 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclic Refiner: Object-Aware Temporal Representation Learning for Multi-View 3D Detection and Tracking
Jul 03, 2024We propose a unified object-aware temporal learning framework for multi-view 3D detection and tracking tasks. Having observed that the efficacy of the temporal fusion strategy in recent multi-view perception methods may be weakened by distractors and background clutters in historical frames, we propose a cyclic learning mechanism to improve the robustness of multi-view representation learning. The essence is constructing a backward bridge to propagate information from model predictions (e.g., object locations and sizes) to image and BEV features, which forms a circle with regular inference. After backward refinement, the responses of target-irrelevant regions in historical frames would be suppressed, decreasing the risk of polluting future frames and improving the object awareness ability of temporal fusion. We further tailor an object-aware association strategy for tracking based on the cyclic learning model. The cyclic learning model not only provides refined features, but also delivers finer clues (e.g., scale level) for tracklet association. The proposed cycle learning method and association module together contribute a novel and unified multi-task framework. Experiments on nuScenes show that the proposed model achieves consistent performance gains over baselines of different designs (i.e., dense query-based BEVFormer, sparse query-based SparseBEV and LSS-based BEVDet4D) on both detection and tracking evaluation.
End-to-End Autonomous Driving without Costly Modularization and 3D Manual Annotation
Jun 25, 2024



We propose UAD, a method for vision-based end-to-end autonomous driving (E2EAD), achieving the best open-loop evaluation performance in nuScenes, meanwhile showing robust closed-loop driving quality in CARLA. Our motivation stems from the observation that current E2EAD models still mimic the modular architecture in typical driving stacks, with carefully designed supervised perception and prediction subtasks to provide environment information for oriented planning. Although achieving groundbreaking progress, such design has certain drawbacks: 1) preceding subtasks require massive high-quality 3D annotations as supervision, posing a significant impediment to scaling the training data; 2) each submodule entails substantial computation overhead in both training and inference. To this end, we propose UAD, an E2EAD framework with an unsupervised proxy to address all these issues. Firstly, we design a novel Angular Perception Pretext to eliminate the annotation requirement. The pretext models the driving scene by predicting the angular-wise spatial objectness and temporal dynamics, without manual annotation. Secondly, a self-supervised training strategy, which learns the consistency of the predicted trajectories under different augment views, is proposed to enhance the planning robustness in steering scenarios. Our UAD achieves 38.7% relative improvements over UniAD on the average collision rate in nuScenes and surpasses VAD for 41.32 points on the driving score in CARLA's Town05 Long benchmark. Moreover, the proposed method only consumes 44.3% training resources of UniAD and runs 3.4 times faster in inference. Our innovative design not only for the first time demonstrates unarguable performance advantages over supervised counterparts, but also enjoys unprecedented efficiency in data, training, and inference. Code and models will be released at https://github.com/KargoBot_Research/UAD.
Divert More Attention to Vision-Language Object Tracking
Jul 19, 2023Multimodal vision-language (VL) learning has noticeably pushed the tendency toward generic intelligence owing to emerging large foundation models. However, tracking, as a fundamental vision problem, surprisingly enjoys less bonus from recent flourishing VL learning. We argue that the reasons are two-fold: the lack of large-scale vision-language annotated videos and ineffective vision-language interaction learning of current works. These nuisances motivate us to design more effective vision-language representation for tracking, meanwhile constructing a large database with language annotation for model learning. Particularly, in this paper, we first propose a general attribute annotation strategy to decorate videos in six popular tracking benchmarks, which contributes a large-scale vision-language tracking database with more than 23,000 videos. We then introduce a novel framework to improve tracking by learning a unified-adaptive VL representation, where the cores are the proposed asymmetric architecture search and modality mixer (ModaMixer). To further improve VL representation, we introduce a contrastive loss to align different modalities. To thoroughly evidence the effectiveness of our method, we integrate the proposed framework on three tracking methods with different designs, i.e., the CNN-based SiamCAR, the Transformer-based OSTrack, and the hybrid structure TransT. The experiments demonstrate that our framework can significantly improve all baselines on six benchmarks. Besides empirical results, we theoretically analyze our approach to show its rationality. By revealing the potential of VL representation, we expect the community to divert more attention to VL tracking and hope to open more possibilities for future tracking with diversified multimodal messages.
Divert More Attention to Vision-Language Tracking
Jul 03, 2022

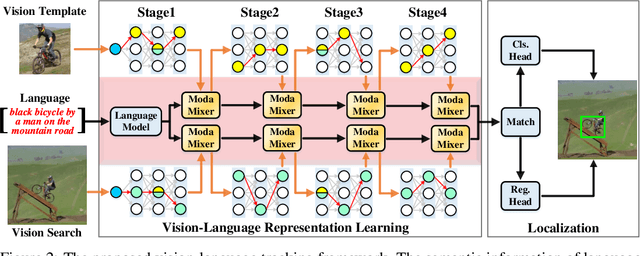

Relying on Transformer for complex visual feature learning, object tracking has witnessed the new standard for state-of-the-arts (SOTAs). However, this advancement accompanies by larger training data and longer training period, making tracking increasingly expensive. In this paper, we demonstrate that the Transformer-reliance is not necessary and the pure ConvNets are still competitive and even better yet more economical and friendly in achieving SOTA tracking. Our solution is to unleash the power of multimodal vision-language (VL) tracking, simply using ConvNets. The essence lies in learning novel unified-adaptive VL representations with our modality mixer (ModaMixer) and asymmetrical ConvNet search. We show that our unified-adaptive VL representation, learned purely with the ConvNets, is a simple yet strong alternative to Transformer visual features, by unbelievably improving a CNN-based Siamese tracker by 14.5% in SUC on challenging LaSOT (50.7% > 65.2%), even outperforming several Transformer-based SOTA trackers. Besides empirical results, we theoretically analyze our approach to evidence its effectiveness. By revealing the potential of VL representation, we expect the community to divert more attention to VL tracking and hope to open more possibilities for future tracking beyond Transformer. Code and models will be released at https://github.com/JudasDie/SOTS.
Learning Target-aware Representation for Visual Tracking via Informative Interactions
Jan 07, 2022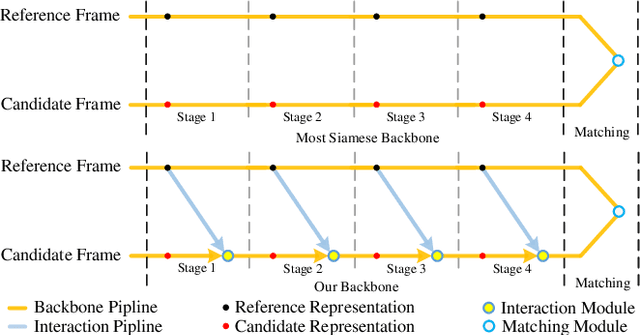
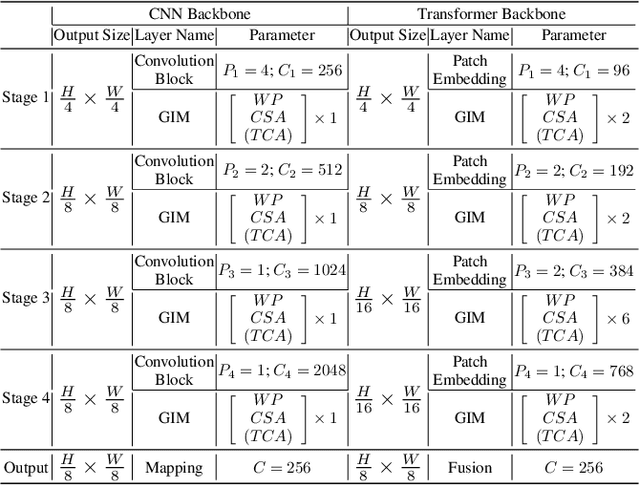
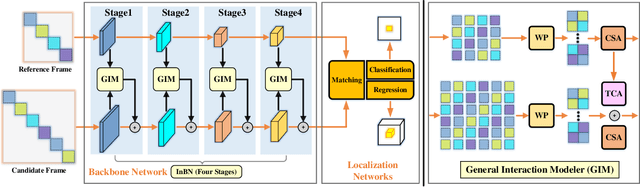
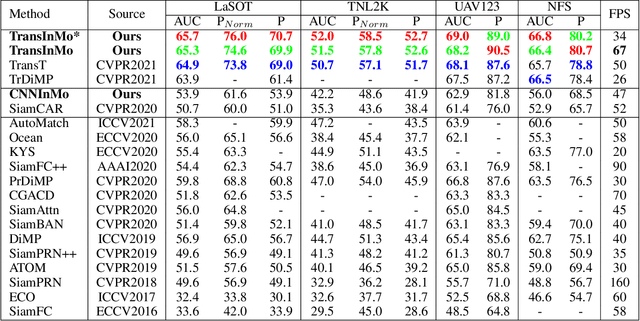
We introduce a novel backbone architecture to improve target-perception ability of feature representation for tracking. Specifically, having observed that de facto frameworks perform feature matching simply using the outputs from backbone for target localization, there is no direct feedback from the matching module to the backbone network, especially the shallow layers. More concretely, only the matching module can directly access the target information (in the reference frame), while the representation learning of candidate frame is blind to the reference target. As a consequence, the accumulation effect of target-irrelevant interference in the shallow stages may degrade the feature quality of deeper layers. In this paper, we approach the problem from a different angle by conducting multiple branch-wise interactions inside the Siamese-like backbone networks (InBN). At the core of InBN is a general interaction modeler (GIM) that injects the prior knowledge of reference image to different stages of the backbone network, leading to better target-perception and robust distractor-resistance of candidate feature representation with negligible computation cost. The proposed GIM module and InBN mechanism are general and applicable to different backbone types including CNN and Transformer for improvements, as evidenced by our extensive experiments on multiple benchmarks. In particular, the CNN version (based on SiamCAR) improves the baseline with 3.2/6.9 absolute gains of SUC on LaSOT/TNL2K, respectively. The Transformer version obtains SUC scores of 65.7/52.0 on LaSOT/TNL2K, which are on par with recent state of the arts. Code and models will be released.