 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum Streams for Optimizer-Inspired Transformers
May 23, 2026The residual update of a pre-norm Transformer layer admits an interpretation as one step of a first-order optimizer acting on a surrogate token energy, wherein the attention and MLP sublayers function as gradient oracles. Based on this observation, we build a family of optimizer-inspired Transformers (triple-momentum, Adam/AdamW, Muon, SOAP) and compare them under matched compute. In our main pretraining experiment, the triple-momentum TMMFormer achieves the lowest validation loss, outperforming the vanilla Transformer and prior architectural variants. A controlled ablation and supporting theory show that momentum, not preconditioning, is the main source of the gain. We further show that TMMFormer and other momentum-based designs reach flatter minima than the vanilla Transformer, which leads to less forgetting and better generalization.
LLM Swiss Round: Aggregating Multi-Benchmark Performance via Competitive Swiss-System Dynamics
Dec 24, 2025The rapid proliferation of Large Language Models (LLMs) and diverse specialized benchmarks necessitates a shift from fragmented, task-specific metrics to a holistic, competitive ranking system that effectively aggregates performance across multiple ability dimensions. Primarily using static scoring, current evaluation methods are fundamentally limited. They struggle to determine the proper mix ratio across diverse benchmarks, and critically, they fail to capture a model's dynamic competitive fitness or its vulnerability when confronted with sequential, high-stakes tasks. To address this, we introduce the novel Competitive Swiss-System Dynamics (CSD) framework. CSD simulates a multi-round, sequential contest where models are dynamically paired across a curated sequence of benchmarks based on their accumulated win-loss record. And Monte Carlo Simulation ($N=100,000$ iterations) is used to approximate the statistically robust Expected Win Score ($E[S_m]$), which eliminates the noise of random pairing and early-round luck. Furthermore, we implement a Failure Sensitivity Analysis by parameterizing the per-round elimination quantity ($T_k$), which allows us to profile models based on their risk appetite--distinguishing between robust generalists and aggressive specialists. We demonstrate that CSD provides a more nuanced and context-aware ranking than traditional aggregate scoring and static pairwise models, representing a vital step towards risk-informed, next-generation LLM evaluation.
Mitigating LLM Hallucination via Behaviorally Calibrated Reinforcement Learning
Dec 22, 2025LLM deployment in critical domains is currently impeded by persistent hallucinations--generating plausible but factually incorrect assertions. While scaling laws drove significant improvements in general capabilities, theoretical frameworks suggest hallucination is not merely stochastic error but a predictable statistical consequence of training objectives prioritizing mimicking data distribution over epistemic honesty. Standard RLVR paradigms, utilizing binary reward signals, inadvertently incentivize models as good test-takers rather than honest communicators, encouraging guessing whenever correctness probability exceeds zero. This paper presents an exhaustive investigation into behavioral calibration, which incentivizes models to stochastically admit uncertainty by abstaining when not confident, aligning model behavior with accuracy. Synthesizing recent advances, we propose and evaluate training interventions optimizing strictly proper scoring rules for models to output a calibrated probability of correctness. Our methods enable models to either abstain from producing a complete response or flag individual claims where uncertainty remains. Utilizing Qwen3-4B-Instruct, empirical analysis reveals behavior-calibrated reinforcement learning allows smaller models to surpass frontier models in uncertainty quantification--a transferable meta-skill decouplable from raw predictive accuracy. Trained on math reasoning tasks, our model's log-scale Accuracy-to-Hallucination Ratio gain (0.806) exceeds GPT-5's (0.207) in a challenging in-domain evaluation (BeyondAIME). Moreover, in cross-domain factual QA (SimpleQA), our 4B LLM achieves zero-shot calibration error on par with frontier models including Grok-4 and Gemini-2.5-Pro, even though its factual accuracy is much lower.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025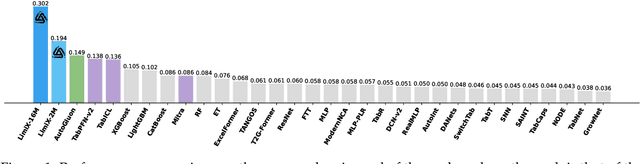
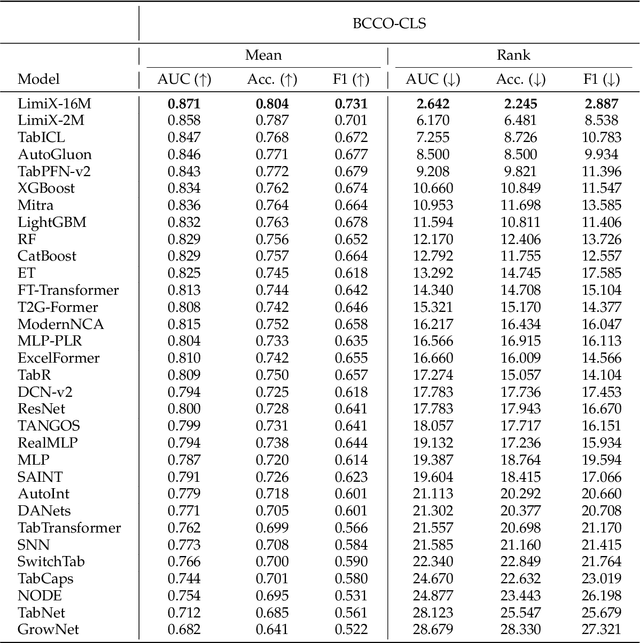
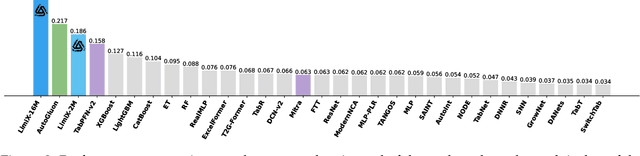
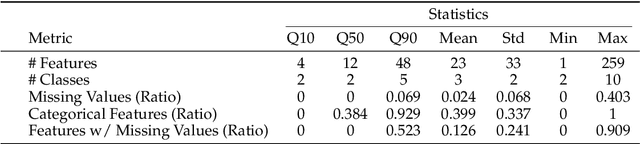
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
Retrospective Memory for Camouflaged Object Detection
Jun 18, 2025Camouflaged object detection (COD) primarily focuses on learning subtle yet discriminative representations from complex scenes. Existing methods predominantly follow the parametric feedforward architecture based on static visual representation modeling. However, they lack explicit mechanisms for acquiring historical context, limiting their adaptation and effectiveness in handling challenging camouflage scenes. In this paper, we propose a recall-augmented COD architecture, namely RetroMem, which dynamically modulates camouflage pattern perception and inference by integrating relevant historical knowledge into the process. Specifically, RetroMem employs a two-stage training paradigm consisting of a learning stage and a recall stage to construct, update, and utilize memory representations effectively. During the learning stage, we design a dense multi-scale adapter (DMA) to improve the pretrained encoder's capability to capture rich multi-scale visual information with very few trainable parameters, thereby providing foundational inferences. In the recall stage, we propose a dynamic memory mechanism (DMM) and an inference pattern reconstruction (IPR). These components fully leverage the latent relationships between learned knowledge and current sample context to reconstruct the inference of camouflage patterns, thereby significantly improving the model's understanding of camouflage scenes. Extensive experiments on several widely used datasets demonstrate that our RetroMem significantly outperforms existing state-of-the-art methods.
Dimension-Free Decision Calibration for Nonlinear Loss Functions
Apr 22, 2025When model predictions inform downstream decision making, a natural question is under what conditions can the decision-makers simply respond to the predictions as if they were the true outcomes. Calibration suffices to guarantee that simple best-response to predictions is optimal. However, calibration for high-dimensional prediction outcome spaces requires exponential computational and statistical complexity. The recent relaxation known as decision calibration ensures the optimality of the simple best-response rule while requiring only polynomial sample complexity in the dimension of outcomes. However, known results on calibration and decision calibration crucially rely on linear loss functions for establishing best-response optimality. A natural approach to handle nonlinear losses is to map outcomes $y$ into a feature space $\phi(y)$ of dimension $m$, then approximate losses with linear functions of $\phi(y)$. Unfortunately, even simple classes of nonlinear functions can demand exponentially large or infinite feature dimensions $m$. A key open problem is whether it is possible to achieve decision calibration with sample complexity independent of~$m$. We begin with a negative result: even verifying decision calibration under standard deterministic best response inherently requires sample complexity polynomial in~$m$. Motivated by this lower bound, we investigate a smooth version of decision calibration in which decision-makers follow a smooth best-response. This smooth relaxation enables dimension-free decision calibration algorithms. We introduce algorithms that, given $\mathrm{poly}(|A|,1/\epsilon)$ samples and any initial predictor~$p$, can efficiently post-process it to satisfy decision calibration without worsening accuracy. Our algorithms apply broadly to function classes that can be well-approximated by bounded-norm functions in (possibly infinite-dimensional) separable RKHS.
Kandinsky Conformal Prediction: Beyond Class- and Covariate-Conditional Coverage
Feb 24, 2025


Conformal prediction is a powerful distribution-free framework for constructing prediction sets with coverage guarantees. Classical methods, such as split conformal prediction, provide marginal coverage, ensuring that the prediction set contains the label of a random test point with a target probability. However, these guarantees may not hold uniformly across different subpopulations, leading to disparities in coverage. Prior work has explored coverage guarantees conditioned on events related to the covariates and label of the test point. We present Kandinsky conformal prediction, a framework that significantly expands the scope of conditional coverage guarantees. In contrast to Mondrian conformal prediction, which restricts its coverage guarantees to disjoint groups -- reminiscent of the rigid, structured grids of Piet Mondrian's art -- our framework flexibly handles overlapping and fractional group memberships defined jointly on covariates and labels, reflecting the layered, intersecting forms in Wassily Kandinsky's compositions. Our algorithm unifies and extends existing methods, encompassing covariate-based group conditional, class conditional, and Mondrian conformal prediction as special cases, while achieving a minimax-optimal high-probability conditional coverage bound. Finally, we demonstrate the practicality of our approach through empirical evaluation on real-world datasets.
Goedel-Prover: A Frontier Model for Open-Source Automated Theorem Proving
Feb 11, 2025We introduce Goedel-Prover, an open-source large language model (LLM) that achieves the state-of-the-art (SOTA) performance in automated formal proof generation for mathematical problems. The key challenge in this field is the scarcity of formalized math statements and proofs, which we tackle in the following ways. We train statement formalizers to translate the natural language math problems from Numina into formal language (Lean 4), creating a dataset of 1.64 million formal statements. LLMs are used to check that the formal statements accurately preserve the content of the original natural language problems. We then iteratively build a large dataset of formal proofs by training a series of provers. Each prover succeeds in proving many statements that the previous ones could not, and these new proofs are added to the training set for the next prover. The final prover outperforms all existing open-source models in whole-proof generation. On the miniF2F benchmark, it achieves a 57.6% success rate (Pass@32), exceeding the previous best open-source model by 7.6%. On PutnamBench, Goedel-Prover successfully solves 7 problems (Pass@512), ranking first on the leaderboard. Furthermore, it generates 29.7K formal proofs for Lean Workbook problems, nearly doubling the 15.7K produced by earlier works.
CGCOD: Class-Guided Camouflaged Object Detection
Dec 25, 2024


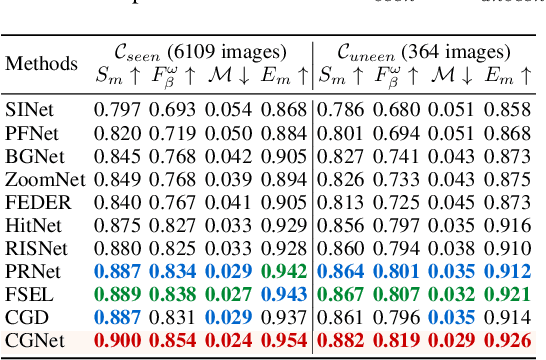
Camouflaged Object Detection (COD) is designed to identify objects that blend seamlessly with their surroundings. Due to the complexity of camouflaged objects (such as shape, color, and texture), their semantic cues are often blurred or completely lost, posing a significant challenge for COD. Existing COD methods often rely on visual features, which are not stable enough in changeable camouflage environments. This instability leads to false positives and false negatives, resulting in incomplete or inaccurate segmentation results. In this paper, to solve this problem, we propose a new task, Class-Guided Camouflaged Object Detection (CG-COD), which extends the traditional COD task by introducing object class knowledge, significantly improving the robustness and segmentation accuracy of the model in complex environments. Toward this end, we construct a dataset, CamoClass, containing the camouflaged objects in the real scenes and their corresponding class annotation. Based on this, we propose a multi-stage framework CGNet which consists of a plug-and-play class prompt generator and a class-guided detector. Under the guidance of textual information, CGNet enables efficient segmentation. It is worth emphasizing that for the first time, we extend the object class annotations on existing COD benchmark datasets, and introduce a flexible framework to improve the performance of the existing COD model under text guidance.
Benign Overfitting in Out-of-Distribution Generalization of Linear Models
Dec 19, 2024
Benign overfitting refers to the phenomenon where an over-parameterized model fits the training data perfectly, including noise in the data, but still generalizes well to the unseen test data. While prior work provides some theoretical understanding of this phenomenon under the in-distribution setup, modern machine learning often operates in a more challenging Out-of-Distribution (OOD) regime, where the target (test) distribution can be rather different from the source (training) distribution. In this work, we take an initial step towards understanding benign overfitting in the OOD regime by focusing on the basic setup of over-parameterized linear models under covariate shift. We provide non-asymptotic guarantees proving that benign overfitting occurs in standard ridge regression, even under the OOD regime when the target covariance satisfies certain structural conditions. We identify several vital quantities relating to source and target covariance, which govern the performance of OOD generalization. Our result is sharp, which provably recovers prior in-distribution benign overfitting guarantee [Tsigler and Bartlett, 2023], as well as under-parameterized OOD guarantee [Ge et al., 2024] when specializing to each setup. Moreover, we also present theoretical results for a more general family of target covariance matrix, where standard ridge regression only achieves a slow statistical rate of $O(1/\sqrt{n})$ for the excess risk, while Principal Component Regression (PCR) is guaranteed to achieve the fast rate $O(1/n)$, where $n$ is the number of samples.