 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Semantic Augmentation for Enhancing Open-Vocabulary Object Detection
Apr 06, 2026Open-vocabulary object detection (OVOD) enables models to detect any object category, including unseen ones. Benefiting from large-scale pre-training, existing OVOD methods achieve strong detection performance on general scenarios (e.g., OV-COCO) but suffer severe performance drops when transferred to downstream tasks with substantial domain shifts. This degradation stems from the scarcity and weak semantics of category labels in domain-specific task, as well as the inability of existing models to capture auxiliary semantics beyond coarse-grained category label. To address these issues, we propose HSA-DINO, a parameter-efficient semantic augmentation framework for enhancing open-vocabulary object detection. Specifically, we propose a multi-scale prompt bank that leverages image feature pyramids to capture hierarchical semantics and select domain-specific local semantic prompts, progressively enriching textual representations from coarse to fine-grained levels. Furthermore, we introduce a semantic-aware router that dynamically selects the appropriate semantic augmentation strategy during inference, thereby preventing parameter updates from degrading the generalization ability of the pre-trained OVOD model. We evaluate HSA-DINO on OV-COCO, several vertical domain datasets, and modified benchmark settings. The results show that HSA-DINO performs favorably against previous state-of-the-art methods, achieving a superior trade-off between domain adaptability and open-vocabulary generalization.
Detecting Misbehaviors of Large Vision-Language Models by Evidential Uncertainty Quantification
Feb 05, 2026Large vision-language models (LVLMs) have shown substantial advances in multimodal understanding and generation. However, when presented with incompetent or adversarial inputs, they frequently produce unreliable or even harmful content, such as fact hallucinations or dangerous instructions. This misalignment with human expectations, referred to as \emph{misbehaviors} of LVLMs, raises serious concerns for deployment in critical applications. These misbehaviors are found to stem from epistemic uncertainty, specifically either conflicting internal knowledge or the absence of supporting information. However, existing uncertainty quantification methods, which typically capture only overall epistemic uncertainty, have shown limited effectiveness in identifying such issues. To address this gap, we propose Evidential Uncertainty Quantification (EUQ), a fine-grained method that captures both information conflict and ignorance for effective detection of LVLM misbehaviors. In particular, we interpret features from the model output head as either supporting (positive) or opposing (negative) evidence. Leveraging Evidence Theory, we model and aggregate this evidence to quantify internal conflict and knowledge gaps within a single forward pass. We extensively evaluate our method across four categories of misbehavior, including hallucinations, jailbreaks, adversarial vulnerabilities, and out-of-distribution (OOD) failures, using state-of-the-art LVLMs, and find that EUQ consistently outperforms strong baselines, showing that hallucinations correspond to high internal conflict and OOD failures to high ignorance. Furthermore, layer-wise evidential uncertainty dynamics analysis helps interpret the evolution of internal representations from a new perspective. The source code is available at https://github.com/HT86159/EUQ.
Learning Neural Operators from Partial Observations via Latent Autoregressive Modeling
Jan 27, 2026Real-world scientific applications frequently encounter incomplete observational data due to sensor limitations, geographic constraints, or measurement costs. Although neural operators significantly advanced PDE solving in terms of computational efficiency and accuracy, their underlying assumption of fully-observed spatial inputs severely restricts applicability in real-world applications. We introduce the first systematic framework for learning neural operators from partial observation. We identify and formalize two fundamental obstacles: (i) the supervision gap in unobserved regions that prevents effective learning of physical correlations, and (ii) the dynamic spatial mismatch between incomplete inputs and complete solution fields. Specifically, our proposed Latent Autoregressive Neural Operator(LANO) introduces two novel components designed explicitly to address the core difficulties of partial observations: (i) a mask-to-predict training strategy that creates artificial supervision by strategically masking observed regions, and (ii) a Physics-Aware Latent Propagator that reconstructs solutions through boundary-first autoregressive generation in latent space. Additionally, we develop POBench-PDE, a dedicated and comprehensive benchmark designed specifically for evaluating neural operators under partial observation conditions across three PDE-governed tasks. LANO achieves state-of-the-art performance with 18--69$\%$ relative L2 error reduction across all benchmarks under patch-wise missingness with less than 50$\%$ missing rate, including real-world climate prediction. Our approach effectively addresses practical scenarios involving up to 75$\%$ missing rate, to some extent bridging the existing gap between idealized research settings and the complexities of real-world scientific computing.
SAM Encoder Breach by Adversarial Simplicial Complex Triggers Downstream Model Failures
Aug 08, 2025While the Segment Anything Model (SAM) transforms interactive segmentation with zero-shot abilities, its inherent vulnerabilities present a single-point risk, potentially leading to the failure of numerous downstream applications. Proactively evaluating these transferable vulnerabilities is thus imperative. Prior adversarial attacks on SAM often present limited transferability due to insufficient exploration of common weakness across domains. To address this, we propose Vertex-Refining Simplicial Complex Attack (VeSCA), a novel method that leverages only the encoder of SAM for generating transferable adversarial examples. Specifically, it achieves this by explicitly characterizing the shared vulnerable regions between SAM and downstream models through a parametric simplicial complex. Our goal is to identify such complexes within adversarially potent regions by iterative vertex-wise refinement. A lightweight domain re-adaptation strategy is introduced to bridge domain divergence using minimal reference data during the initialization of simplicial complex. Ultimately, VeSCA generates consistently transferable adversarial examples through random simplicial complex sampling. Extensive experiments demonstrate that VeSCA achieves performance improved by 12.7% compared to state-of-the-art methods across three downstream model categories across five domain-specific datasets. Our findings further highlight the downstream model risks posed by SAM's vulnerabilities and emphasize the urgency of developing more robust foundation models.
Reframe Your Life Story: Interactive Narrative Therapist and Innovative Moment Assessment with Large Language Models
Jul 27, 2025



Recent progress in large language models (LLMs) has opened new possibilities for mental health support, yet current approaches lack realism in simulating specialized psychotherapy and fail to capture therapeutic progression over time. Narrative therapy, which helps individuals transform problematic life stories into empowering alternatives, remains underutilized due to limited access and social stigma. We address these limitations through a comprehensive framework with two core components. First, INT (Interactive Narrative Therapist) simulates expert narrative therapists by planning therapeutic stages, guiding reflection levels, and generating contextually appropriate expert-like responses. Second, IMA (Innovative Moment Assessment) provides a therapy-centric evaluation method that quantifies effectiveness by tracking "Innovative Moments" (IMs), critical narrative shifts in client speech signaling therapy progress. Experimental results on 260 simulated clients and 230 human participants reveal that INT consistently outperforms standard LLMs in therapeutic quality and depth. We further demonstrate the effectiveness of INT in synthesizing high-quality support conversations to facilitate social applications.
Continual Gradient Low-Rank Projection Fine-Tuning for LLMs
Jul 03, 2025
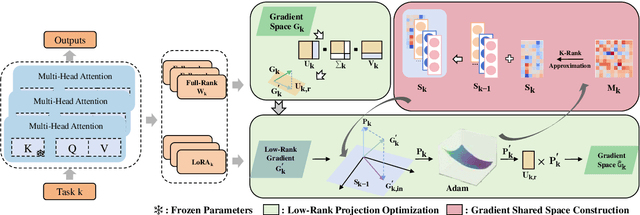
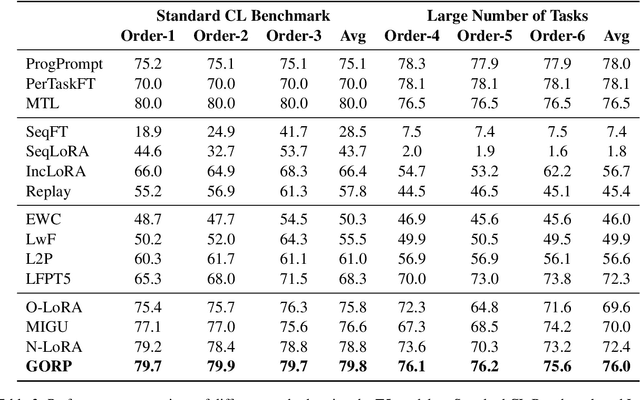
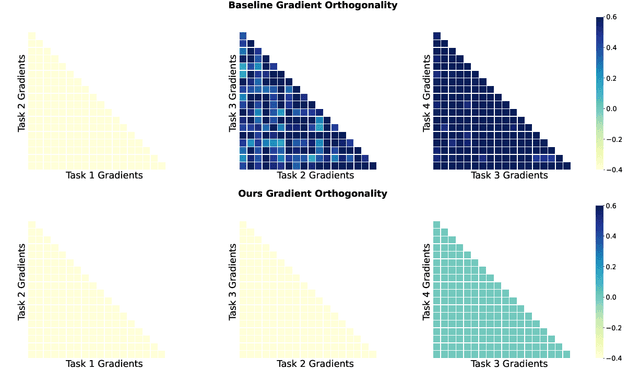
Continual fine-tuning of Large Language Models (LLMs) is hampered by the trade-off between efficiency and expressiveness. Low-Rank Adaptation (LoRA) offers efficiency but constrains the model's ability to learn new tasks and transfer knowledge due to its low-rank nature and reliance on explicit parameter constraints. We propose GORP (Gradient LOw Rank Projection) for Continual Learning, a novel training strategy that overcomes these limitations by synergistically combining full and low-rank parameters and jointly updating within a unified low-rank gradient subspace. GORP expands the optimization space while preserving efficiency and mitigating catastrophic forgetting. Extensive experiments on continual learning benchmarks demonstrate GORP's superior performance compared to existing state-of-the-art approaches. Code is available at https://github.com/Wcxwcxw/GORP.
Visual hallucination detection in large vision-language models via evidential conflict
Jun 24, 2025Despite the remarkable multimodal capabilities of Large Vision-Language Models (LVLMs), discrepancies often occur between visual inputs and textual outputs--a phenomenon we term visual hallucination. This critical reliability gap poses substantial risks in safety-critical Artificial Intelligence (AI) applications, necessitating a comprehensive evaluation benchmark and effective detection methods. Firstly, we observe that existing visual-centric hallucination benchmarks mainly assess LVLMs from a perception perspective, overlooking hallucinations arising from advanced reasoning capabilities. We develop the Perception-Reasoning Evaluation Hallucination (PRE-HAL) dataset, which enables the systematic evaluation of both perception and reasoning capabilities of LVLMs across multiple visual semantics, such as instances, scenes, and relations. Comprehensive evaluation with this new benchmark exposed more visual vulnerabilities, particularly in the more challenging task of relation reasoning. To address this issue, we propose, to the best of our knowledge, the first Dempster-Shafer theory (DST)-based visual hallucination detection method for LVLMs through uncertainty estimation. This method aims to efficiently capture the degree of conflict in high-level features at the model inference phase. Specifically, our approach employs simple mass functions to mitigate the computational complexity of evidence combination on power sets. We conduct an extensive evaluation of state-of-the-art LVLMs, LLaVA-v1.5, mPLUG-Owl2 and mPLUG-Owl3, with the new PRE-HAL benchmark. Experimental results indicate that our method outperforms five baseline uncertainty metrics, achieving average AUROC improvements of 4%, 10%, and 7% across three LVLMs. Our code is available at https://github.com/HT86159/Evidential-Conflict.
Beyond 2:4: exploring V:N:M sparsity for efficient transformer inference on GPUs
Oct 21, 2024



To date, 2:4 sparsity has stood as the only sparse pattern that can be accelerated using sparse tensor cores on GPUs. In practice, 2:4 sparsity often possesses low actual speedups ($\leq 1.3$) and requires fixed sparse ratios, meaning that other ratios, such as 4:8, 8:16, or those exceeding 50% sparsity, do not incur any speedups on GPUs. Recent studies suggest that V:N:M sparsity is promising in addressing these limitations of 2:4 sparsity. However, regarding accuracy, the effects of V:N:M sparsity on broader Transformer models, such as vision Transformers and large language models (LLMs), are largely unexamined. Moreover, Some specific issues related to V:N:M sparsity, such as how to select appropriate V and M values, remain unresolved. In this study, we thoroughly investigate the application of V:N:M sparsity in vision models and LLMs across multiple tasks, from pertaining to downstream tasks. We propose three key approaches to enhance the applicability and accuracy of V:N:M-sparse Transformers, including heuristic V and M selection, V:N:M-specific channel permutation, and three-staged LoRA training techniques. Experimental results show that, with our methods, the DeiT-small achieves lossless accuracy at 64:2:5 sparsity, while the DeiT-base maintains accuracy even at 64:2:8 sparsity. In addition, the fine-tuned LLama2-7B at 64:2:5 sparsity performs comparably or better than training-free 2:4 sparse alternatives on downstream tasks. More importantly, V:N:M-sparse Transformers offer a wider range of speedup-accuracy trade-offs compared to 2:4 sparsity. Overall, our exploration largely facilitates the V:N:M sparsity to act as a truly effective acceleration solution for Transformers in cost-sensitive inference scenarios.
1-Bit FQT: Pushing the Limit of Fully Quantized Training to 1-bit
Aug 26, 2024



Fully quantized training (FQT) accelerates the training of deep neural networks by quantizing the activations, weights, and gradients into lower precision. To explore the ultimate limit of FQT (the lowest achievable precision), we make a first attempt to 1-bit FQT. We provide a theoretical analysis of FQT based on Adam and SGD, revealing that the gradient variance influences the convergence of FQT. Building on these theoretical results, we introduce an Activation Gradient Pruning (AGP) strategy. The strategy leverages the heterogeneity of gradients by pruning less informative gradients and enhancing the numerical precision of remaining gradients to mitigate gradient variance. Additionally, we propose Sample Channel joint Quantization (SCQ), which utilizes different quantization strategies in the computation of weight gradients and activation gradients to ensure that the method is friendly to low-bitwidth hardware. Finally, we present a framework to deploy our algorithm. For fine-tuning VGGNet-16 and ResNet-18 on multiple datasets, our algorithm achieves an average accuracy improvement of approximately 6%, compared to per-sample quantization. Moreover, our training speedup can reach a maximum of 5.13x compared to full precision training.
Cyclic Refiner: Object-Aware Temporal Representation Learning for Multi-View 3D Detection and Tracking
Jul 03, 2024We propose a unified object-aware temporal learning framework for multi-view 3D detection and tracking tasks. Having observed that the efficacy of the temporal fusion strategy in recent multi-view perception methods may be weakened by distractors and background clutters in historical frames, we propose a cyclic learning mechanism to improve the robustness of multi-view representation learning. The essence is constructing a backward bridge to propagate information from model predictions (e.g., object locations and sizes) to image and BEV features, which forms a circle with regular inference. After backward refinement, the responses of target-irrelevant regions in historical frames would be suppressed, decreasing the risk of polluting future frames and improving the object awareness ability of temporal fusion. We further tailor an object-aware association strategy for tracking based on the cyclic learning model. The cyclic learning model not only provides refined features, but also delivers finer clues (e.g., scale level) for tracklet association. The proposed cycle learning method and association module together contribute a novel and unified multi-task framework. Experiments on nuScenes show that the proposed model achieves consistent performance gains over baselines of different designs (i.e., dense query-based BEVFormer, sparse query-based SparseBEV and LSS-based BEVDet4D) on both detection and tracking evaluation.