 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIneq-Comp: Benchmarking Human-Intuitive Compositional Reasoning in Automated Theorem Proving on Inequalities
May 19, 2025LLM-based formal proof assistants (e.g., in Lean) hold great promise for automating mathematical discovery. But beyond syntactic correctness, do these systems truly understand mathematical structure as humans do? We investigate this question through the lens of mathematical inequalities -- a fundamental tool across many domains. While modern provers can solve basic inequalities, we probe their ability to handle human-intuitive compositionality. We introduce Ineq-Comp, a benchmark built from elementary inequalities through systematic transformations, including variable duplication, algebraic rewriting, and multi-step composition. Although these problems remain easy for humans, we find that most provers -- including Goedel, STP, and Kimina-7B -- struggle significantly. DeepSeek-Prover-V2-7B shows relative robustness -- possibly because it is trained to decompose the problems into sub-problems -- but still suffers a 20\% performance drop (pass@32). Strikingly, performance remains poor for all models even when formal proofs of the constituent parts are provided in context, revealing that the source of weakness is indeed in compositional reasoning. Our results expose a persisting gap between the generalization behavior of current AI provers and human mathematical intuition.
Theoretical Benefit and Limitation of Diffusion Language Model
Feb 13, 2025
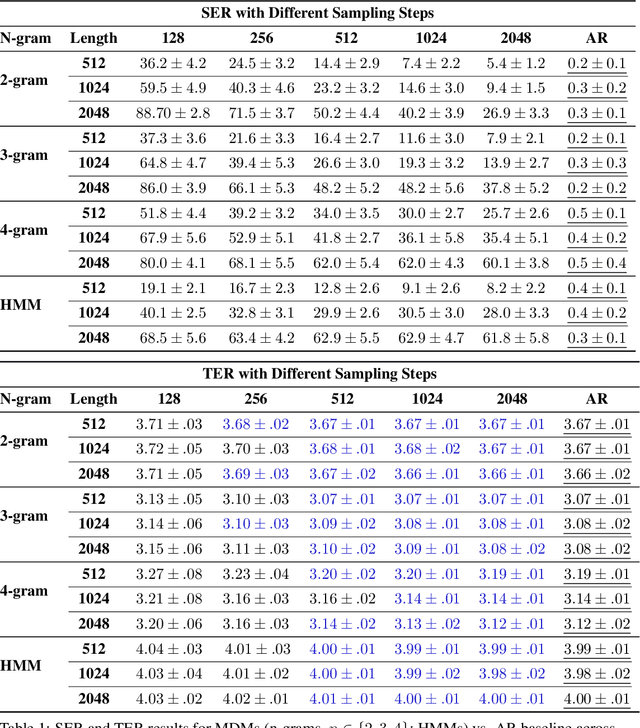
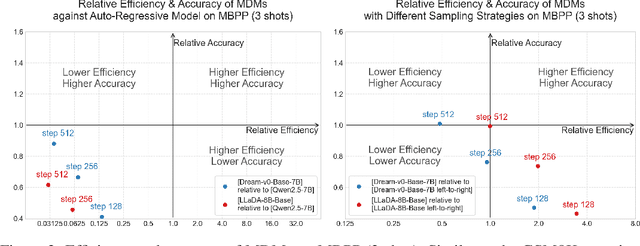
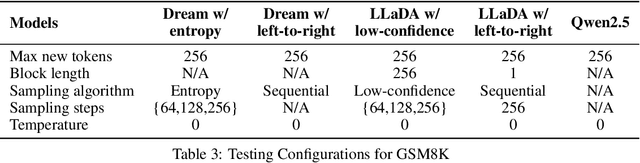
Diffusion language models have emerged as a promising approach for text generation. One would naturally expect this method to be an efficient replacement for autoregressive models since multiple tokens can be sampled in parallel during each diffusion step. However, its efficiency-accuracy trade-off is not yet well understood. In this paper, we present a rigorous theoretical analysis of a widely used type of diffusion language model, the Masked Diffusion Model (MDM), and find that its effectiveness heavily depends on the target evaluation metric. Under mild conditions, we prove that when using perplexity as the metric, MDMs can achieve near-optimal perplexity in sampling steps regardless of sequence length, demonstrating that efficiency can be achieved without sacrificing performance. However, when using the sequence error rate--which is important for understanding the "correctness" of a sequence, such as a reasoning chain--we show that the required sampling steps must scale linearly with sequence length to obtain "correct" sequences, thereby eliminating MDM's efficiency advantage over autoregressive models. Our analysis establishes the first theoretical foundation for understanding the benefits and limitations of MDMs. All theoretical findings are supported by empirical studies.
Lean Workbook: A large-scale Lean problem set formalized from natural language math problems
Jun 07, 2024Large language models have demonstrated impressive capabilities across various natural language processing tasks, especially in solving mathematical problems. However, large language models are not good at math theorem proving using formal languages like Lean. A significant challenge in this area is the scarcity of training data available in these formal languages. To address this issue, we propose a novel pipeline that iteratively generates and filters synthetic data to translate natural language mathematical problems into Lean 4 statements, and vice versa. Our results indicate that the synthetic data pipeline can provide useful training data and improve the performance of LLMs in translating and understanding complex mathematical problems and proofs. Our final dataset contains about 57K formal-informal question pairs along with searched proof from the math contest forum and 21 new IMO questions. We open-source our code at https://github.com/InternLM/InternLM-Math and our data at https://huggingface.co/datasets/InternLM/Lean-Workbook.