 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Digital Twins of Different Human Organs for Personalized Healthcare
Jan 16, 2026Digital twins are virtual replicas of physical entities and are poised to transform personalized medicine through the real-time simulation and prediction of human physiology. Translating this paradigm from engineering to biomedicine requires overcoming profound challenges, including anatomical variability, multi-scale biological processes, and the integration of multi-physics phenomena. This survey systematically reviews methodologies for building digital twins of human organs, structured around a pipeline decoupled into anatomical twinning (capturing patient-specific geometry and structure) and functional twinning (simulating multi-scale physiology from cellular to organ-level function). We categorize approaches both by organ-specific properties and by technical paradigm, with particular emphasis on multi-scale and multi-physics integration. A key focus is the role of artificial intelligence (AI), especially physics-informed AI, in enhancing model fidelity, scalability, and personalization. Furthermore, we discuss the critical challenges of clinical validation and translational pathways. This study not only charts a roadmap for overcoming current bottlenecks in single-organ twins but also outlines the promising, albeit ambitious, future of interconnected multi-organ digital twins for whole-body precision healthcare.
Continual Gradient Low-Rank Projection Fine-Tuning for LLMs
Jul 03, 2025
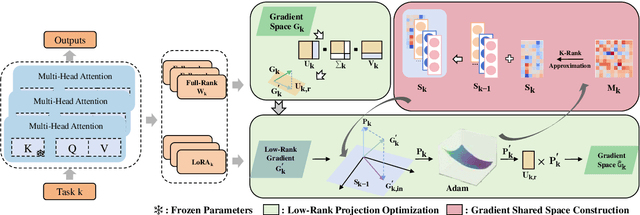
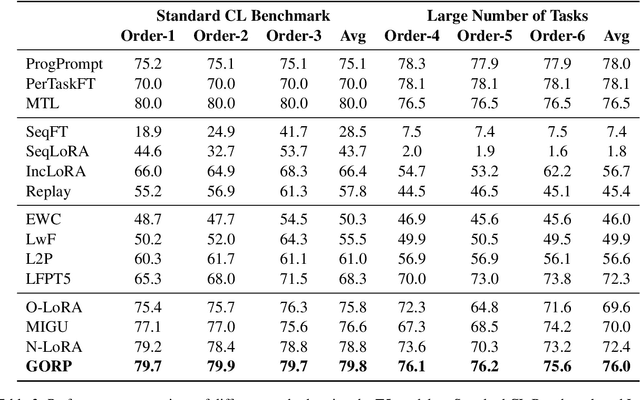
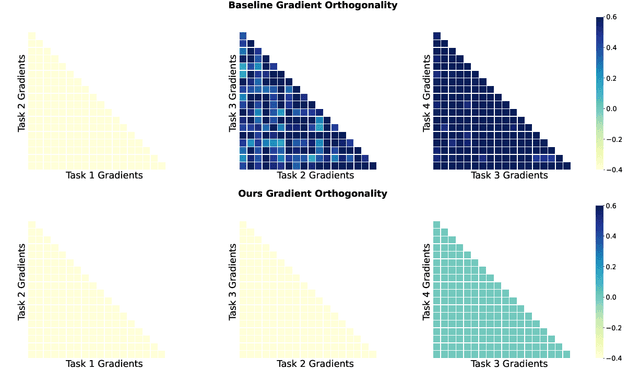
Continual fine-tuning of Large Language Models (LLMs) is hampered by the trade-off between efficiency and expressiveness. Low-Rank Adaptation (LoRA) offers efficiency but constrains the model's ability to learn new tasks and transfer knowledge due to its low-rank nature and reliance on explicit parameter constraints. We propose GORP (Gradient LOw Rank Projection) for Continual Learning, a novel training strategy that overcomes these limitations by synergistically combining full and low-rank parameters and jointly updating within a unified low-rank gradient subspace. GORP expands the optimization space while preserving efficiency and mitigating catastrophic forgetting. Extensive experiments on continual learning benchmarks demonstrate GORP's superior performance compared to existing state-of-the-art approaches. Code is available at https://github.com/Wcxwcxw/GORP.
Personalized Topology-Informed 12-Lead ECG Electrode Localization from Incomplete Cardiac MRIs for Efficient Cardiac Digital Twins
Aug 25, 2024Cardiac digital twins (CDTs) offer personalized \textit{in-silico} cardiac representations for the inference of multi-scale properties tied to cardiac mechanisms. The creation of CDTs requires precise information about the electrode position on the torso, especially for the personalized electrocardiogram (ECG) calibration. However, current studies commonly rely on additional acquisition of torso imaging and manual/semi-automatic methods for ECG electrode localization. In this study, we propose a novel and efficient topology-informed model to fully automatically extract personalized ECG electrode locations from 2D clinically standard cardiac MRIs. Specifically, we obtain the sparse torso contours from the cardiac MRIs and then localize the electrodes from the contours. Cardiac MRIs aim at imaging of the heart instead of the torso, leading to incomplete torso geometry within the imaging. To tackle the missing topology, we incorporate the electrodes as a subset of the keypoints, which can be explicitly aligned with the 3D torso topology. The experimental results demonstrate that the proposed model outperforms the time-consuming conventional method in terms of accuracy (Euclidean distance: $1.24 \pm 0.293$ cm vs. $1.48 \pm 0.362$ cm) and efficiency ($2$~s vs. $30$-$35$~min). We further demonstrate the effectiveness of using the detected electrodes for \textit{in-silico} ECG simulation, highlighting their potential for creating accurate and efficient CDT models. The code will be released publicly after the manuscript is accepted for publication.
Overcoming Recency Bias of Normalization Statistics in Continual Learning: Balance and Adaptation
Oct 13, 2023Continual learning entails learning a sequence of tasks and balancing their knowledge appropriately. With limited access to old training samples, much of the current work in deep neural networks has focused on overcoming catastrophic forgetting of old tasks in gradient-based optimization. However, the normalization layers provide an exception, as they are updated interdependently by the gradient and statistics of currently observed training samples, which require specialized strategies to mitigate recency bias. In this work, we focus on the most popular Batch Normalization (BN) and provide an in-depth theoretical analysis of its sub-optimality in continual learning. Our analysis demonstrates the dilemma between balance and adaptation of BN statistics for incremental tasks, which potentially affects training stability and generalization. Targeting on these particular challenges, we propose Adaptive Balance of BN (AdaB$^2$N), which incorporates appropriately a Bayesian-based strategy to adapt task-wise contributions and a modified momentum to balance BN statistics, corresponding to the training and testing stages. By implementing BN in a continual learning fashion, our approach achieves significant performance gains across a wide range of benchmarks, particularly for the challenging yet realistic online scenarios (e.g., up to 7.68%, 6.86% and 4.26% on Split CIFAR-10, Split CIFAR-100 and Split Mini-ImageNet, respectively). Our code is available at https://github.com/lvyilin/AdaB2N.
Recognizable Information Bottleneck
Apr 28, 2023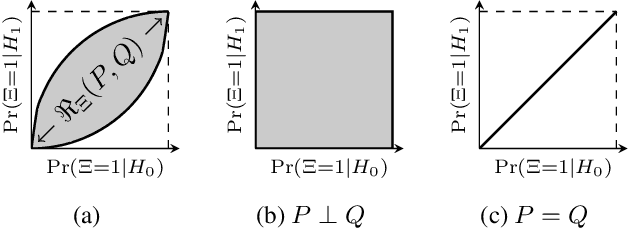
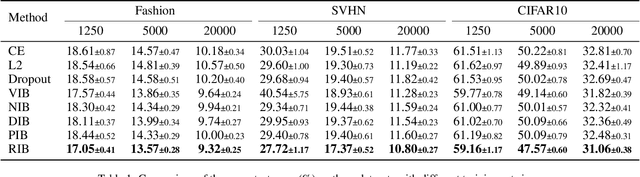
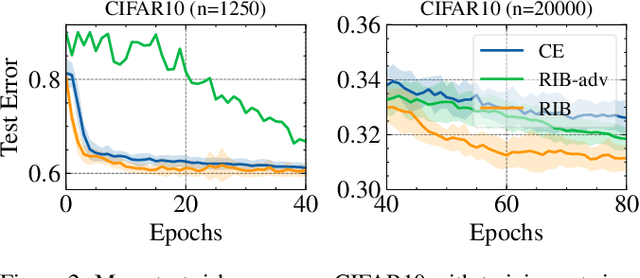

Information Bottlenecks (IBs) learn representations that generalize to unseen data by information compression. However, existing IBs are practically unable to guarantee generalization in real-world scenarios due to the vacuous generalization bound. The recent PAC-Bayes IB uses information complexity instead of information compression to establish a connection with the mutual information generalization bound. However, it requires the computation of expensive second-order curvature, which hinders its practical application. In this paper, we establish the connection between the recognizability of representations and the recent functional conditional mutual information (f-CMI) generalization bound, which is significantly easier to estimate. On this basis we propose a Recognizable Information Bottleneck (RIB) which regularizes the recognizability of representations through a recognizability critic optimized by density ratio matching under the Bregman divergence. Extensive experiments on several commonly used datasets demonstrate the effectiveness of the proposed method in regularizing the model and estimating the generalization gap.
Learning Target-aware Representation for Visual Tracking via Informative Interactions
Jan 07, 2022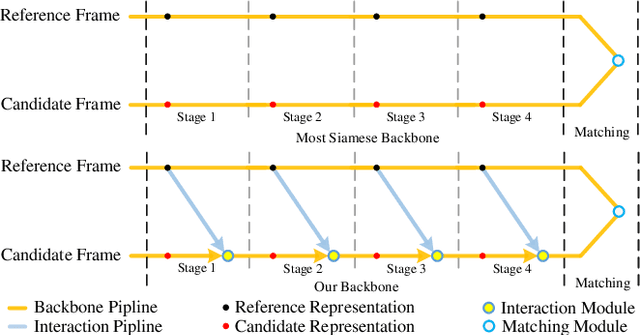
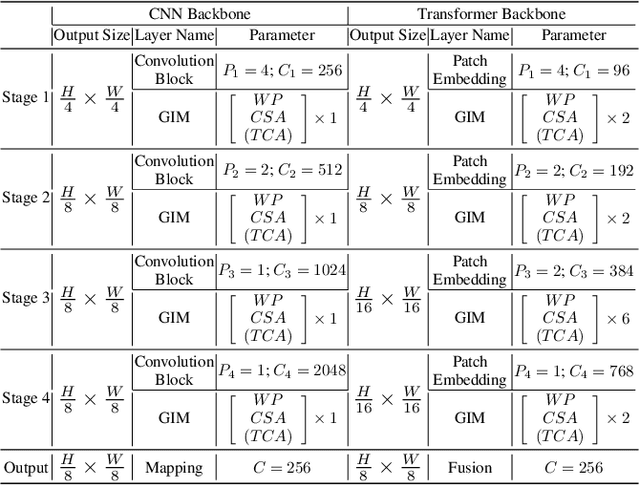
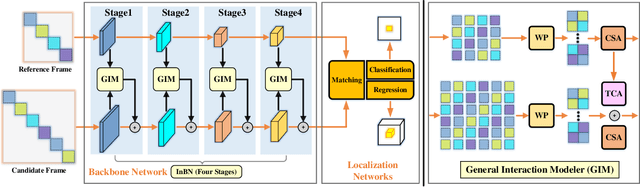
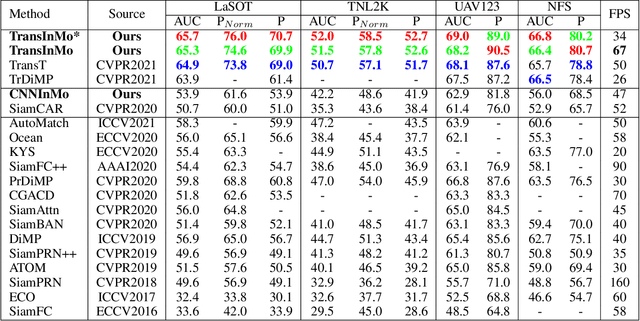
We introduce a novel backbone architecture to improve target-perception ability of feature representation for tracking. Specifically, having observed that de facto frameworks perform feature matching simply using the outputs from backbone for target localization, there is no direct feedback from the matching module to the backbone network, especially the shallow layers. More concretely, only the matching module can directly access the target information (in the reference frame), while the representation learning of candidate frame is blind to the reference target. As a consequence, the accumulation effect of target-irrelevant interference in the shallow stages may degrade the feature quality of deeper layers. In this paper, we approach the problem from a different angle by conducting multiple branch-wise interactions inside the Siamese-like backbone networks (InBN). At the core of InBN is a general interaction modeler (GIM) that injects the prior knowledge of reference image to different stages of the backbone network, leading to better target-perception and robust distractor-resistance of candidate feature representation with negligible computation cost. The proposed GIM module and InBN mechanism are general and applicable to different backbone types including CNN and Transformer for improvements, as evidenced by our extensive experiments on multiple benchmarks. In particular, the CNN version (based on SiamCAR) improves the baseline with 3.2/6.9 absolute gains of SUC on LaSOT/TNL2K, respectively. The Transformer version obtains SUC scores of 65.7/52.0 on LaSOT/TNL2K, which are on par with recent state of the arts. Code and models will be released.