 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR-Agent: Adaptive Graph Reasoning Agent under Incomplete Knowledge
Dec 16, 2025

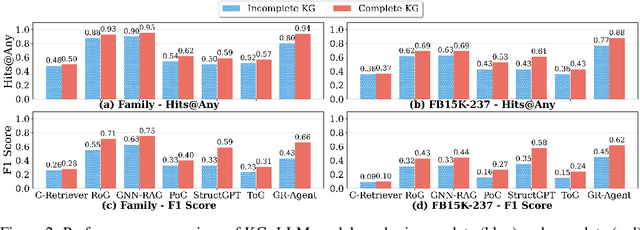

Large language models (LLMs) achieve strong results on knowledge graph question answering (KGQA), but most benchmarks assume complete knowledge graphs (KGs) where direct supporting triples exist. This reduces evaluation to shallow retrieval and overlooks the reality of incomplete KGs, where many facts are missing and answers must be inferred from existing facts. We bridge this gap by proposing a methodology for constructing benchmarks under KG incompleteness, which removes direct supporting triples while ensuring that alternative reasoning paths required to infer the answer remain. Experiments on benchmarks constructed using our methodology show that existing methods suffer consistent performance degradation under incompleteness, highlighting their limited reasoning ability. To overcome this limitation, we present the Adaptive Graph Reasoning Agent (GR-Agent). It first constructs an interactive environment from the KG, and then formalizes KGQA as agent environment interaction within this environment. GR-Agent operates over an action space comprising graph reasoning tools and maintains a memory of potential supporting reasoning evidence, including relevant relations and reasoning paths. Extensive experiments demonstrate that GR-Agent outperforms non-training baselines and performs comparably to training-based methods under both complete and incomplete settings.
What Breaks Knowledge Graph based RAG? Empirical Insights into Reasoning under Incomplete Knowledge
Aug 11, 2025Knowledge Graph-based Retrieval-Augmented Generation (KG-RAG) is an increasingly explored approach for combining the reasoning capabilities of large language models with the structured evidence of knowledge graphs. However, current evaluation practices fall short: existing benchmarks often include questions that can be directly answered using existing triples in KG, making it unclear whether models perform reasoning or simply retrieve answers directly. Moreover, inconsistent evaluation metrics and lenient answer matching criteria further obscure meaningful comparisons. In this work, we introduce a general method for constructing benchmarks, together with an evaluation protocol, to systematically assess KG-RAG methods under knowledge incompleteness. Our empirical results show that current KG-RAG methods have limited reasoning ability under missing knowledge, often rely on internal memorization, and exhibit varying degrees of generalization depending on their design.
Multibeam High Throughput Satellite: Hardware Foundation, Resource Allocation, and Precoding
Aug 01, 2025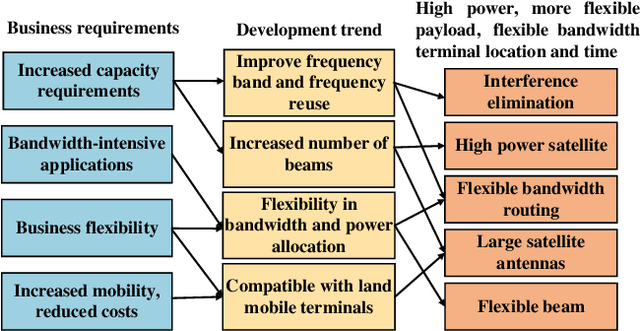
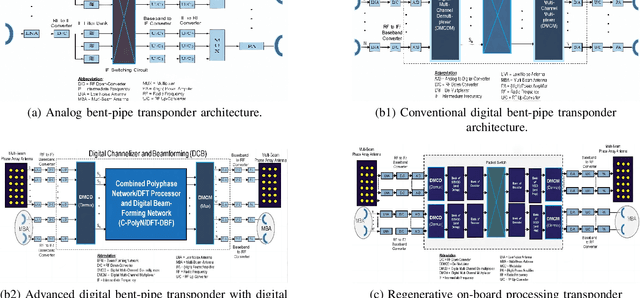
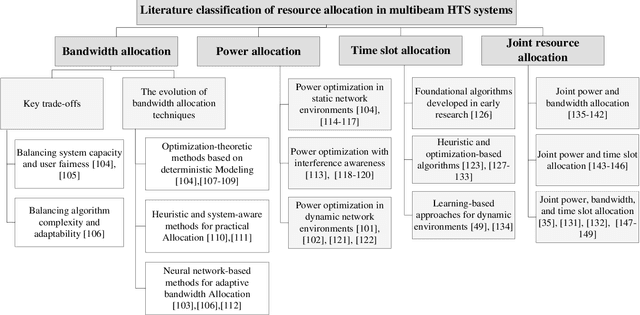
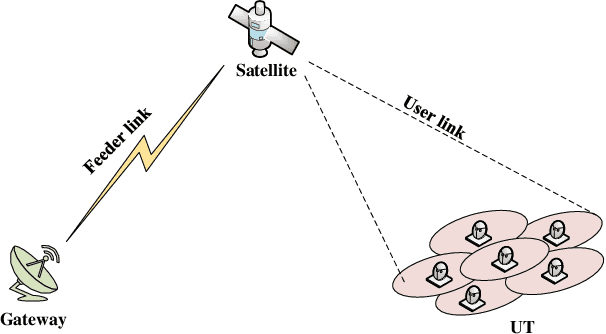
With its wide coverage and uninterrupted service, satellite communication is a critical technology for next-generation 6G communications. High throughput satellite (HTS) systems, utilizing multipoint beam and frequency multiplexing techniques, enable satellite communication capacity of up to Tbps to meet the growing traffic demand. Therefore, it is imperative to review the-state-of-the-art of multibeam HTS systems and identify their associated challenges and perspectives. Firstly, we summarize the multibeam HTS hardware foundations, including ground station systems, on-board payloads, and user terminals. Subsequently, we review the flexible on-board radio resource allocation approaches of bandwidth, power, time slot, and joint allocation schemes of HTS systems to optimize resource utilization and cater to non-uniform service demand. Additionally, we survey multibeam precoding methods for the HTS system to achieve full-frequency reuse and interference cancellation, which are classified according to different deployments such as single gateway precoding, multiple gateway precoding, on-board precoding, and hybrid on-board/on-ground precoding. Finally, we disscuss the challenges related to Q/V band link outage, time and frequency synchronization of gateways, the accuracy of channel state information (CSI), payload light-weight development, and the application of deep learning (DL). Research on these topics will contribute to enhancing the performance of HTS systems and finally delivering high-speed data to areas underserved by terrestrial networks.
Distilling Tool Knowledge into Language Models via Back-Translated Traces
Jun 23, 2025Large language models (LLMs) often struggle with mathematical problems that require exact computation or multi-step algebraic reasoning. Tool-integrated reasoning (TIR) offers a promising solution by leveraging external tools such as code interpreters to ensure correctness, but it introduces inference-time dependencies that hinder scalability and deployment. In this work, we propose a new paradigm for distilling tool knowledge into LLMs purely through natural language. We first construct a Solver Agent that solves math problems by interleaving planning, symbolic tool calls, and reflective reasoning. Then, using a back-translation pipeline powered by multiple LLM-based agents, we convert interleaved TIR traces into natural language reasoning traces. A Translator Agent generates explanations for individual tool calls, while a Rephrase Agent merges them into a fluent and globally coherent narrative. Empirically, we show that fine-tuning a small open-source model on these synthesized traces enables it to internalize both tool knowledge and structured reasoning patterns, yielding gains on competition-level math benchmarks without requiring tool access at inference.
Structured Labeling Enables Faster Vision-Language Models for End-to-End Autonomous Driving
Jun 05, 2025Vision-Language Models (VLMs) offer a promising approach to end-to-end autonomous driving due to their human-like reasoning capabilities. However, troublesome gaps remains between current VLMs and real-world autonomous driving applications. One major limitation is that existing datasets with loosely formatted language descriptions are not machine-friendly and may introduce redundancy. Additionally, high computational cost and massive scale of VLMs hinder the inference speed and real-world deployment. To bridge the gap, this paper introduces a structured and concise benchmark dataset, NuScenes-S, which is derived from the NuScenes dataset and contains machine-friendly structured representations. Moreover, we present FastDrive, a compact VLM baseline with 0.9B parameters. In contrast to existing VLMs with over 7B parameters and unstructured language processing(e.g., LLaVA-1.5), FastDrive understands structured and concise descriptions and generates machine-friendly driving decisions with high efficiency. Extensive experiments show that FastDrive achieves competitive performance on structured dataset, with approximately 20% accuracy improvement on decision-making tasks, while surpassing massive parameter baseline in inference speed with over 10x speedup. Additionally, ablation studies further focus on the impact of scene annotations (e.g., weather, time of day) on decision-making tasks, demonstrating their importance on decision-making tasks in autonomous driving.
Schema Generation for Large Knowledge Graphs Using Large Language Models
Jun 04, 2025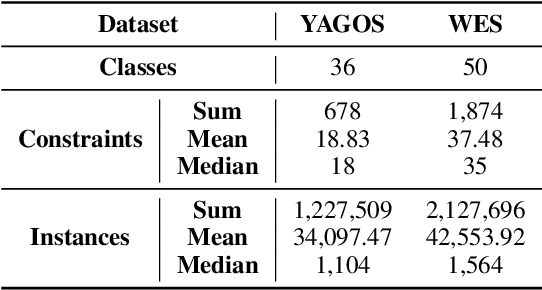
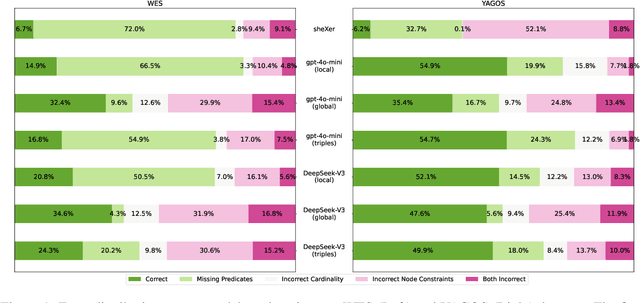
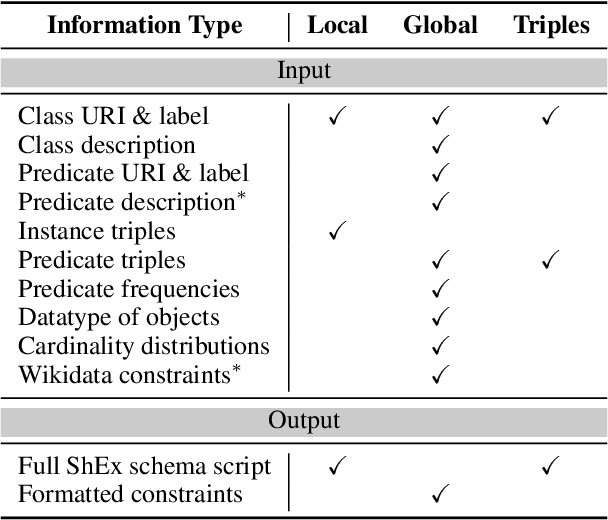

Schemas are vital for ensuring data quality in the Semantic Web and natural language processing. Traditionally, their creation demands substantial involvement from knowledge engineers and domain experts. Leveraging the impressive capabilities of large language models (LLMs) in related tasks like ontology engineering, we explore automatic schema generation using LLMs. To bridge the resource gap, we introduce two datasets: YAGO Schema and Wikidata EntitySchema, along with evaluation metrics. The LLM-based pipelines effectively utilize local and global information from knowledge graphs (KGs) to generate validating schemas in Shape Expressions (ShEx). Experiments demonstrate LLMs' strong potential in producing high-quality ShEx schemas, paving the way for scalable, automated schema generation for large KGs. Furthermore, our benchmark introduces a new challenge for structured generation, pushing the limits of LLMs on syntactically rich formalisms.
Predicate-Conditional Conformalized Answer Sets for Knowledge Graph Embeddings
May 22, 2025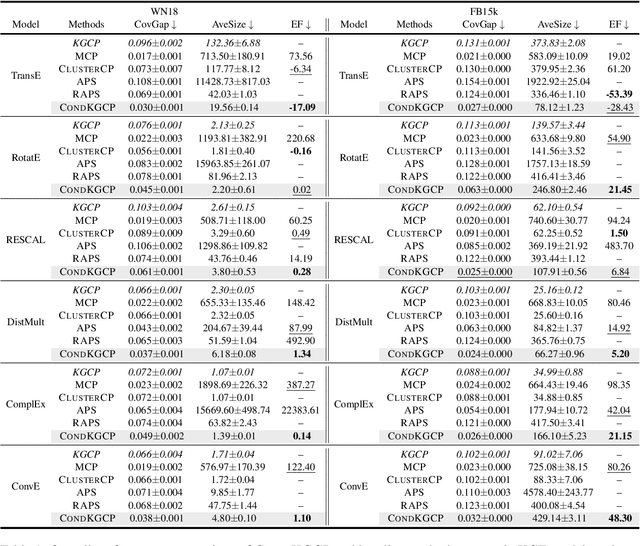
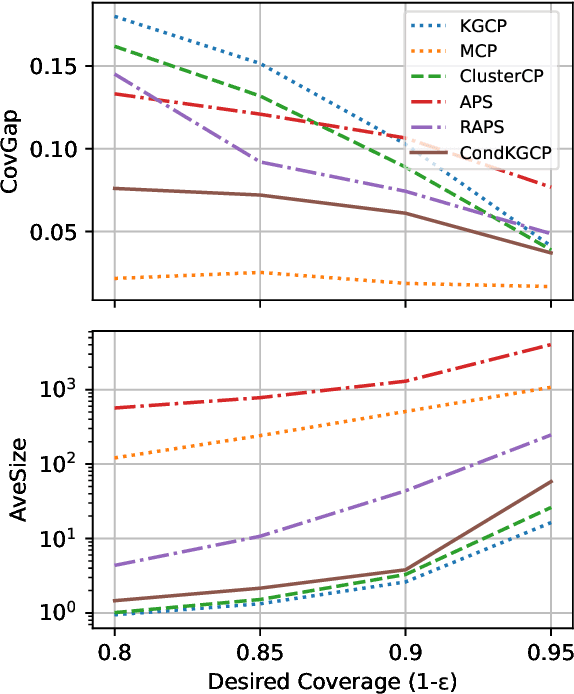
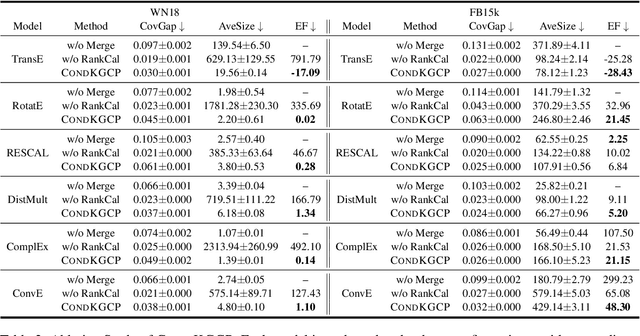
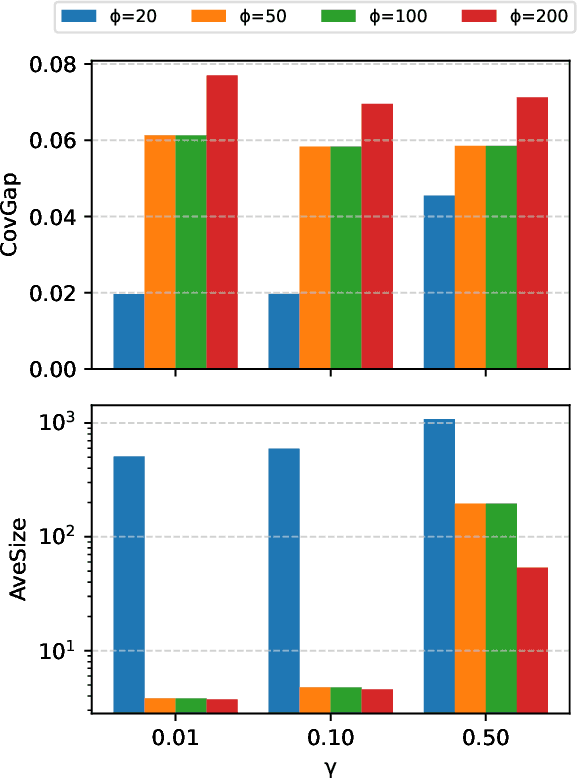
Uncertainty quantification in Knowledge Graph Embedding (KGE) methods is crucial for ensuring the reliability of downstream applications. A recent work applies conformal prediction to KGE methods, providing uncertainty estimates by generating a set of answers that is guaranteed to include the true answer with a predefined confidence level. However, existing methods provide probabilistic guarantees averaged over a reference set of queries and answers (marginal coverage guarantee). In high-stakes applications such as medical diagnosis, a stronger guarantee is often required: the predicted sets must provide consistent coverage per query (conditional coverage guarantee). We propose CondKGCP, a novel method that approximates predicate-conditional coverage guarantees while maintaining compact prediction sets. CondKGCP merges predicates with similar vector representations and augments calibration with rank information. We prove the theoretical guarantees and demonstrate empirical effectiveness of CondKGCP by comprehensive evaluations.
Evaluating Knowledge Graph Based Retrieval Augmented Generation Methods under Knowledge Incompleteness
Apr 07, 2025

Knowledge Graph based Retrieval-Augmented Generation (KG-RAG) is a technique that enhances Large Language Model (LLM) inference in tasks like Question Answering (QA) by retrieving relevant information from knowledge graphs (KGs). However, real-world KGs are often incomplete, meaning that essential information for answering questions may be missing. Existing benchmarks do not adequately capture the impact of KG incompleteness on KG-RAG performance. In this paper, we systematically evaluate KG-RAG methods under incomplete KGs by removing triples using different methods and analyzing the resulting effects. We demonstrate that KG-RAG methods are sensitive to KG incompleteness, highlighting the need for more robust approaches in realistic settings.
AIM: Acoustic Inertial Measurement for Indoor Drone Localization and Tracking
Apr 02, 2025

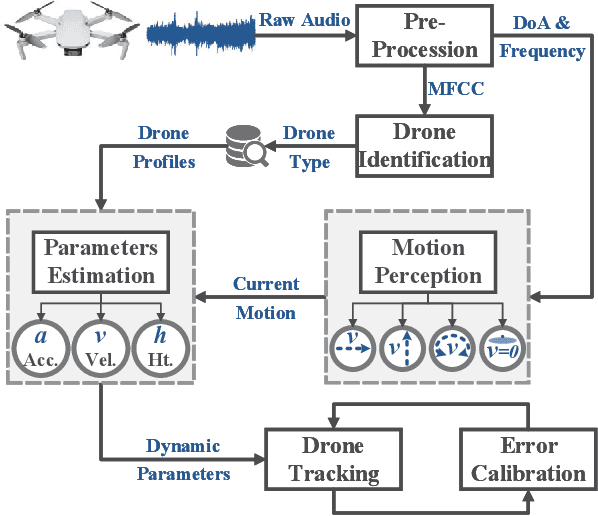
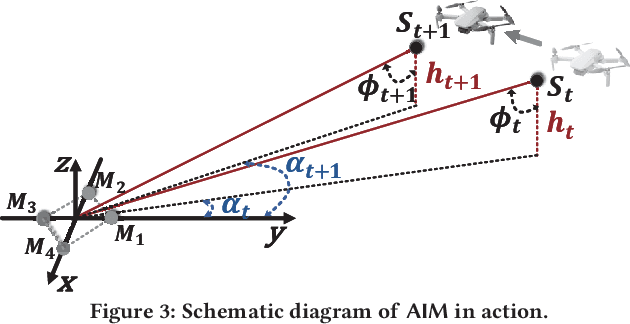
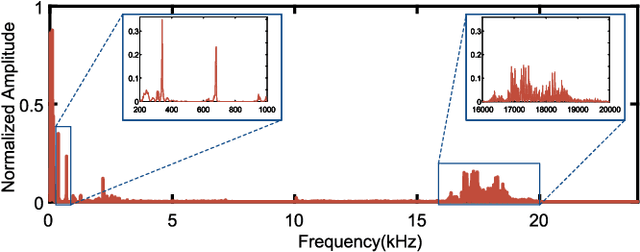
We present Acoustic Inertial Measurement (AIM), a one-of-a-kind technique for indoor drone localization and tracking. Indoor drone localization and tracking are arguably a crucial, yet unsolved challenge: in GPS-denied environments, existing approaches enjoy limited applicability, especially in Non-Line of Sight (NLoS), require extensive environment instrumentation, or demand considerable hardware/software changes on drones. In contrast, AIM exploits the acoustic characteristics of the drones to estimate their location and derive their motion, even in NLoS settings. We tame location estimation errors using a dedicated Kalman filter and the Interquartile Range rule (IQR). We implement AIM using an off-the-shelf microphone array and evaluate its performance with a commercial drone under varied settings. Results indicate that the mean localization error of AIM is 46% lower than commercial UWB-based systems in complex indoor scenarios, where state-of-the-art infrared systems would not even work because of NLoS settings. We further demonstrate that AIM can be extended to support indoor spaces with arbitrary ranges and layouts without loss of accuracy by deploying distributed microphone arrays.
Indoor Drone Localization and Tracking Based on Acoustic Inertial Measurement
Apr 01, 2025


We present Acoustic Inertial Measurement (AIM), a one-of-a-kind technique for indoor drone localization and tracking. Indoor drone localization and tracking are arguably a crucial, yet unsolved challenge: in GPS-denied environments, existing approaches enjoy limited applicability, especially in Non-Line of Sight (NLoS), require extensive environment instrumentation, or demand considerable hardware/software changes on drones. In contrast, AIM exploits the acoustic characteristics of the drones to estimate their location and derive their motion, even in NLoS settings. We tame location estimation errors using a dedicated Kalman filter and the Interquartile Range rule (IQR) and demonstrate that AIM can support indoor spaces with arbitrary ranges and layouts. We implement AIM using an off-the-shelf microphone array and evaluate its performance with a commercial drone under varied settings. Results indicate that the mean localization error of AIM is 46% lower than that of commercial UWB-based systems in a complex 10m\times10m indoor scenario, where state-of-the-art infrared systems would not even work because of NLoS situations. When distributed microphone arrays are deployed, the mean error can be reduced to less than 0.5m in a 20m range, and even support spaces with arbitrary ranges and layouts.