 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR^3: Replay, Reflection, and Ranking Rewards for LLM Reinforcement Learning
Jan 27, 2026Large reasoning models (LRMs) aim to solve diverse and complex problems through structured reasoning. Recent advances in group-based policy optimization methods have shown promise in enabling stable advantage estimation without reliance on process-level annotations. However, these methods rely on advantage gaps induced by high-quality samples within the same batch, which makes the training process fragile and inefficient when intra-group advantages collapse under challenging tasks. To address these problems, we propose a reinforcement learning mechanism named \emph{\textbf{R^3}} that along three directions: (1) a \emph{cross-context \underline{\textbf{R}}eplay} strategy that maintains the intra-group advantage by recalling valuable examples from historical trajectories of the same query, (2) an \emph{in-context self-\underline{\textbf{R}}eflection} mechanism enabling models to refine outputs by leveraging past failures, and (3) a \emph{structural entropy \underline{\textbf{R}}anking reward}, which assigns relative rewards to truncated or failed samples by ranking responses based on token-level entropy patterns, capturing both local exploration and global stability. We implement our method on Deepseek-R1-Distill-Qwen-1.5B and train it on the DeepscaleR-40k in the math domain. Experiments demonstrate our method achieves SoTA performance on several math benchmarks, representing significant improvements and fewer reasoning tokens over the base models. Code and model will be released.
Dynamics of Human-AI Collective Knowledge on the Web: A Scalable Model and Insights for Sustainable Growth
Jan 27, 2026Humans and large language models (LLMs) now co-produce and co-consume the web's shared knowledge archives. Such human-AI collective knowledge ecosystems contain feedback loops with both benefits (e.g., faster growth, easier learning) and systemic risks (e.g., quality dilution, skill reduction, model collapse). To understand such phenomena, we propose a minimal, interpretable dynamical model of the co-evolution of archive size, archive quality, model (LLM) skill, aggregate human skill, and query volume. The model captures two content inflows (human, LLM) controlled by a gate on LLM-content admissions, two learning pathways for humans (archive study vs. LLM assistance), and two LLM-training modalities (corpus-driven scaling vs. learning from human feedback). Through numerical experiments, we identify different growth regimes (e.g., healthy growth, inverted flow, inverted learning, oscillations), and show how platform and policy levers (gate strictness, LLM training, human learning pathways) shift the system across regime boundaries. Two domain configurations (PubMed, GitHub and Copilot) illustrate contrasting steady states under different growth rates and moderation norms. We also fit the model to Wikipedia's knowledge flow during pre-ChatGPT and post-ChatGPT eras separately. We find a rise in LLM additions with a concurrent decline in human inflow, consistent with a regime identified by the model. Our model and analysis yield actionable insights for sustainable growth of human-AI collective knowledge on the Web.
ReViSE: Towards Reason-Informed Video Editing in Unified Models with Self-Reflective Learning
Dec 11, 2025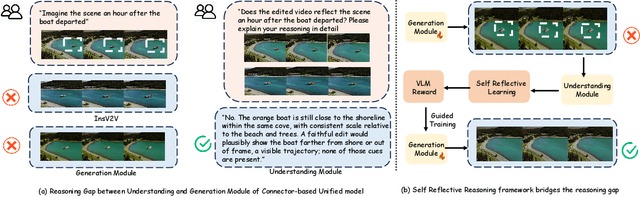
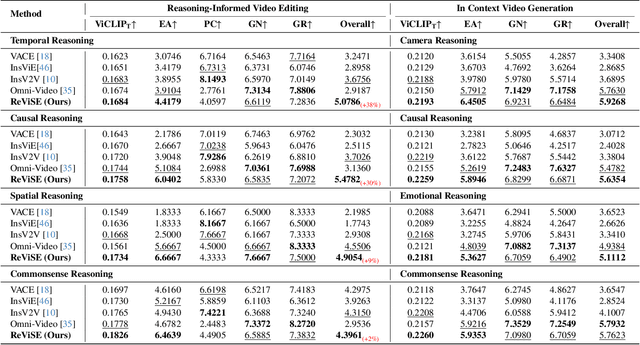

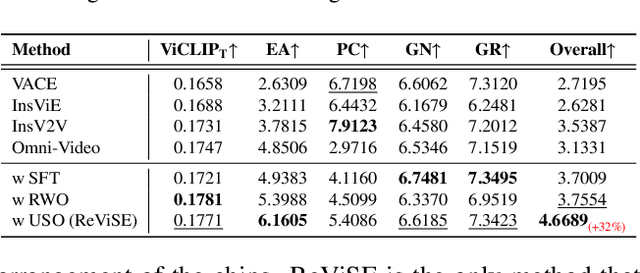
Video unified models exhibit strong capabilities in understanding and generation, yet they struggle with reason-informed visual editing even when equipped with powerful internal vision-language models (VLMs). We attribute this gap to two factors: 1) existing datasets are inadequate for training and evaluating reasoning-aware video editing, and 2) an inherent disconnect between the models' reasoning and editing capabilities, which prevents the rich understanding from effectively instructing the editing process. Bridging this gap requires an integrated framework that connects reasoning with visual transformation. To address this gap, we introduce the Reason-Informed Video Editing (RVE) task, which requires reasoning about physical plausibility and causal dynamics during editing. To support systematic evaluation, we construct RVE-Bench, a comprehensive benchmark with two complementary subsets: Reasoning-Informed Video Editing and In-Context Video Generation. These subsets cover diverse reasoning dimensions and real-world editing scenarios. Building upon this foundation, we propose the ReViSE, a Self-Reflective Reasoning (SRF) framework that unifies generation and evaluation within a single architecture. The model's internal VLM provides intrinsic feedback by assessing whether the edited video logically satisfies the given instruction. The differential feedback that refines the generator's reasoning behavior during training. Extensive experiments on RVE-Bench demonstrate that ReViSE significantly enhances editing accuracy and visual fidelity, achieving a 32% improvement of the Overall score in the reasoning-informed video editing subset over state-of-the-art methods.
Task-Specific Zero-shot Quantization-Aware Training for Object Detection
Jul 22, 2025Quantization is a key technique to reduce network size and computational complexity by representing the network parameters with a lower precision. Traditional quantization methods rely on access to original training data, which is often restricted due to privacy concerns or security challenges. Zero-shot Quantization (ZSQ) addresses this by using synthetic data generated from pre-trained models, eliminating the need for real training data. Recently, ZSQ has been extended to object detection. However, existing methods use unlabeled task-agnostic synthetic images that lack the specific information required for object detection, leading to suboptimal performance. In this paper, we propose a novel task-specific ZSQ framework for object detection networks, which consists of two main stages. First, we introduce a bounding box and category sampling strategy to synthesize a task-specific calibration set from the pre-trained network, reconstructing object locations, sizes, and category distributions without any prior knowledge. Second, we integrate task-specific training into the knowledge distillation process to restore the performance of quantized detection networks. Extensive experiments conducted on the MS-COCO and Pascal VOC datasets demonstrate the efficiency and state-of-the-art performance of our method. Our code is publicly available at: https://github.com/DFQ-Dojo/dfq-toolkit .
DFVEdit: Conditional Delta Flow Vector for Zero-shot Video Editing
Jun 26, 2025The advent of Video Diffusion Transformers (Video DiTs) marks a milestone in video generation. However, directly applying existing video editing methods to Video DiTs often incurs substantial computational overhead, due to resource-intensive attention modification or finetuning. To alleviate this problem, we present DFVEdit, an efficient zero-shot video editing method tailored for Video DiTs. DFVEdit eliminates the need for both attention modification and fine-tuning by directly operating on clean latents via flow transformation. To be more specific, we observe that editing and sampling can be unified under the continuous flow perspective. Building upon this foundation, we propose the Conditional Delta Flow Vector (CDFV) -- a theoretically unbiased estimation of DFV -- and integrate Implicit Cross Attention (ICA) guidance as well as Embedding Reinforcement (ER) to further enhance editing quality. DFVEdit excels in practical efficiency, offering at least 20x inference speed-up and 85\% memory reduction on Video DiTs compared to attention-engineering-based editing methods. Extensive quantitative and qualitative experiments demonstrate that DFVEdit can be seamlessly applied to popular Video DiTs (e.g., CogVideoX and Wan2.1), attaining state-of-the-art performance on structural fidelity, spatial-temporal consistency, and editing quality.
A Simple Linear Patch Revives Layer-Pruned Large Language Models
May 30, 2025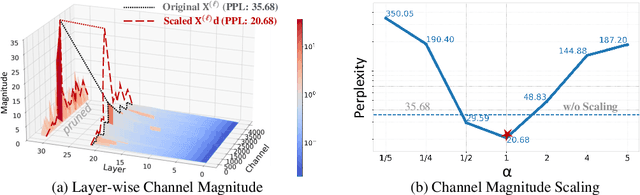
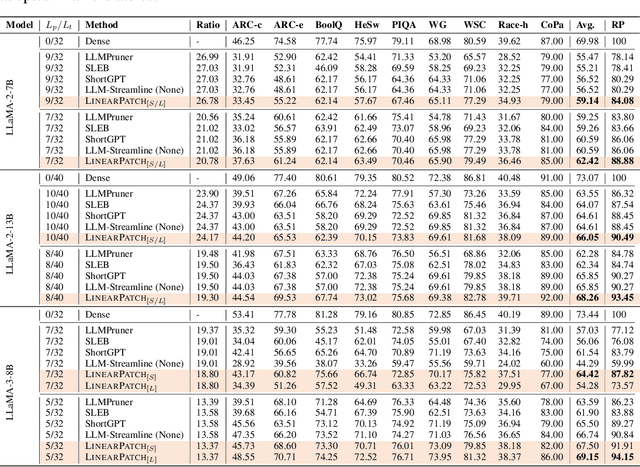
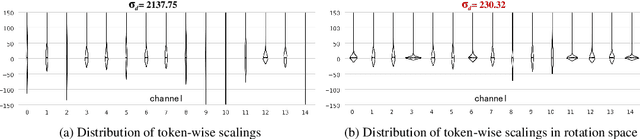
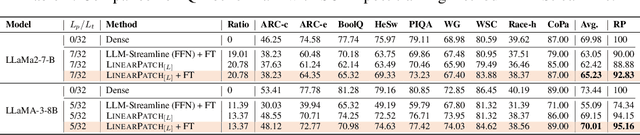
Layer pruning has become a popular technique for compressing large language models (LLMs) due to its simplicity. However, existing layer pruning methods often suffer from significant performance drops. We identify that this degradation stems from the mismatch of activation magnitudes across layers and tokens at the pruning interface. To address this, we propose LinearPatch, a simple plug-and-play technique to revive the layer-pruned LLMs. The proposed method adopts Hadamard transformation to suppress massive outliers in particular tokens, and channel-wise scaling to align the activation magnitudes. These operations can be fused into a single matrix, which functions as a patch to bridge the pruning interface with negligible inference overhead. LinearPatch retains up to 94.15% performance of the original model when pruning 5 layers of LLaMA-3-8B on the question answering benchmark, surpassing existing state-of-the-art methods by 4%. In addition, the patch matrix can be further optimized with memory efficient offline knowledge distillation. With only 5K samples, the retained performance of LinearPatch can be further boosted to 95.16% within 30 minutes on a single computing card.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
EgoVid-5M: A Large-Scale Video-Action Dataset for Egocentric Video Generation
Nov 13, 2024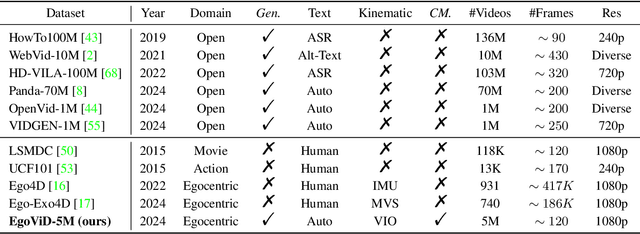
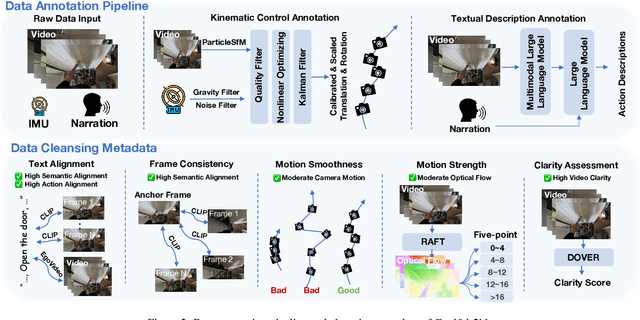
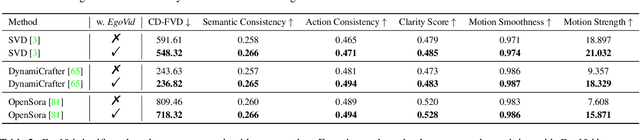
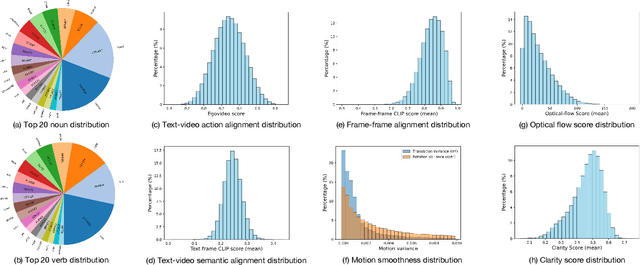
Video generation has emerged as a promising tool for world simulation, leveraging visual data to replicate real-world environments. Within this context, egocentric video generation, which centers on the human perspective, holds significant potential for enhancing applications in virtual reality, augmented reality, and gaming. However, the generation of egocentric videos presents substantial challenges due to the dynamic nature of egocentric viewpoints, the intricate diversity of actions, and the complex variety of scenes encountered. Existing datasets are inadequate for addressing these challenges effectively. To bridge this gap, we present EgoVid-5M, the first high-quality dataset specifically curated for egocentric video generation. EgoVid-5M encompasses 5 million egocentric video clips and is enriched with detailed action annotations, including fine-grained kinematic control and high-level textual descriptions. To ensure the integrity and usability of the dataset, we implement a sophisticated data cleaning pipeline designed to maintain frame consistency, action coherence, and motion smoothness under egocentric conditions. Furthermore, we introduce EgoDreamer, which is capable of generating egocentric videos driven simultaneously by action descriptions and kinematic control signals. The EgoVid-5M dataset, associated action annotations, and all data cleansing metadata will be released for the advancement of research in egocentric video generation.
FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs
Oct 22, 2024



FlashAttention series has been widely applied in the inference of large language models (LLMs). However, FlashAttention series only supports the high-level GPU architectures, e.g., Ampere and Hopper. At present, FlashAttention series is not easily transferrable to NPUs and low-resource GPUs. Moreover, FlashAttention series is inefficient for multi- NPUs or GPUs inference scenarios. In this work, we propose FastAttention which pioneers the adaptation of FlashAttention series for NPUs and low-resource GPUs to boost LLM inference efficiency. Specifically, we take Ascend NPUs and Volta-based GPUs as representatives for designing our FastAttention. We migrate FlashAttention series to Ascend NPUs by proposing a novel two-level tiling strategy for runtime speedup, tiling-mask strategy for memory saving and the tiling-AllReduce strategy for reducing communication overhead, respectively. Besides, we adapt FlashAttention for Volta-based GPUs by redesigning the operands layout in shared memory and introducing a simple yet effective CPU-GPU cooperative strategy for efficient memory utilization. On Ascend NPUs, our FastAttention can achieve a 10.7$\times$ speedup compared to the standard attention implementation. Llama-7B within FastAttention reaches up to 5.16$\times$ higher throughput than within the standard attention. On Volta architecture GPUs, FastAttention yields 1.43$\times$ speedup compared to its equivalents in \texttt{xformers}. Pangu-38B within FastAttention brings 1.46$\times$ end-to-end speedup using FasterTransformer. Coupled with the propose CPU-GPU cooperative strategy, FastAttention supports a maximal input length of 256K on 8 V100 GPUs. All the codes will be made available soon.
Beyond 2:4: exploring V:N:M sparsity for efficient transformer inference on GPUs
Oct 21, 2024



To date, 2:4 sparsity has stood as the only sparse pattern that can be accelerated using sparse tensor cores on GPUs. In practice, 2:4 sparsity often possesses low actual speedups ($\leq 1.3$) and requires fixed sparse ratios, meaning that other ratios, such as 4:8, 8:16, or those exceeding 50% sparsity, do not incur any speedups on GPUs. Recent studies suggest that V:N:M sparsity is promising in addressing these limitations of 2:4 sparsity. However, regarding accuracy, the effects of V:N:M sparsity on broader Transformer models, such as vision Transformers and large language models (LLMs), are largely unexamined. Moreover, Some specific issues related to V:N:M sparsity, such as how to select appropriate V and M values, remain unresolved. In this study, we thoroughly investigate the application of V:N:M sparsity in vision models and LLMs across multiple tasks, from pertaining to downstream tasks. We propose three key approaches to enhance the applicability and accuracy of V:N:M-sparse Transformers, including heuristic V and M selection, V:N:M-specific channel permutation, and three-staged LoRA training techniques. Experimental results show that, with our methods, the DeiT-small achieves lossless accuracy at 64:2:5 sparsity, while the DeiT-base maintains accuracy even at 64:2:8 sparsity. In addition, the fine-tuned LLama2-7B at 64:2:5 sparsity performs comparably or better than training-free 2:4 sparse alternatives on downstream tasks. More importantly, V:N:M-sparse Transformers offer a wider range of speedup-accuracy trade-offs compared to 2:4 sparsity. Overall, our exploration largely facilitates the V:N:M sparsity to act as a truly effective acceleration solution for Transformers in cost-sensitive inference scenarios.