 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe PokeAgent Challenge: Competitive and Long-Context Learning at Scale
Mar 17, 2026We present the PokeAgent Challenge, a large-scale benchmark for decision-making research built on Pokemon's multi-agent battle system and expansive role-playing game (RPG) environment. Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems for frontier AI, yet few benchmarks stress all three simultaneously under realistic conditions. PokeAgent targets these limitations at scale through two complementary tracks: our Battling Track, which calls for strategic reasoning and generalization under partial observability in competitive Pokemon battles, and our Speedrunning Track, which requires long-horizon planning and sequential decision-making in the Pokemon RPG. Our Battling Track supplies a dataset of 20M+ battle trajectories alongside a suite of heuristic, RL, and LLM-based baselines capable of high-level competitive play. Our Speedrunning Track provides the first standardized evaluation framework for RPG speedrunning, including an open-source multi-agent orchestration system for modular, reproducible comparisons of harness-based LLM approaches. Our NeurIPS 2025 competition validates both the quality of our resources and the research community's interest in Pokemon, with over 100 teams competing across both tracks and winning solutions detailed in our paper. Participant submissions and our baselines reveal considerable gaps between generalist (LLM), specialist (RL), and elite human performance. Analysis against the BenchPress evaluation matrix shows that Pokemon battling is nearly orthogonal to standard LLM benchmarks, measuring capabilities not captured by existing suites and positioning Pokemon as an unsolved benchmark that can drive RL and LLM research forward. We transition to a living benchmark with a live leaderboard for Battling and self-contained evaluation for Speedrunning at https://pokeagentchallenge.com.
Automatic Generation of High-Performance RL Environments
Mar 12, 2026Translating complex reinforcement learning (RL) environments into high-performance implementations has traditionally required months of specialized engineering. We present a reusable recipe - a generic prompt template, hierarchical verification, and iterative agent-assisted repair - that produces semantically equivalent high-performance environments for <$10 in compute cost. We demonstrate three distinct workflows across five environments. Direct translation (no prior performance implementation exists): EmuRust (1.5x PPO speedup via Rust parallelism for a Game Boy emulator) and PokeJAX, the first GPU-parallel Pokemon battle simulator (500M SPS random action, 15.2M SPS PPO; 22,320x over the TypeScript reference). Translation verified against existing performance implementations: throughput parity with MJX (1.04x) and 5x over Brax at matched GPU batch sizes (HalfCheetah JAX); 42x PPO (Puffer Pong). New environment creation: TCGJax, the first deployable JAX Pokemon TCG engine (717K SPS random action, 153K SPS PPO; 6.6x over the Python reference), synthesized from a web-extracted specification. At 200M parameters, the environment overhead drops below 4% of training time. Hierarchical verification (property, interaction, and rollout tests) confirms semantic equivalence for all five environments; cross-backend policy transfer confirms zero sim-to-sim gap for all five environments. TCGJax, synthesized from a private reference absent from public repositories, serves as a contamination control for agent pretraining data concerns. The paper contains sufficient detail - including representative prompts, verification methodology, and complete results - that a coding agent could reproduce the translations directly from the manuscript.
DataFactory: Collaborative Multi-Agent Framework for Advanced Table Question Answering
Mar 10, 2026Table Question Answering (TableQA) enables natural language interaction with structured tabular data. However, existing large language model (LLM) approaches face critical limitations: context length constraints that restrict data handling capabilities, hallucination issues that compromise answer reliability, and single-agent architectures that struggle with complex reasoning scenarios involving semantic relationships and multi-hop logic. This paper introduces DataFactory, a multi-agent framework that addresses these limitations through specialized team coordination and automated knowledge transformation. The framework comprises a Data Leader employing the ReAct paradigm for reasoning orchestration, together with dedicated Database and Knowledge Graph teams, enabling the systematic decomposition of complex queries into structured and relational reasoning tasks. We formalize automated data-to-knowledge graph transformation via the mapping function T:D x S x R -> G, and implement natural language-based consultation that - unlike fixed workflow multi-agent systems - enables flexible inter-agent deliberation and adaptive planning to improve coordination robustness. We also apply context engineering strategies that integrate historical patterns and domain knowledge to reduce hallucinations and improve query accuracy. Across TabFact, WikiTableQuestions, and FeTaQA, using eight LLMs from five providers, results show consistent gains. Our approach improves accuracy by 20.2% (TabFact) and 23.9% (WikiTQ) over baselines, with significant effects (Cohen's d > 1). Team coordination also outperforms single-team variants (+5.5% TabFact, +14.4% WikiTQ, +17.1% FeTaQA ROUGE-2). The framework offers design guidelines for multi-agent collaboration and a practical platform for enterprise data analysis through integrated structured querying and graph-based knowledge representation.
* Published in Information Processing & Management, 2026
AlgoVeri: An Aligned Benchmark for Verified Code Generation on Classical Algorithms
Feb 10, 2026Vericoding refers to the generation of formally verified code from rigorous specifications. Recent AI models show promise in vericoding, but a unified methodology for cross-paradigm evaluation is lacking. Existing benchmarks test only individual languages/tools (e.g., Dafny, Verus, and Lean) and each covers very different tasks, so the performance numbers are not directly comparable. We address this gap with AlgoVeri, a benchmark that evaluates vericoding of $77$ classical algorithms in Dafny, Verus, and Lean. By enforcing identical functional contracts, AlgoVeri reveals critical capability gaps in verification systems. While frontier models achieve tractable success in Dafny ($40.3$% for Gemini-3 Flash), where high-level abstractions and SMT automation simplify the workflow, performance collapses under the systems-level memory constraints of Verus ($24.7$%) and the explicit proof construction required by Lean (7.8%). Beyond aggregate metrics, we uncover a sharp divergence in test-time compute dynamics: Gemini-3 effectively utilizes iterative repair to boost performance (e.g., tripling pass rates in Dafny), whereas GPT-OSS saturates early. Finally, our error analysis shows that language design affects the refinement trajectory: while Dafny allows models to focus on logical correctness, Verus and Lean trap models in persistent syntactic and semantic barriers. All data and evaluation code can be found at https://github.com/haoyuzhao123/algoveri.
MUSIC: MUlti-Step Instruction Contrast for Multi-Turn Reward Models
Dec 31, 2025Evaluating the quality of multi-turn conversations is crucial for developing capable Large Language Models (LLMs), yet remains a significant challenge, often requiring costly human evaluation. Multi-turn reward models (RMs) offer a scalable alternative and can provide valuable signals for guiding LLM training. While recent work has advanced multi-turn \textit{training} techniques, effective automated \textit{evaluation} specifically for multi-turn interactions lags behind. We observe that standard preference datasets, typically contrasting responses based only on the final conversational turn, provide insufficient signal to capture the nuances of multi-turn interactions. Instead, we find that incorporating contrasts spanning \textit{multiple} turns is critical for building robust multi-turn RMs. Motivated by this finding, we propose \textbf{MU}lti-\textbf{S}tep \textbf{I}nstruction \textbf{C}ontrast (MUSIC), an unsupervised data augmentation strategy that synthesizes contrastive conversation pairs exhibiting differences across multiple turns. Leveraging MUSIC on the Skywork preference dataset, we train a multi-turn RM based on the Gemma-2-9B-Instruct model. Empirical results demonstrate that our MUSIC-augmented RM outperforms baseline methods, achieving higher alignment with judgments from advanced proprietary LLM judges on multi-turn conversations, crucially, without compromising performance on standard single-turn RM benchmarks.
Recurrent Autoregressive Diffusion: Global Memory Meets Local Attention
Nov 17, 2025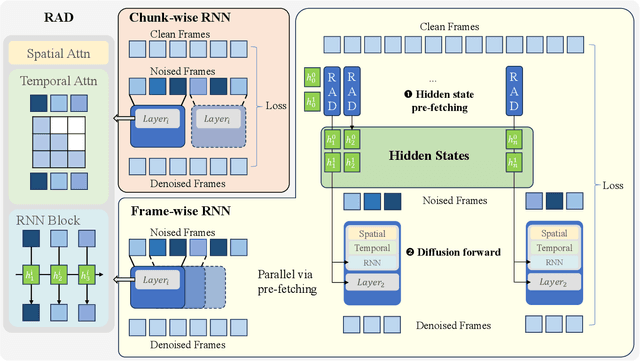
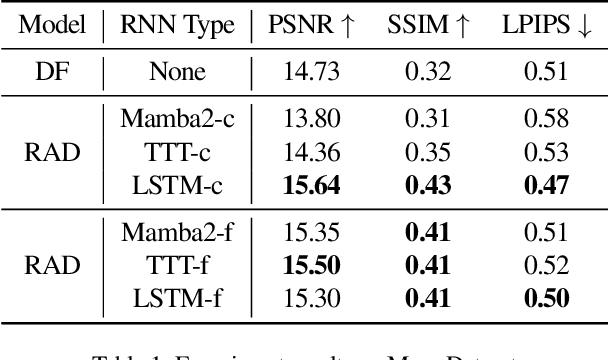
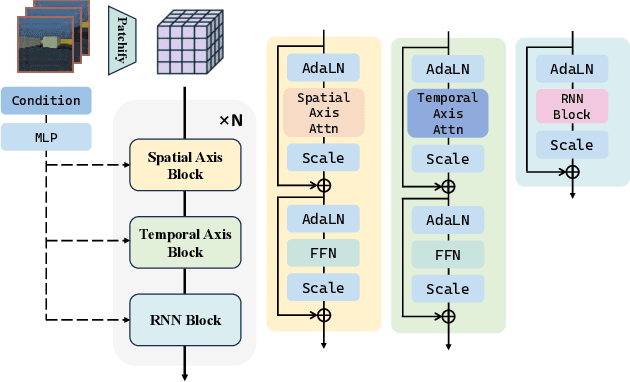
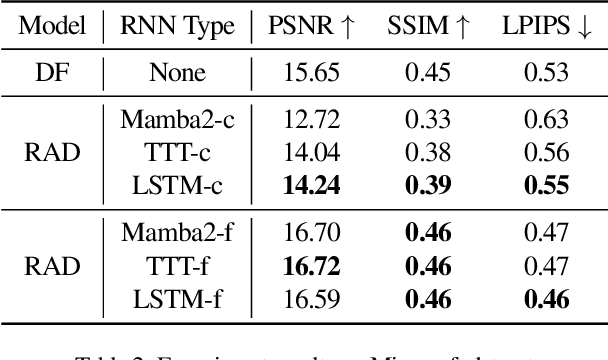
Recent advancements in video generation have demonstrated the potential of using video diffusion models as world models, with autoregressive generation of infinitely long videos through masked conditioning. However, such models, usually with local full attention, lack effective memory compression and retrieval for long-term generation beyond the window size, leading to issues of forgetting and spatiotemporal inconsistencies. To enhance the retention of historical information within a fixed memory budget, we introduce a recurrent neural network (RNN) into the diffusion transformer framework. Specifically, a diffusion model incorporating LSTM with attention achieves comparable performance to state-of-the-art RNN blocks, such as TTT and Mamba2. Moreover, existing diffusion-RNN approaches often suffer from performance degradation due to training-inference gap or the lack of overlap across windows. To address these limitations, we propose a novel Recurrent Autoregressive Diffusion (RAD) framework, which executes frame-wise autoregression for memory update and retrieval, consistently across training and inference time. Experiments on Memory Maze and Minecraft datasets demonstrate the superiority of RAD for long video generation, highlighting the efficiency of LSTM in sequence modeling.
Frontier LLMs Still Struggle with Simple Reasoning Tasks
Jul 09, 2025
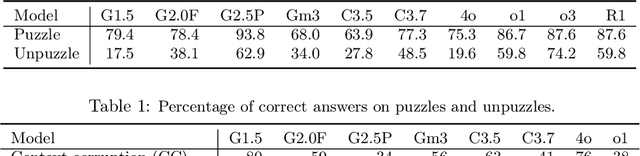
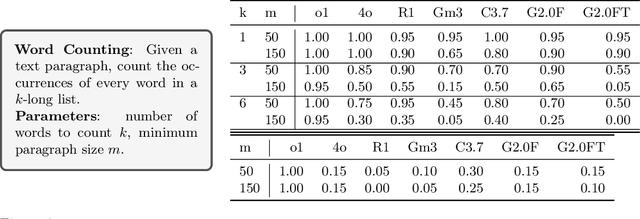
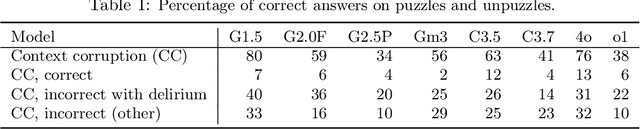
While state-of-the-art large language models (LLMs) demonstrate advanced reasoning capabilities-achieving remarkable performance on challenging competitive math and coding benchmarks-they also frequently fail on tasks that are easy for humans. This work studies the performance of frontier LLMs on a broad set of such "easy" reasoning problems. By extending previous work in the literature, we create a suite of procedurally generated simple reasoning tasks, including counting, first-order logic, proof trees, and travel planning, with changeable parameters (such as document length. or the number of variables in a math problem) that can arbitrarily increase the amount of computation required to produce the answer while preserving the fundamental difficulty. While previous work showed that traditional, non-thinking models can be made to fail on such problems, we demonstrate that even state-of-the-art thinking models consistently fail on such problems and for similar reasons (e.g. statistical shortcuts, errors in intermediate steps, and difficulties in processing long contexts). To further understand the behavior of the models, we introduce the unpuzzles dataset, a different "easy" benchmark consisting of trivialized versions of well-known math and logic puzzles. Interestingly, while modern LLMs excel at solving the original puzzles, they tend to fail on the trivialized versions, exhibiting several systematic failure patterns related to memorizing the originals. We show that this happens even if the models are otherwise able to solve problems with different descriptions but requiring the same logic. Our results highlight that out-of-distribution generalization is still problematic for frontier language models and the new generation of thinking models, even for simple reasoning tasks, and making tasks easier does not necessarily imply improved performance.
Principled Out-of-Distribution Generalization via Simplicity
May 28, 2025Modern foundation models exhibit remarkable out-of-distribution (OOD) generalization, solving tasks far beyond the support of their training data. However, the theoretical principles underpinning this phenomenon remain elusive. This paper investigates this problem by examining the compositional generalization abilities of diffusion models in image generation. Our analysis reveals that while neural network architectures are expressive enough to represent a wide range of models -- including many with undesirable behavior on OOD inputs -- the true, generalizable model that aligns with human expectations typically corresponds to the simplest among those consistent with the training data. Motivated by this observation, we develop a theoretical framework for OOD generalization via simplicity, quantified using a predefined simplicity metric. We analyze two key regimes: (1) the constant-gap setting, where the true model is strictly simpler than all spurious alternatives by a fixed gap, and (2) the vanishing-gap setting, where the fixed gap is replaced by a smoothness condition ensuring that models close in simplicity to the true model yield similar predictions. For both regimes, we study the regularized maximum likelihood estimator and establish the first sharp sample complexity guarantees for learning the true, generalizable, simple model.
Learning World Models for Interactive Video Generation
May 28, 2025Foundational world models must be both interactive and preserve spatiotemporal coherence for effective future planning with action choices. However, present models for long video generation have limited inherent world modeling capabilities due to two main challenges: compounding errors and insufficient memory mechanisms. We enhance image-to-video models with interactive capabilities through additional action conditioning and autoregressive framework, and reveal that compounding error is inherently irreducible in autoregressive video generation, while insufficient memory mechanism leads to incoherence of world models. We propose video retrieval augmented generation (VRAG) with explicit global state conditioning, which significantly reduces long-term compounding errors and increases spatiotemporal consistency of world models. In contrast, naive autoregressive generation with extended context windows and retrieval-augmented generation prove less effective for video generation, primarily due to the limited in-context learning capabilities of current video models. Our work illuminates the fundamental challenges in video world models and establishes a comprehensive benchmark for improving video generation models with internal world modeling capabilities.
Ineq-Comp: Benchmarking Human-Intuitive Compositional Reasoning in Automated Theorem Proving on Inequalities
May 19, 2025LLM-based formal proof assistants (e.g., in Lean) hold great promise for automating mathematical discovery. But beyond syntactic correctness, do these systems truly understand mathematical structure as humans do? We investigate this question through the lens of mathematical inequalities -- a fundamental tool across many domains. While modern provers can solve basic inequalities, we probe their ability to handle human-intuitive compositionality. We introduce Ineq-Comp, a benchmark built from elementary inequalities through systematic transformations, including variable duplication, algebraic rewriting, and multi-step composition. Although these problems remain easy for humans, we find that most provers -- including Goedel, STP, and Kimina-7B -- struggle significantly. DeepSeek-Prover-V2-7B shows relative robustness -- possibly because it is trained to decompose the problems into sub-problems -- but still suffers a 20\% performance drop (pass@32). Strikingly, performance remains poor for all models even when formal proofs of the constituent parts are provided in context, revealing that the source of weakness is indeed in compositional reasoning. Our results expose a persisting gap between the generalization behavior of current AI provers and human mathematical intuition.