 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Target-aware Representation for Visual Tracking via Informative Interactions
Paper and Code
Jan 07, 2022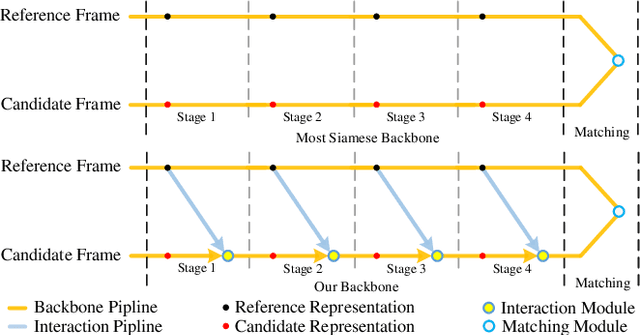
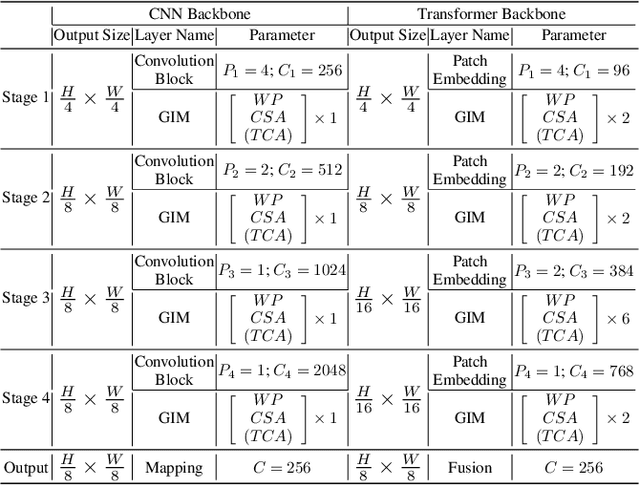
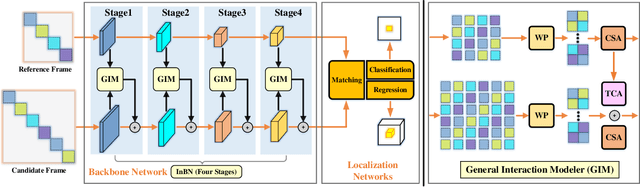
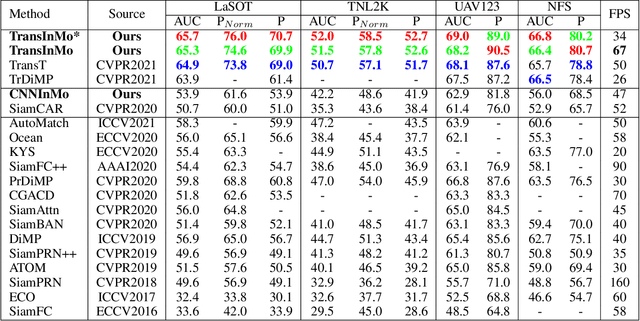
We introduce a novel backbone architecture to improve target-perception ability of feature representation for tracking. Specifically, having observed that de facto frameworks perform feature matching simply using the outputs from backbone for target localization, there is no direct feedback from the matching module to the backbone network, especially the shallow layers. More concretely, only the matching module can directly access the target information (in the reference frame), while the representation learning of candidate frame is blind to the reference target. As a consequence, the accumulation effect of target-irrelevant interference in the shallow stages may degrade the feature quality of deeper layers. In this paper, we approach the problem from a different angle by conducting multiple branch-wise interactions inside the Siamese-like backbone networks (InBN). At the core of InBN is a general interaction modeler (GIM) that injects the prior knowledge of reference image to different stages of the backbone network, leading to better target-perception and robust distractor-resistance of candidate feature representation with negligible computation cost. The proposed GIM module and InBN mechanism are general and applicable to different backbone types including CNN and Transformer for improvements, as evidenced by our extensive experiments on multiple benchmarks. In particular, the CNN version (based on SiamCAR) improves the baseline with 3.2/6.9 absolute gains of SUC on LaSOT/TNL2K, respectively. The Transformer version obtains SUC scores of 65.7/52.0 on LaSOT/TNL2K, which are on par with recent state of the arts. Code and models will be released.