 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPD-Faith Bench: Diagnosing and Improving Faithfulness in Chain-of-Thought for Multimodal Large Language Models
Feb 08, 2026Chain-of-Thought reasoning is widely used to improve the interpretability of multimodal large language models (MLLMs), yet the faithfulness of the generated reasoning traces remains unclear. Prior work has mainly focused on perceptual hallucinations, leaving reasoning level unfaithfulness underexplored. To isolate faithfulness from linguistic priors, we introduce SPD-Faith Bench, a diagnostic benchmark based on fine-grained image difference reasoning that enforces explicit visual comparison. Evaluations on state-of-the-art MLLMs reveal two systematic failure modes, perceptual blindness and perception-reasoning dissociation. We trace these failures to decaying visual attention and representation shifts in the residual stream. Guided by this analysis, we propose SAGE, a train-free visual evidence-calibrated framework that improves visual routing and aligns reasoning with perception. Our results highlight the importance of explicitly evaluating faithfulness beyond response correctness. Our benchmark and codes are available at https://github.com/Johanson-colab/SPD-Faith-Bench.
LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild
Oct 16, 2025Deep research -- producing comprehensive, citation-grounded reports by searching and synthesizing information from hundreds of live web sources -- marks an important frontier for agentic systems. To rigorously evaluate this ability, four principles are essential: tasks should be (1) user-centric, reflecting realistic information needs, (2) dynamic, requiring up-to-date information beyond parametric knowledge, (3) unambiguous, ensuring consistent interpretation across users, and (4) multi-faceted and search-intensive, requiring search over numerous web sources and in-depth analysis. Existing benchmarks fall short of these principles, often focusing on narrow domains or posing ambiguous questions that hinder fair comparison. Guided by these principles, we introduce LiveResearchBench, a benchmark of 100 expert-curated tasks spanning daily life, enterprise, and academia, each requiring extensive, dynamic, real-time web search and synthesis. Built with over 1,500 hours of human labor, LiveResearchBench provides a rigorous basis for systematic evaluation. To evaluate citation-grounded long-form reports, we introduce DeepEval, a comprehensive suite covering both content- and report-level quality, including coverage, presentation, citation accuracy and association, consistency and depth of analysis. DeepEval integrates four complementary evaluation protocols, each designed to ensure stable assessment and high agreement with human judgments. Using LiveResearchBench and DeepEval, we conduct a comprehensive evaluation of 17 frontier deep research systems, including single-agent web search, single-agent deep research, and multi-agent systems. Our analysis reveals current strengths, recurring failure modes, and key system components needed to advance reliable, insightful deep research.
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
Beyond Accuracy: Dissecting Mathematical Reasoning for LLMs Under Reinforcement Learning
Jun 05, 2025Reinforcement learning (RL) has become the dominant paradigm for endowing language models with advanced reasoning capabilities. Despite the substantial empirical gains demonstrated by RL-based training methods like GRPO, a granular understanding of their advantages is still lacking. To address this gap, we introduce a fine-grained analytic framework to dissect the impact of RL on reasoning. Our framework specifically investigates key elements that have been hypothesized to benefit from RL training: (1) plan-following and execution, (2) problem decomposition, and (3) improved reasoning and knowledge utilization. Using this framework, we gain insights beyond mere accuracy. For instance, providing models with explicit step-by-step plans surprisingly degrades performance on the most challenging benchmarks, yet RL-tuned models exhibit greater robustness, experiencing markedly smaller performance drops than their base counterparts. This suggests that RL may not primarily enhance the execution of external plans but rather empower models to formulate and follow internal strategies better suited to their reasoning processes. Conversely, we observe that RL enhances the model's capacity to integrate provided knowledge into its reasoning process, leading to performance improvements across diverse tasks. We also study difficulty, showing improved training by developing new ways to exploit hard problems. Our findings lay a foundation for more principled training and evaluation of reasoning models.
OmniGenBench: A Benchmark for Omnipotent Multimodal Generation across 50+ Tasks
May 24, 2025



Recent breakthroughs in large multimodal models (LMMs), such as the impressive GPT-4o-Native, have demonstrated remarkable proficiency in following general-purpose instructions for image generation. However, current benchmarks often lack the necessary breadth and depth to fully evaluate the diverse capabilities of these models. To overcome this limitation, we introduce OmniGenBench, a novel and comprehensive benchmark meticulously designed to assess the instruction-following abilities of state-of-the-art LMMs across both perception-centric and cognition-centric dimensions. Our OmniGenBench includes 57 diverse sub-tasks grounded in real-world scenarios, systematically categorized according to the specific model capabilities they demand. For rigorous evaluation, we further employ a dual-mode protocol. This protocol utilizes off-the-shelf visual parsing tools for perception-centric tasks and a powerful LLM-based judger for cognition-centric tasks to assess the alignment between generated images and user instructions. Using OmniGenBench, we evaluate mainstream generative models, including prevalent models like GPT-4o, Gemini-2.0-Flash, and Seedream, and provide in-depth comparisons and analyses of their performance.Code and data are available at https://github.com/emilia113/OmniGenBench.
COSMOS: Predictable and Cost-Effective Adaptation of LLMs
Apr 30, 2025Large language models (LLMs) achieve remarkable performance across numerous tasks by using a diverse array of adaptation strategies. However, optimally selecting a model and adaptation strategy under resource constraints is challenging and often requires extensive experimentation. We investigate whether it is possible to accurately predict both performance and cost without expensive trials. We formalize the strategy selection problem for LLMs and introduce COSMOS, a unified prediction framework that efficiently estimates adaptation outcomes at minimal cost. We instantiate and study the capability of our framework via a pair of powerful predictors: embedding-augmented lightweight proxy models to predict fine-tuning performance, and low-sample scaling laws to forecast retrieval-augmented in-context learning. Extensive evaluation across eight representative benchmarks demonstrates that COSMOS achieves high prediction accuracy while reducing computational costs by 92.72% on average, and up to 98.71% in resource-intensive scenarios. Our results show that efficient prediction of adaptation outcomes is not only feasible but can substantially reduce the computational overhead of LLM deployment while maintaining performance standards.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
EgoVid-5M: A Large-Scale Video-Action Dataset for Egocentric Video Generation
Nov 13, 2024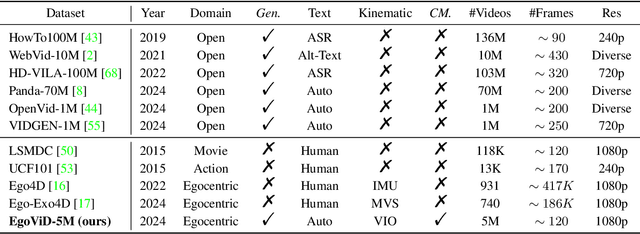
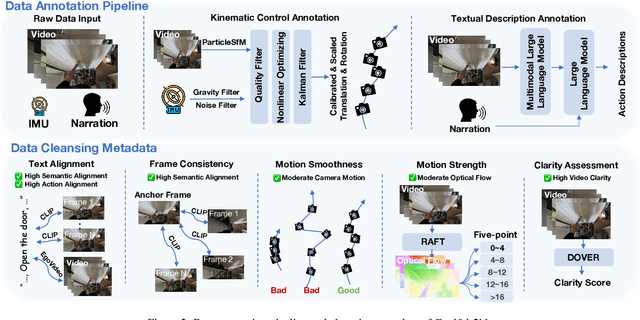
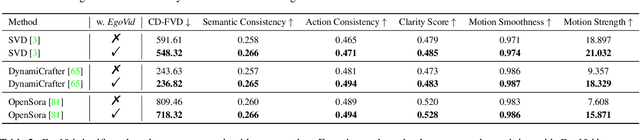
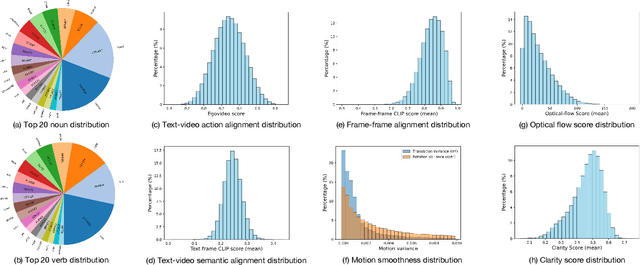
Video generation has emerged as a promising tool for world simulation, leveraging visual data to replicate real-world environments. Within this context, egocentric video generation, which centers on the human perspective, holds significant potential for enhancing applications in virtual reality, augmented reality, and gaming. However, the generation of egocentric videos presents substantial challenges due to the dynamic nature of egocentric viewpoints, the intricate diversity of actions, and the complex variety of scenes encountered. Existing datasets are inadequate for addressing these challenges effectively. To bridge this gap, we present EgoVid-5M, the first high-quality dataset specifically curated for egocentric video generation. EgoVid-5M encompasses 5 million egocentric video clips and is enriched with detailed action annotations, including fine-grained kinematic control and high-level textual descriptions. To ensure the integrity and usability of the dataset, we implement a sophisticated data cleaning pipeline designed to maintain frame consistency, action coherence, and motion smoothness under egocentric conditions. Furthermore, we introduce EgoDreamer, which is capable of generating egocentric videos driven simultaneously by action descriptions and kinematic control signals. The EgoVid-5M dataset, associated action annotations, and all data cleansing metadata will be released for the advancement of research in egocentric video generation.
InternLM2.5-StepProver: Advancing Automated Theorem Proving via Expert Iteration on Large-Scale LEAN Problems
Oct 21, 2024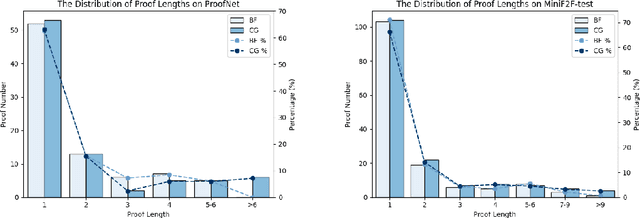

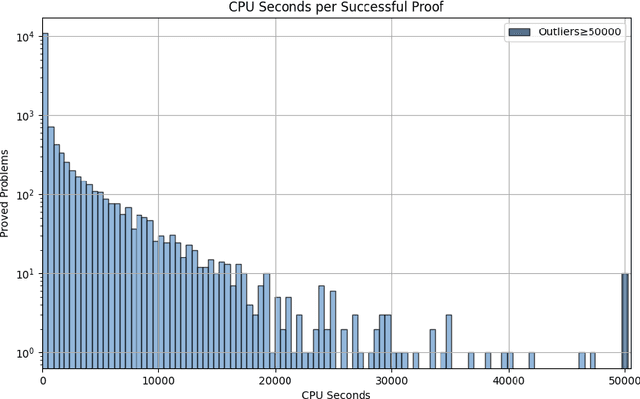

Large Language Models (LLMs) have emerged as powerful tools in mathematical theorem proving, particularly when utilizing formal languages such as LEAN. The major learning paradigm is expert iteration, which necessitates a pre-defined dataset comprising numerous mathematical problems. In this process, LLMs attempt to prove problems within the dataset and iteratively refine their capabilities through self-training on the proofs they discover. We propose to use large scale LEAN problem datasets Lean-workbook for expert iteration with more than 20,000 CPU days. During expert iteration, we found log-linear trends between solved problem amount with proof length and CPU usage. We train a critic model to select relatively easy problems for policy models to make trials and guide the model to search for deeper proofs. InternLM2.5-StepProver achieves open-source state-of-the-art on MiniF2F, Lean-Workbook-Plus, ProofNet, and Putnam benchmarks. Specifically, it achieves a pass of 65.9% on the MiniF2F-test and proves (or disproves) 17.0% of problems in Lean-Workbook-Plus which shows a significant improvement compared to only 9.5% of problems proved when Lean-Workbook-Plus was released. We open-source our models and searched proofs at https://github.com/InternLM/InternLM-Math and https://huggingface.co/datasets/internlm/Lean-Workbook.