 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAC: Kolmogorov-Arnold Classifier for Continual Learning
Mar 27, 2025



Continual learning requires models to train continuously across consecutive tasks without forgetting. Most existing methods utilize linear classifiers, which struggle to maintain a stable classification space while learning new tasks. Inspired by the success of Kolmogorov-Arnold Networks (KAN) in preserving learning stability during simple continual regression tasks, we set out to explore their potential in more complex continual learning scenarios. In this paper, we introduce the Kolmogorov-Arnold Classifier (KAC), a novel classifier developed for continual learning based on the KAN structure. We delve into the impact of KAN's spline functions and introduce Radial Basis Functions (RBF) for improved compatibility with continual learning. We replace linear classifiers with KAC in several recent approaches and conduct experiments across various continual learning benchmarks, all of which demonstrate performance improvements, highlighting the effectiveness and robustness of KAC in continual learning. The code is available at https://github.com/Ethanhuhuhu/KAC.
Beyond 2:4: exploring V:N:M sparsity for efficient transformer inference on GPUs
Oct 21, 2024



To date, 2:4 sparsity has stood as the only sparse pattern that can be accelerated using sparse tensor cores on GPUs. In practice, 2:4 sparsity often possesses low actual speedups ($\leq 1.3$) and requires fixed sparse ratios, meaning that other ratios, such as 4:8, 8:16, or those exceeding 50% sparsity, do not incur any speedups on GPUs. Recent studies suggest that V:N:M sparsity is promising in addressing these limitations of 2:4 sparsity. However, regarding accuracy, the effects of V:N:M sparsity on broader Transformer models, such as vision Transformers and large language models (LLMs), are largely unexamined. Moreover, Some specific issues related to V:N:M sparsity, such as how to select appropriate V and M values, remain unresolved. In this study, we thoroughly investigate the application of V:N:M sparsity in vision models and LLMs across multiple tasks, from pertaining to downstream tasks. We propose three key approaches to enhance the applicability and accuracy of V:N:M-sparse Transformers, including heuristic V and M selection, V:N:M-specific channel permutation, and three-staged LoRA training techniques. Experimental results show that, with our methods, the DeiT-small achieves lossless accuracy at 64:2:5 sparsity, while the DeiT-base maintains accuracy even at 64:2:8 sparsity. In addition, the fine-tuned LLama2-7B at 64:2:5 sparsity performs comparably or better than training-free 2:4 sparse alternatives on downstream tasks. More importantly, V:N:M-sparse Transformers offer a wider range of speedup-accuracy trade-offs compared to 2:4 sparsity. Overall, our exploration largely facilitates the V:N:M sparsity to act as a truly effective acceleration solution for Transformers in cost-sensitive inference scenarios.
Event-based Robotic Grasping Detection with Neuromorphic Vision Sensor and Event-Stream Dataset
May 01, 2020
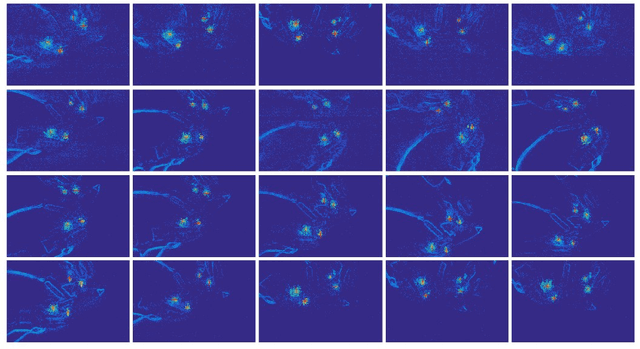

Robotic grasping plays an important role in the field of robotics. The current state-of-the-art robotic grasping detection systems are usually built on the conventional vision, such as RGB-D camera. Compared to traditional frame-based computer vision, neuromorphic vision is a small and young community of research. Currently, there are limited event-based datasets due to the troublesome annotation of the asynchronous event stream. Annotating large scale vision dataset often takes lots of computation resources, especially the troublesome data for video-level annotation. In this work, we consider the problem of detecting robotic grasps in a moving camera view of a scene containing objects. To obtain more agile robotic perception, a neuromorphic vision sensor (DAVIS) attaching to the robot gripper is introduced to explore the potential usage in grasping detection. We construct a robotic grasping dataset named Event-Stream Dataset with 91 objects. A spatio-temporal mixed particle filter (SMP Filter) is proposed to track the led-based grasp rectangles which enables video-level annotation of a single grasp rectangle per object. As leds blink at high frequency, the Event-Stream dataset is annotated in a high frequency of 1 kHz. Based on the Event-Stream dataset, we develop a deep neural network for grasping detection which consider the angle learning problem as classification instead of regression. The method performs high detection accuracy on our Event-Stream dataset with 93% precision at object-wise level. This work provides a large-scale and well-annotated dataset, and promotes the neuromorphic vision applications in agile robot.