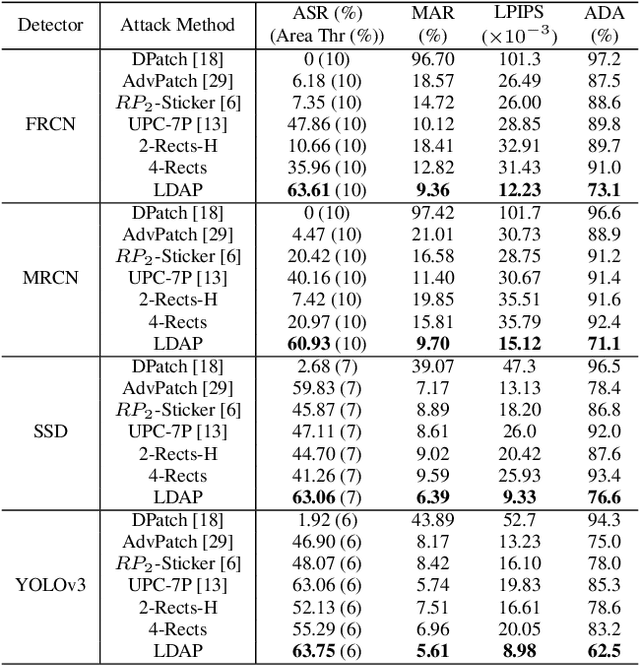
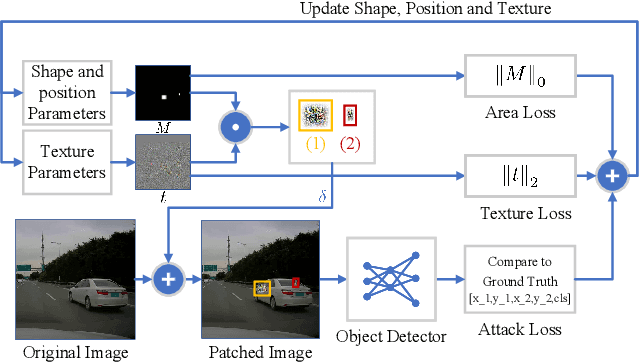

Blind spots or outright deceit can bedevil and deceive machine learning models. Unidentified objects such as digital "stickers," also known as adversarial patches, can fool facial recognition systems, surveillance systems and self-driving cars. Fortunately, most existing adversarial patches can be outwitted, disabled and rejected by a simple classification network called an adversarial patch detector, which distinguishes adversarial patches from original images. An object detector classifies and predicts the types of objects within an image, such as by distinguishing a motorcyclist from the motorcycle, while also localizing each object's placement within the image by "drawing" so-called bounding boxes around each object, once again separating the motorcyclist from the motorcycle. To train detectors even better, however, we need to keep subjecting them to confusing or deceitful adversarial patches as we probe for the models' blind spots. For such probes, we came up with a novel approach, a Low-Detectable Adversarial Patch, which attacks an object detector with small and texture-consistent adversarial patches, making these adversaries less likely to be recognized. Concretely, we use several geometric primitives to model the shapes and positions of the patches. To enhance our attack performance, we also assign different weights to the bounding boxes in terms of loss function. Our experiments on the common detection dataset COCO as well as the driving-video dataset D2-City show that LDAP is an effective attack method, and can resist the adversarial patch detector.
Improving Robustness of Adversarial Attacks Using an Affine-Invariant Gradient Estimator
Sep 13, 2021
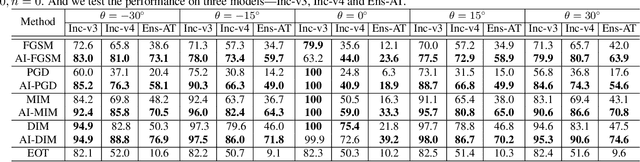
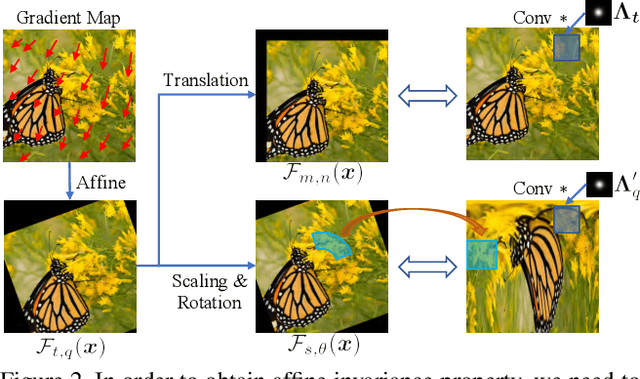
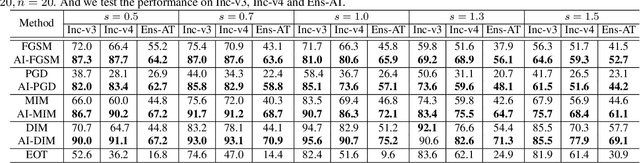
Adversarial examples can deceive a deep neural network (DNN) by significantly altering its response with imperceptible perturbations, which poses new potential vulnerabilities as the growing ubiquity of DNNs. However, most of the existing adversarial examples cannot maintain the malicious functionality if we apply an affine transformation on the resultant examples, which is an important measurement to the robustness of adversarial attacks for the practical risks. To address this issue, we propose an affine-invariant adversarial attack which can consistently construct adversarial examples robust over a distribution of affine transformation. To further improve the efficiency, we propose to disentangle the affine transformation into rotations, translations, magnifications, and reformulate the transformation in polar space. Afterwards, we construct an affine-invariant gradient estimator by convolving the gradient at the original image with derived kernels, which can be integrated with any gradient-based attack methods. Extensive experiments on the ImageNet demonstrate that our method can consistently produce more robust adversarial examples under significant affine transformations, and as a byproduct, improve the transferability of adversarial examples compared with the alternative state-of-the-art methods.
Improving Visual Quality of Unrestricted Adversarial Examples with Wavelet-VAE
Aug 25, 2021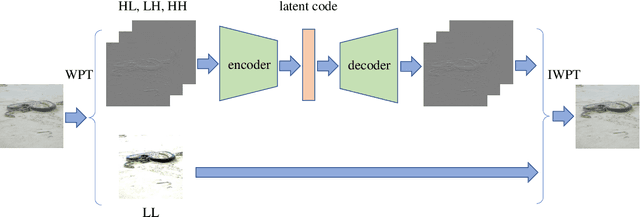
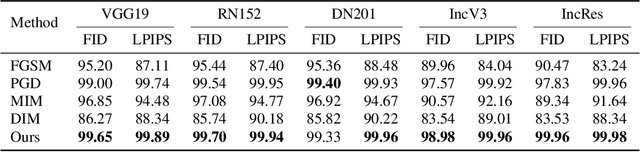

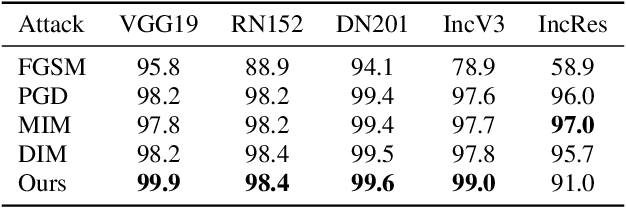
Traditional adversarial examples are typically generated by adding perturbation noise to the input image within a small matrix norm. In practice, un-restricted adversarial attack has raised great concern and presented a new threat to the AI safety. In this paper, we propose a wavelet-VAE structure to reconstruct an input image and generate adversarial examples by modifying the latent code. Different from perturbation-based attack, the modifications of the proposed method are not limited but imperceptible to human eyes. Experiments show that our method can generate high quality adversarial examples on ImageNet dataset.